
Flamingo: a Visual Language Model for Few-Shot Learning
Building models that can be rapidly adapted to novel tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. We propo
arxiv.org
0. Abstract
Flamingo의 주요 아키텍쳐 발전
(1) 사전 학습된 강력한 시각 전용 모델과 언어 전용 모델을 연결
(2) 임의로 인터리빙(둘 이상의 것이 번갈아 가며 섞인)된 시각 및 텍스트 데이터의 시퀀스를 처리
(3) 이미지 또는 비디오를 입력으로 원활하게 수집
이러한 유연성으로 Flamingo 모델은 large-scale의 텍스트와 이미지들을 포함하는 멀티모달 웹 코퍼스들로 훈련될 수 있으며, 이는 상황에 맞는 few-shot 학습 가능성을 부여하는 핵심적인 역할을 한다.
여기에는 모델이 대답해야 하는 질문이 제시되는 시각적 질문 답변과 같은 개방형 작업, 장면이나 이벤트를 설명하는 능력을 평가하는 캡션 작업, 객관식 시각적 질문 답변과 같은 폐쇄형 작업이 포함하는 등 모델에 대한 철저한 평가를 수행한다.
단일 Flamingo 모델은 작업별 예시를 모델에 제시하는(few-shot) 몇 번의 학습만으로 SOTA를 달성했다. 수많은 벤치마크에서 Flamingo는 수천 배 더 많은 작업별 데이터로 미세 조정된 모델보다 뛰어난 성능을 보였다.
1. Introduction

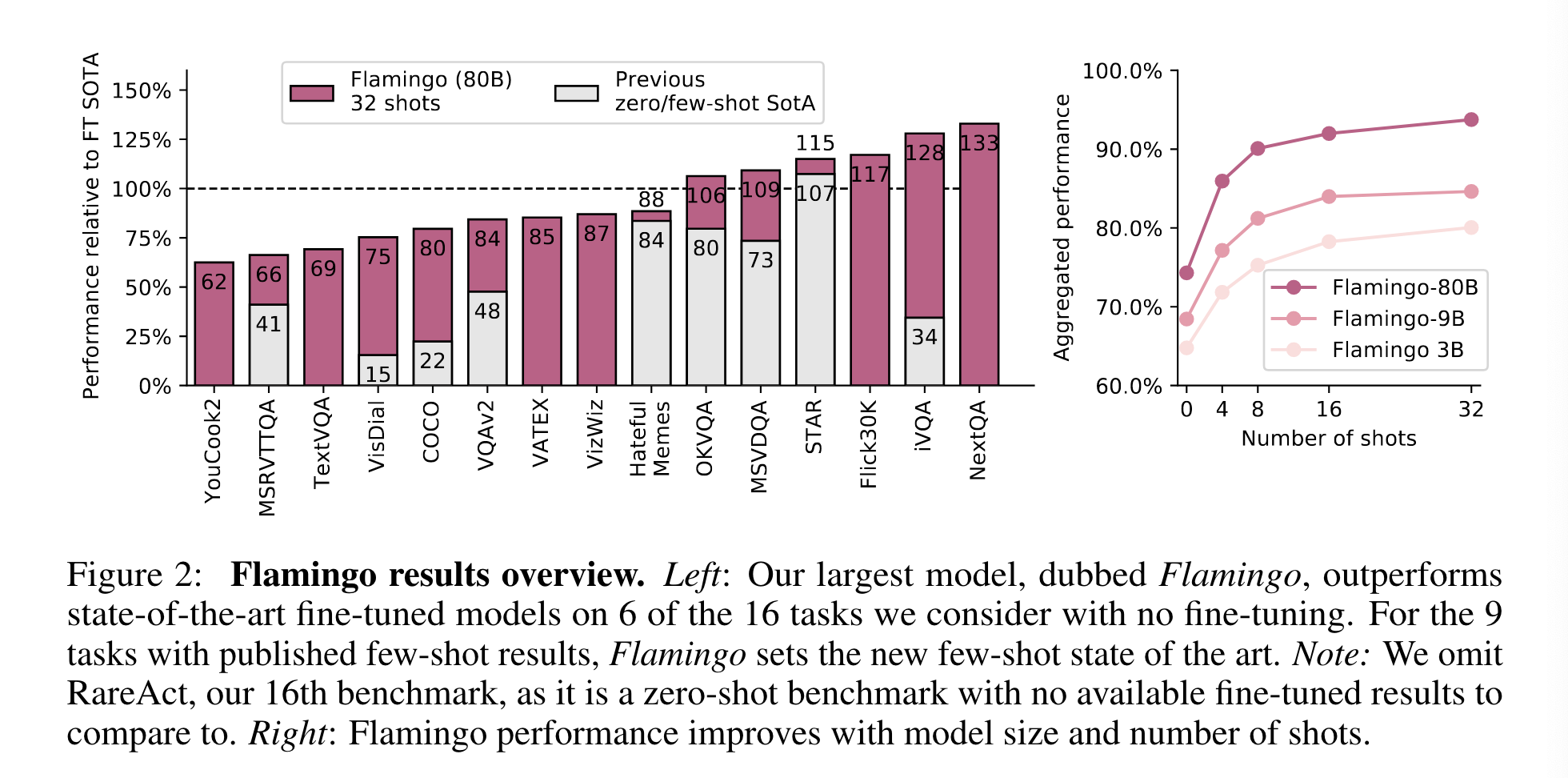
기존에는 대량의 supervised 데이터를 pretrain한 후, 필요한 task에 맞춰 모델을 fine-tuning한다. 그러나 성공적인 fine-tuning을 위해서는 수천 개의 주석이 달린 데이터 포인트가 필요하고, 또한 task별 하이퍼파라미터를 세심하게 조정해야 하고, 자원도 많이 소모된다.
