
1. VQA: Visual Question Answering (2015)
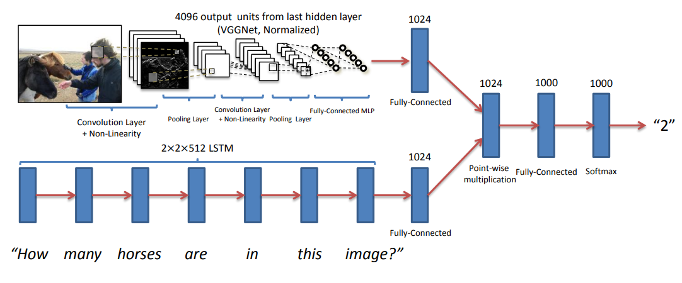
- Image는 CNN encoder, Question은 LSTM encoder 거친 vector를 합치는 방식
- Pretrained VGG 16, LSTM 사용
2. Hierarchical Question-Image Co-Attention for Visual Question Answering (2016)
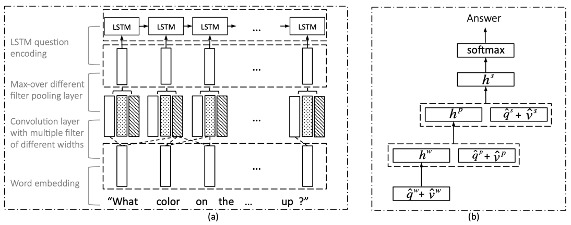
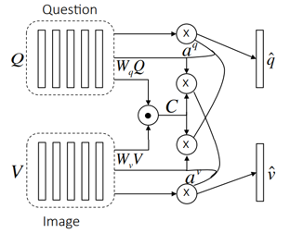
- Image와 Question 사이의 관계를 설명하기 위해 Attention 사용
- Image feature 추출은 거의 변한 것이 없음
- Question에서 더 semantic한 정보를 뽑기 위해 LSTM 구조를 hierarchical하게 변경
- Image와 Question을 attention해서 unified context vector 추출
3. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering (2017)
- 원하는 object만 추출한 일부 이미지 영역과 Question을 attention (전체 이미지를 사용하는 방식을 Top-Down 방식, object detection 후 일부분만 사용하는 방식을 Bottom-Up 방식)

- Bottom-Up 방식(Faster-RCNN)을 이용하여 한 Image에 대해 여러 개의 object 후보군이 k개 생김 (Image features: k*2048)
- LSTM → GRU
- ResNet 모델(위쪽)은 언어 선입견으로 인해 변기가 있는 것으로 착각하여 품질이 좋지 않은 캡션을 생성
- 업다운 모델(아래)은 문맥에서 벗어난 소파를 명확하게 식별하여 올바른 캡션을 생성하는 동시에 더 해석하기 쉬운 주의 가중치를 제공
- A, man, sitting이 적힌 영역을 보면 매우 작음
- 전체 이미지에서 모델이 "A"에 해당하는 부분은 저 조그만 pixel, "man"에 해당하는 부분도 저 조그만 pixel 영역으로 생각
- Semantic한 information을 잘 학습한 것이 아니라, 단어들에 대한 이미지 영역이 매우 좁은 pixel에 모여 있음
- Bottom-Up으로 특정 이미지 영역을 정해주고, attention을 적용하면 훨씬 semantic하게 잘 학습됨을 알 수 있음
- "A"와 "man"에 해당하는 면적이 꽤나 넓어졌고 의미적으로도 유사
