
0. Dataset
# 데이터 불러오기. y값은 이미 범주형으로 되어있음.
import pandas as pd
import numpy as np
dat_wine=pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/'
'wine/wine.data',header=None)
dat_wine.head()
dat_wine.columns = ['class label', 'alchohol', 'malic acid', 'ash',
'alcalinity of ash', 'magnesium', 'total phenols',
'flavanoids', 'nonflavanoid phenols',
'proanthocyanins', 'color intensity', 'hue',
'OD208', 'proline'] # Column names
print('class label:', np.unique(dat_wine['class label'])) # Class 출력
dat_wine.head()
# 전체 data를 training set과 test set으로 split
from sklearn.model_selection import train_test_split
X, y = dat_wine.iloc[:,1:].values, dat_wine.iloc[:,0].values
X_train, X_test, y_train,y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
1. Data Normalization
# 표준화
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.transform(X_test)
2. Inference
# Logistic Regression with L2 or L1 Regularization
from sklearn.linear_model import LogisticRegression
lr2_10 = LogisticRegression(penalty='l2', C=10.0, solver='saga') # L2 with C(=1/λ)=10
lr2_1 = LogisticRegression(penalty='l2', C=1.0, solver='saga') # L2 with C(=1/λ)=1
lr2_0_1 = LogisticRegression(penalty='l2', C=0.1, solver='saga') # L2 with C(=1/λ)=0.1
lr1_10 = LogisticRegression(penalty='l1', C=10.0, solver='saga') # L1 with C(=1/λ)=10
lr1_1 = LogisticRegression(penalty='l1', C=1.0, solver='saga') # L1 with C(=1/λ)=1
lr1_0_1 = LogisticRegression(penalty='l1', C=0.1, solver='saga') # L1 with C(=1/λ)=0.1
3. Score
# 규제화 방법(L2 or L1)과 규제강도(λ)를 바꿔가며 accuracy score 계산
lr2_10.fit(X_train_std, y_train)
print('Training accuracy with L2 and λ=0.1:', lr2_10.score(X_train_std, y_train))
print('Test accuracy with L2 and λ=0.1:', lr2_10.score(X_test_std, y_test))