최근에는 contrastive objective로 훈련된 multimodal VLM(Visual Language Model)을 사용하면, 미세 조정 없이도 새로운 task에 zero-shot으로 사용할 수 있다. 그러나 이러한 모델은 단순히 텍스트와 이미지 간의 유사도 점수를 제공하기 때문에 사전에 한정된 결과 집합이 제공되는 분류와 같은 제한된 사용 사례만 처리할 수 있다. 결정적으로 언어를 생성하는 기능이 부족하기 때문에, 개방형 작업(캡션이나 시각적 질문에 대한 답변)에는 적합하지 않다.
Flamingo는 몇 가지 입력/출력 예제만 제시하면 다양한 개방형 시각 및 언어 과제에 대해 few-shot learning의 SOTA를 달성한 시각 언어 모델(VLM)이다.
이를 달성하기 위해 Flamingo는 좋은 few-shot 학습자인 LLM에 대한 최근 연구에서 영감을 얻었다. Flamingo는 이미지 및/또는 동영상과 interleaving된 일련의 텍스트 토큰을 수집하여, 텍스트를 출력으로 생성할 수 있는 시각적 조건부 자동 회귀 텍스트 생성 모델(visually-conditioned autoregressive text generation model)이다.
시각적 장면을 인식할 수 있는 vision 모델과 기본적인 형태의 추론을 수행하는 LLM이라는 두 가지 상호 보완적인 pre-trained 및 frozen 모델을 활용한다. 이 모델들 사이에 새로운 아키텍처 구성 요소가 추가되어 pre-training 중에 축적된 결과를 보존하는 방식으로 연결된다. 크고 다양한 수의 시각적 입력 특징이 주어질 때 이미지/비디오당 적은 수의 고정된 시각적 토큰을 생성할 수 있는 Perceiver 기반 아키텍처 덕분에 고해상도 이미지나 비디오를 수집할 수 있다.
또한 LLM과 같이, 웹에서만 제공되는 대규모 멀티모달 데이터를 엄선하여 혼합하여 학습한다. 이 훈련이 끝나면 플라밍고 모델은 작업별 튜닝 없이 few-shot learning을 통해 직접 사용할 수 있다.
아키텍처 혁신 덕분에 플라밍고 모델은 임의로 interleaving된 시각 데이터와 텍스트를 입력으로 효율적으로 받아들이고 개방형 방식으로 텍스트를 생성할 수 있습니다. Few-shot learning을 통해 Flamingo 모델이 다양한 작업에 어떻게 적용될 수 있는지, 설계 결정이나 접근 방식의 하이퍼파라미터를 검증하는 데 사용되지 않은 대규모의 heldout benchmark로 정량적으로 평가한다. 16개 과제 중 6개 과제에서 Flamingo는 32개의 과제별 예제만 사용했음에도 불구하고 현재 최신 기술보다 약 1000배 적은 과제별 학습 데이터로 미세 조정된 최신 기술보다 뛰어난 성능을 발휘한다. 또한 더 많은 주석으로, Flamingo를 fine-tuning하며 5개의 추가 벤치마크(VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes)에서 SOTA를 달성할 수 있었다.