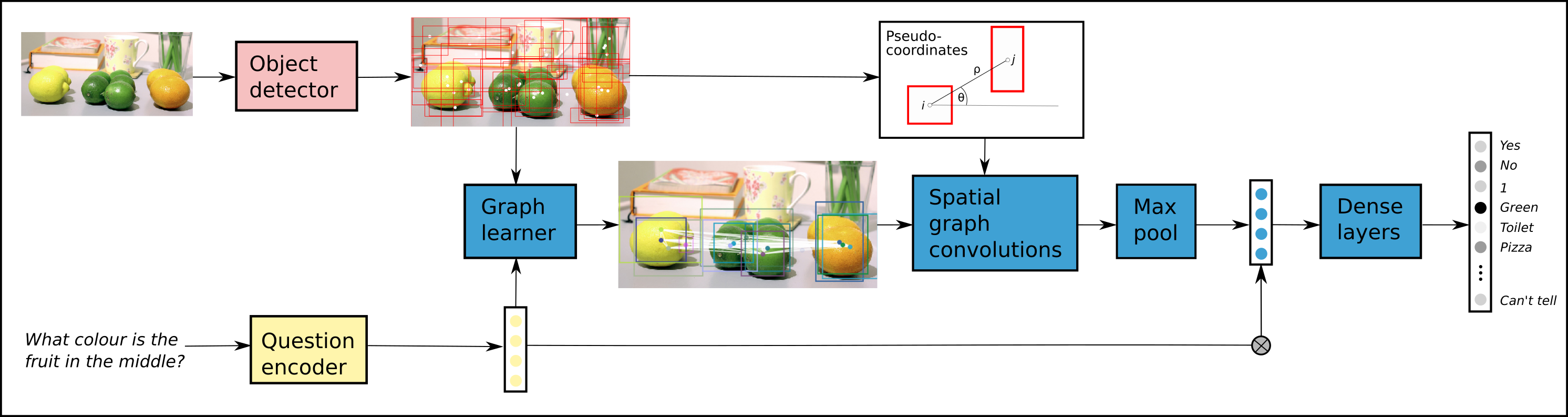
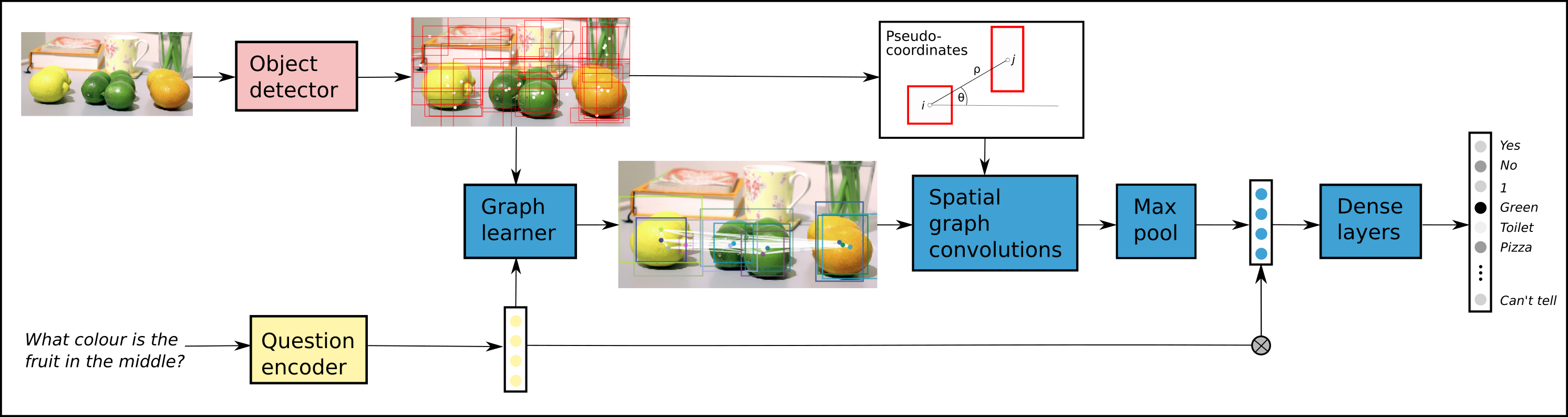
4. Learning Conditioned Graph Structures for Interpretable Visual Question Answering (2018)
GitHub - aimbrain/vqa-project: Code for our paper: Learning Conditioned Graph Structures for Interpretable Visual Question Answe
Code for our paper: Learning Conditioned Graph Structures for Interpretable Visual Question Answering - aimbrain/vqa-project
github.com

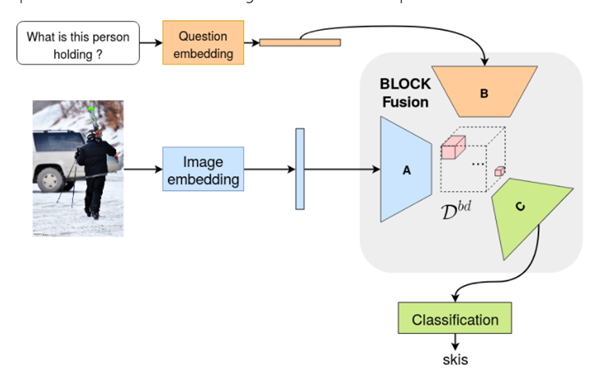
5. BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection (2019)
GitHub - Cadene/block.bootstrap.pytorch: BLOCK (AAAI 2019), with a multimodal fusion library for deep learning models
BLOCK (AAAI 2019), with a multimodal fusion library for deep learning models - Cadene/block.bootstrap.pytorch
github.com
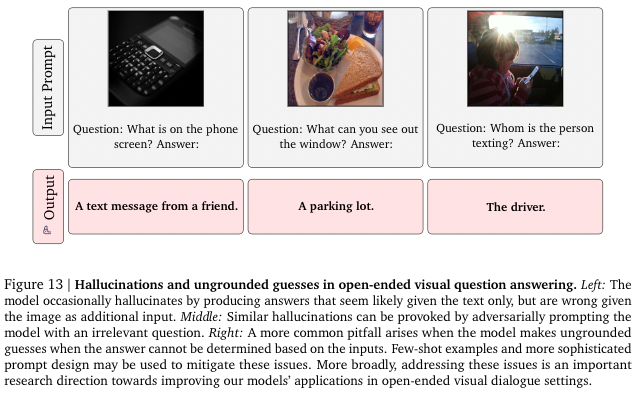
6. Flamingo: a Visual Language Modelfor Few-Shot Learning (2022)
[논문 리뷰] 🦩 Flamingo: a Visual Language Model for Few-Shot Learning - 1. 핵심 특징 및 예제 설명
구글 딥마인드에서 발표한 Visual Language Model로, 이미지와 텍스트로 구성된 input을 받아 텍스트 output을 생성합니다. 다양한 Vision-Language task에서 적은 수의 example로 학습해 fine-tuned model의 SotA에 가
cocoa-t.tistory.com
GitHub - mlfoundations/open_flamingo: An open-source framework for training large multimodal models.