lr2_1.fit(X_train_std, y_train) # warning..
print('Training accuracy with L2 and λ=1:', lr2_1.score(X_train_std, y_train))
print('Test accuracy with L2 and λ=1:', lr2_1.score(X_test_std, y_test))
lr2_0_1.fit(X_train_std, y_train)
print('Training accuracy with L2 and λ=10:', lr2_0_1.score(X_train_std, y_train))
print('Test accuracy with L2 and λ=10:', lr2_0_1.score(X_test_std, y_test))
lr1_10.fit(X_train_std, y_train)
print('Training accuracy with L1 and λ=0.1:', lr1_10.score(X_train_std, y_train))
print('Test accuracy with L1 and λ=0.1:', lr1_10.score(X_test_std, y_test))
lr1_1.fit(X_train_std, y_train)
print('Training accuracy with L1 and λ=1:', lr1_1.score(X_train_std, y_train))
print('Test accuracy with L1 and λ=1:', lr1_1.score(X_test_std, y_test))
lr1_0_1.fit(X_train_std, y_train)
print('Training accuracy with L1 and λ=10:', lr1_0_1.score(X_train_std, y_train))
print('Test accuracy with L1 and λ=10:', lr1_0_1.score(X_test_std, y_test))
# L2 규제의 규제강도(C=1/λ)를 바꿔가며 계수 추정치 관찰
print(lr2_10.intercept_)
print(lr2_1.intercept_)
print(lr2_0_1.intercept_)
print(lr2_10.coef_)
print(lr2_1.coef_)
print(lr2_0_1.coef_)
# L1 규제의 규제강도(C=1/λ)를 바꿔가며 계수 추정치 관찰
print(lr1_10.intercept_)
print(lr1_1.intercept_)
print(lr1_0_1.intercept_)
print(lr1_10.coef_)
print(lr1_1.coef_)
print(lr1_0_1.coef_)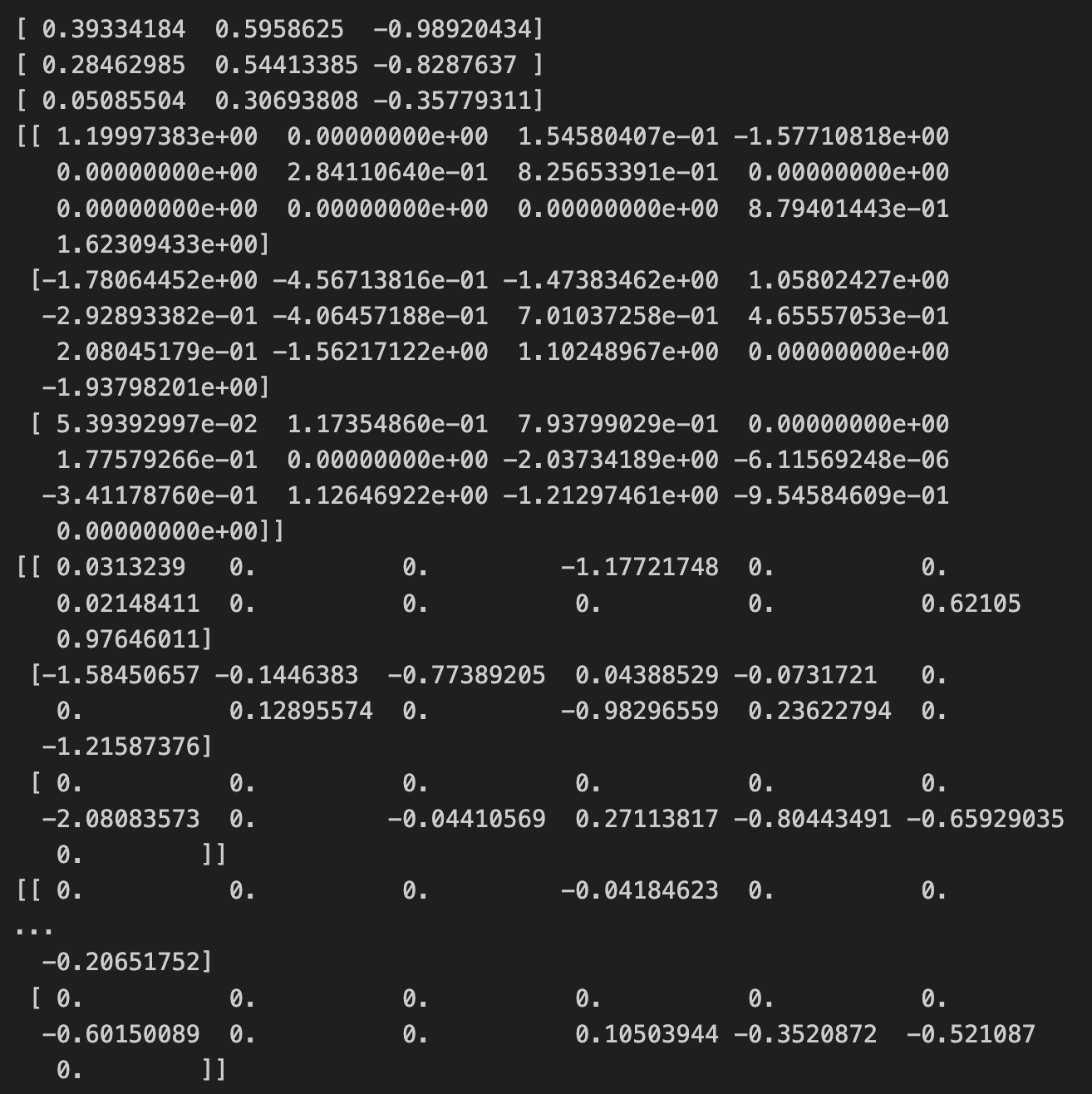
'Computer Science > Machine Learning' 카테고리의 다른 글
| Linear Regression : Logistic Regression [수면시간에 따른 우울증 예측] (6) (0) | 2024.03.24 |
|---|---|
| Linear Regression : Logistic Regression [은하계 종류 예측] (5) (0) | 2024.03.24 |
| Linear Regression : Logistic Regression [Iris] (3) (0) | 2024.03.24 |
| Linear Regression : Logistic Regression (2) (1) | 2024.03.24 |
| Linear Regression : Multi Linear Regression (1) (0) | 2024.03.23 |