2. Approach
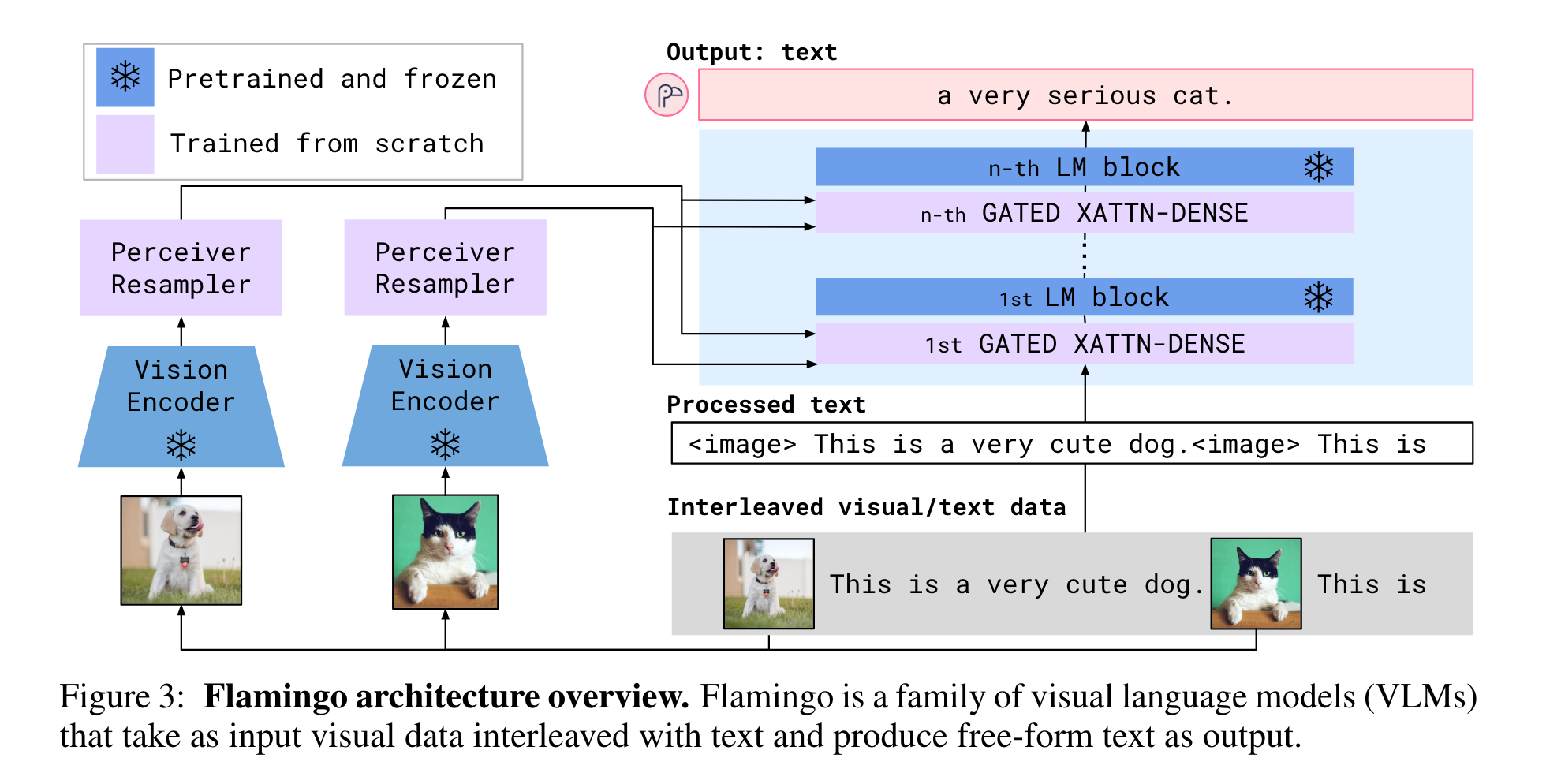
Flamingo는 사전학습된 비전과 언어 모델을 활용하고, 이를 효과적으로 연결한다.
(1) 인식기 리샘플러(Perceiver Resampler)는 비전 인코더(이미지 또는 비디오에서 얻은)로부터 시공간적 특징을 받아 고정된 수의 시각적 토큰을 출력한다.
(2) 이러한 시각 토큰은 미리 학습된 LM 레이어 사이에 삽입된 새로 초기화된 cross-attention layer를 사용하여 고정된 LM을 컨디셔닝하는 데 사용된다.
이러한 새로운 레이어는 LM이 다음 토큰 예측 작업을 위해 시각적 정보를 통합할 수 있는 표현적인 방법을 제공합니다.
Flamingo는 인터리브된 이미지와 동영상 𝑥에 조건부 텍스트 𝑦의 가능성을 모델링한다.