An open-source framework for training large multimodal models. - mlfoundations/open_flamingo
github.com
- Language-vision에 대해 supervision과 contrastive learning으로 매우 좋은 성능을 보인 CLIP을 사용한 모델
- Few-shot으로 몇 가지 example만 보여주면 그에 따른 답을 만들어주는 모델이다. VQA 뿐만 아니라 chat-bot 기능, Image captioning 등 다양한 분야에 사용

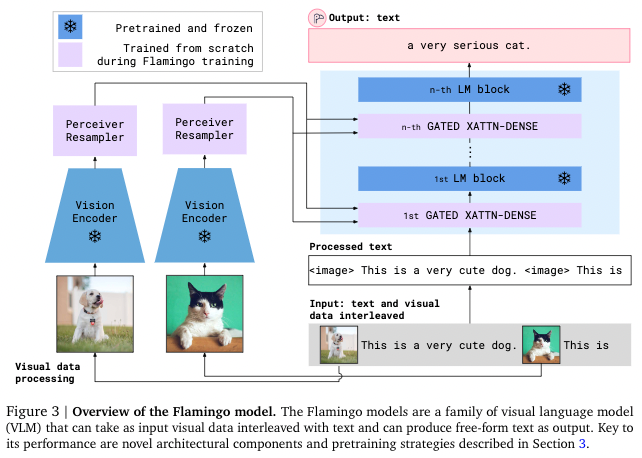
- Flamingo 모델은 CLIP 모델의 vision encoder(ViT), text encoder를 frozen하여 그대로 사용
- Image-text pair를 서로 attention하여 학습하기 위해 두 가지의 새로운 구조를 도입
(1) Perceiver Resampler
Vision encoder로 얻은 feature들을 고정된 작은 사이즈의 visual token으로 mapping하는 역할을 한다. Visual token의 출력 size가 작을수록 vision-text cross attention의 계산량을 줄일 수 있어, 긴 비디오를 처리할 때 매우 유용하게 사용된다.
(Bottom-Up 구조로 attention 계산량을 줄이는 아이디어는 동일)
(2) Gated Cross Attention layers
Visual token과 text를 attention하는 layer이다. 이때 Attention의 key, value 값은 vision feature에서 얻고, query를 language feature에서 얻는다. 따라서 이 layer에서는 vision과 language 정보를 통합해 LM block이 다음 token을 예측하는 task를 수행하는데 도움을 준다.
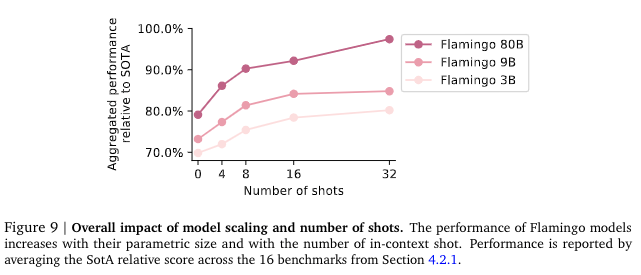
Flamingo는 parametric size가 클수록 성능이 좋아지고, in-context shot (위에서 언급했던 few-shot의 개수!) 숫자가 증가할수록 성능이 좋아졌다. 사실 parameter size가 증가한다고 무작정 모델 정확도가 좋아지기 어렵다. 하지만 Flamingo는 CLIP을 frozen하고 몇 가지 layer만 추가한 모델이기에 CLIP과 유사하게 parametric size가 클수록 좋은 성능을 보이는 경향을 보이고 있다.