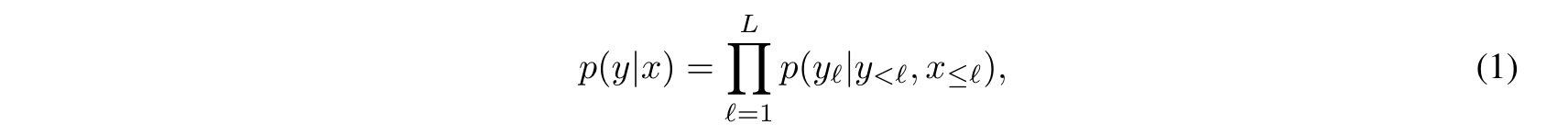
여기서 $𝑦_ℓ$는 입력 텍스트의 $ℓ$번째 언어 토큰, $𝑦<ℓ$는 앞의 토큰 집합, $𝑥≤ℓ$는 인터리브 시퀀스에서 토큰 $𝑦_ℓ$ 앞의 이미지/비디오 집합, $𝑝$는 Flamingo 모델로 매개변수화된다. 인터리브 텍스트 및 시각적 시퀀스를 처리하는 기능을 사용하면 few-shot 텍스트 프롬프트가 있는 GPT-3과 유사하게 상황에 맞는 few-shot learning에 Flamingo 모델을 자연스럽게 사용할 수 있다. 이 모델은 다양한 데이터 세트의 혼합에 대해 학습된다.
2.1 Visual Processing and the Perceiver Resampler
Vison Encoder: from pixels to features
- Vision encoder model : Pre-train되고 freeze된 NFNet(Normalizer Free ResNet) F6를 썼다.
- Pre-training : 데이터셋의 이미지와 텍스트 쌍을 two-term contrastive loss를 사용해 사전학습시켰다.
- Input : 비디오 프레임은 1 FPS로 sampling되고, 각각 encoding되어 학습된 시간 임베딩이 추가되는 3D 시공간 그리드를 얻는다.
- Output : 추출된 feature들은 perceiver reasampler에 입력되기 전에 1D로 flatten 시킨다.
Perceiver Resampler: from varying-size large feature maps to few visual tokens
- Input : 다양한 수의 이미지 또는 비디오 feature를 입력으로 받아, 고정된 수의 visual output(64개)을 생성하여 vision-text cross-attention의 계산 복잡성을 줄인다.
- Output : (Perceiver 및 DETR과 유사) 미리 정의된 수의 잠재 입력 쿼리를 학습하여 transformer에 공급하고, 시각적 특징에 cross-attention한다.
2.2 Conditioning frozen language models on visual representations
'Pretrained and frozen text-only LM block'들과 'perceiver resampler의 시각적 출력으로부터 cross-attention해서 나온 scratch로 부터 학습된 block'들이 교차 배열(Figure 3 참고)되어 있다.
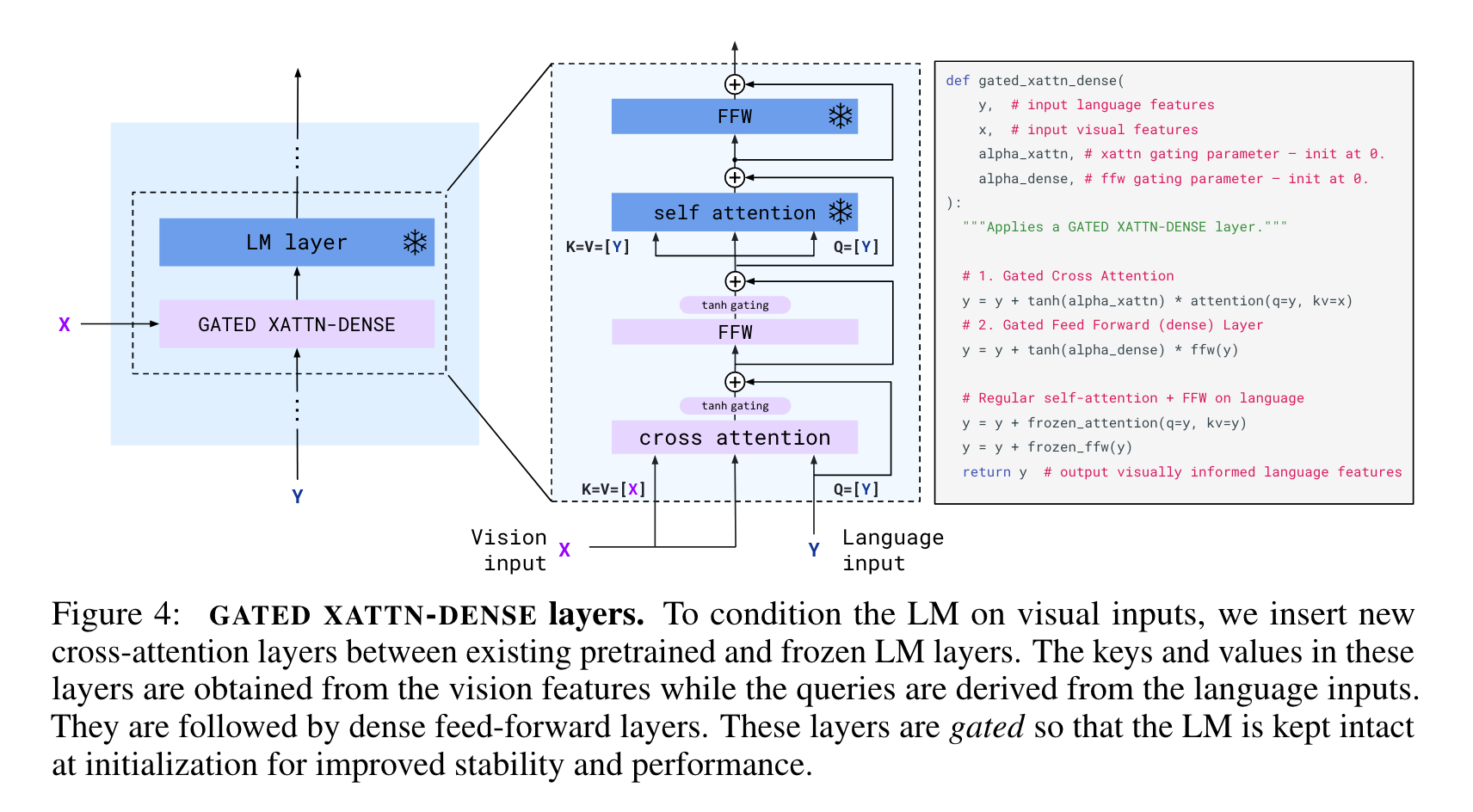
Interleaving new GATED XATTN-DENSE layers within a frozen pretrained LM
Pre-train된 LM 블록을 freeze하고, 처음부터 학습된 원래 레이어 사이에 gated cross-attention dense block을 삽입한다.
초기화 시 조건부 모델이 원래 언어 모델과 동일한 결과를 산출하도록 하기 위해 탄 게이팅 메커니즘을 사용한다.
이는 새로 추가된 계층의 출력에 tanh(𝛼)를 곱한 다음 잔여 연결의 입력 표현에 추가하는 방식으로, 여기서 𝛼는 0으로 초기화된 계층별 학습 가능 스칼라입니다.
LM Layer
Vision input에 따라 LM을 조건화하기 위해 기존의 pre-train된 LM 레이어와 고정된 LM 레이어 사이에 새로운 self-attention 레이어를 삽입한다.
이 레이어의 key와 value은 vision feature(Perceiver Resampler로부터의)에서 가져오고 query는 language input에서 가져온다. 그 다음에는 FFW 레이어가 이어진다. 이러한 계층은 안정성과 성능을 개선하기 위해 초기화 시, output은 사전 학습된 LM의 출력과 일치하여 학습 안정성과 최종 성능이 향상되도록 게이트 처리된다.
Varying model sizes
- 1.4B(Flamingo-3B), 7B(Flamingo-9B), 70B(Flamingo-80B) 파라미터 친칠라 모델(컴퓨팅 최적화 모델)을 기반으로 세 가지 모델 크기에 걸쳐 실험을 수행
- 해당 논문의 Flamingo는 Flamingo-80B로 통일
- 고정된 LM과 훈련 가능한 비전 텍스트 GATED XATTN-DENSE 모듈의 파라미터 수를 늘리면서도 여러 모델에 걸쳐 고정된 크기의 비전 인코더와 훈련 가능한 퍼시버 리샘플러를 유지(전체 모델 크기에 비해 작음)
2.3 Multi-visual input support: per-image/video attention masking
- Equation (1)의 image-causal modelling은 전체 text-to-image cross-attention matrix를 마스킹하여 모델이 각 텍스트 토큰에서 볼 수 있는 시각적 토큰을 제한함으로써 얻을 수 있다.
- 주어진 텍스트 토큰에서 모델은 이전의 모든 이미지가 아니라 interleave한 시퀀스에서 바로 앞에 나타난 이미지의 시각적 토큰에 self-attention한다.
- 모델은 한 번에 하나의 이미지에만 attention을 수행하지만, 이전의 모든 이미지에 대한 의존성은 LM의 self-attention을 통해 유지된다.
- 이러한 단일 이미지 cross-attention 방식은 훈련 중에 사용되는 이미지 수에 관계없이 모델이 어떤 수의 시각적 입력에도 원활하게 일반화할 수 있게 해준다.
- Interleave한 데이터셋으로 훈련할 때는 시퀀스당 최대 5개의 이미지만 사용하지만, 평가 중에는 최대 32쌍(샷)의 이미지/비디오와 해당 텍스트로 구성된 시퀀스를 활용할 수 있다.
- 이 방식이 모델이 모든 이전 이미지를 직접 cross-attention하는 것보다 더 효과적이다.
2.4 Training on a mixture of vision and language datasets
M3W(MultiModal MassiveWeb): Interleaved image and text dataset
(1) 약 4,300만 개의 웹페이지의 HTML에서 텍스트와 이미지를 모두 추출하여 DOM(문서 객체 모델)의 텍스트와 이미지 요소의 상대적인 위치를 기반으로 텍스트에 대한 이미지의 위치를 결정
(2) 페이지의 이미지 위치에 일반 텍스트로 <image> 태그를 삽입하고, 이미지 앞과 문서 끝에 특수 <EOC>(청크의 끝) 토큰(어휘에 추가되어 학습됨)을 삽입하여 예제를 구성
(3) 각 문서에서 𝐿 = 256개 토큰의 무작위 시퀀스를 샘플링하고 샘플링된 시퀀스에 포함된 첫 번째 𝑁 = 5개 이미지까지 가져옴
(4) 그 이후의 이미지는 계산을 절약하기 위해 버림
Pairs of image/video and text
- 이미지와 텍스트 쌍을 위해 먼저 18억 개의 이미지와 대체 텍스트로 구성된 ALIGN 데이터셋을 활용
- 이 데이터셋를 보완하기 위해 더 나은 품질과 긴 설명을 목표로 하는 이미지 및 텍스트 쌍의 자체 데이터셋(3억 1,200만 개의 이미지와 텍스트 쌍으로 구성된 LTIP(긴 텍스트 및 이미지 쌍))를 수집
- 비슷한 데이터셋을 수집하지만 정지 이미지 대신 동영상(VTP(비디오 및 텍스트 쌍)는 2700만 개의 짧은 비디오(평균 약 22초)가 문장 설명과 쌍을 이루는 데이터)으로 수집
- 각 훈련 캡션에 <image>를 앞에 붙이고 <EOC>를 추가하여 페어링된 데이터 세트의 구문을 M3W의 구문과 일치시킴
Multi-objective training and optimisation strategy
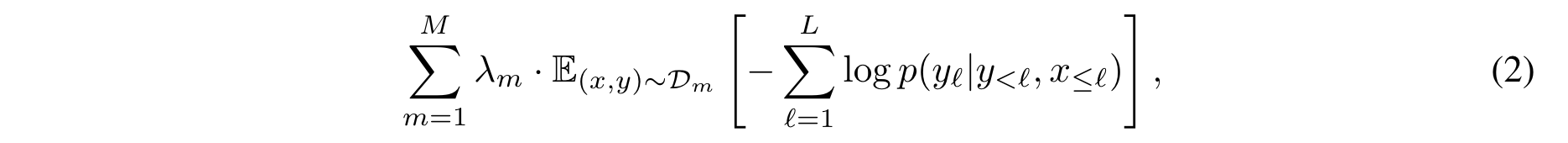
- 시각적 입력이 주어졌을 때 데이터셋별로 예상되는 텍스트의 음수 로그 가능성의 가중치 합을 최소화하여 모델을 훈련
- 𝒟_𝑚와 𝜆_𝑚는 각각 𝑚번째 데이터셋과 그 가중치로, 데이터셋별 가중치 𝜆_𝑚를 조정하는 것이 성능의 핵심
- 모든 데이터셋에 대해 그래디언트를 누적하는 것이 "round-robin" 접근 방식보다 성능이 우수
2.5 Task adaptation with few-shot in-context learning
- (이미지, 텍스트) 또는 (비디오, 텍스트) 형태의 지원 예제 쌍과 쿼리 시각 입력을 interleave하여 프롬프트를 구축하는 in-context learning을 사용하여 새로운 작업에 빠르게 적응하는 모델의 능력을 평가
- 해독을 위해 빔 검색을 사용하여 개방형 평가를 수행하고, 모델의 로그 가능성을 사용하여 각 가능한 답변에 점수를 매기는 폐쇄형 평가를 수행
- 모델에 해당 이미지 없이 텍스트만 있는 두 개의 예제를 제시하여 zero-shot generalization을 탐색
3. Experiments
3.1 Few-shot learning on vision-language tasks

Few-shot results
Flamingo는 이전의 모든 zero-shot이나 few-shot 방법론과 16개의 벤치마크에서 SOTA를 달성했다.
Scaling with respect to parameters and shots
Flamingo는 M3W에서 5개의 이미지로만 제한된 시퀀스로 훈련되었음에도 불구하고, 추론 중에 최대 32개의 이미지 또는 비디오를 활용할 수 있다.
3.2 Fine-tuning Flamingo as a pretrained vision-language model
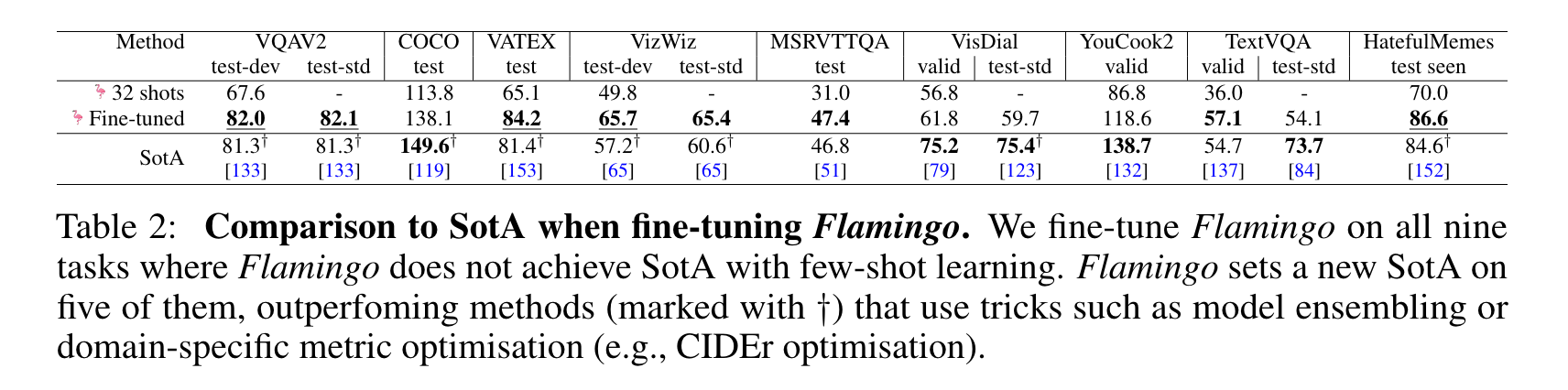
더 높은 입력 해상도를 수용하기 위해 vision backbone을 추가로 unfreeze하여 learning rate가 적은 짧은 scheduler로 모델을 미세 조정한다. 이전에 제시했던 상황별 few-shot learning 결과보다 결과를 개선하여 5개의 데이터셋(VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes)에 대해 SOTA를 달성했다.
3.3 Ablation studies
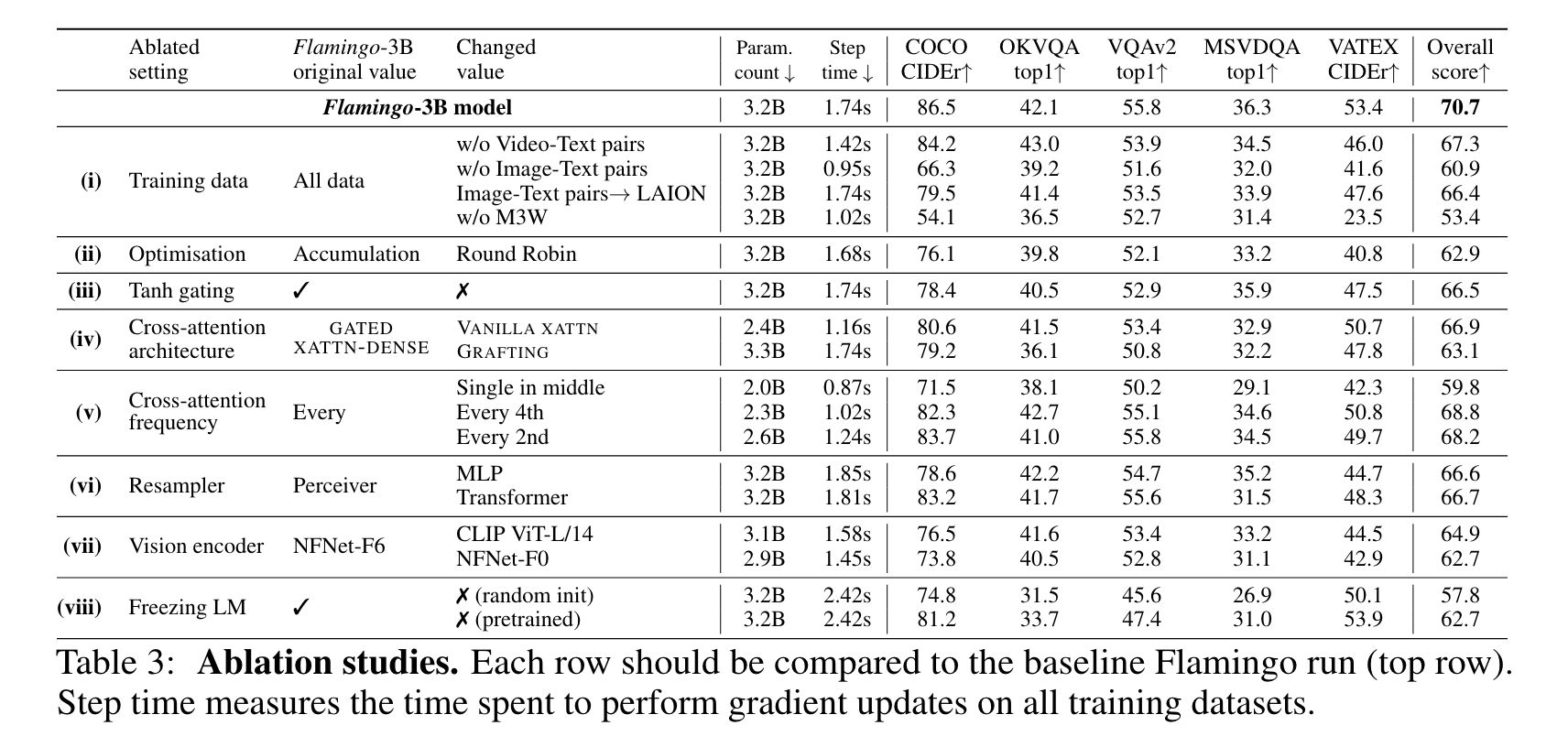
Importance of the training data mixture
- (i)을 보면, interleave된 이미지-텍스트 데이터 세트 M3W를 제거하면 성능이 17% 이상 감소하고, 기존의 페어링된 이미지-텍스트 쌍을 제거할 때도 성능이 9.8% 감소하는 것으로 나타나, 다양한 유형의 데이터셋이 필요하다.
- 페어링된 비디오-텍스트 데이터세트를 제거하면 모든 비디오 작업의 성능에 부정적인 영향을 미친다.
- 이미지-텍스트 쌍(ITP)을 공개적으로 사용 가능한 LAION-400M 데이터 세트로 대체하면 성능이 약간 저하된다.
- (ii)에서는 round-robin 업데이트를 사용하는 것과 비교하여, gradient 누적 방법의 중요성을 보여준다.
Visual conditioning of frozen LM
- (iii)에서 cross-attention output을 freeze된 LM output에 병합할 때 0으로 초기화된 tanh의 사용을 제거하면 전체 점수가 4.2% 하락한다.
- 0으로 초기화된 tanh을 비활성화하면 훈련이 불안정해해진다.
- (iv)에서 다른 컨디셔닝 아키텍처를 비활성화한다.
바닐라 크로스 어텐션은 오리지널 트랜스포머 디코더의 바닐라 크로스 어텐션을 의미한다. GRAFTING 접근 방식에서는 추가 레이어를 삽입하지 않고 고정된 LM을 그대로 사용하고, 고정된 LM 출력을 취하는 인터리브된 self-attention 및 cross-attention 레이어 스택을 처음부터 학습한다. 전반적으로 GATED XATTN-DENSE 컨디셔닝 접근 방식이 가장 효과적이라는 것을 보여준다.
Compute/Memory vs. performance trade-offs
- (v)에서는 새로운 GATED XATTN-DENSE 블록을 추가하는 빈도를 줄여, 학습 가능한 파라미터의 수와 모델의 시간 복잡성을 줄였다. - - 네 번째 블록마다 삽입하면 학습 속도가 66% 빨라지는 반면 전체 점수는 1.9%만 감소한다.
- 하드웨어 제약 조건 하에서 추가된 레이어 수를 최대화하고 Flamingo-9B의 경우 4번째 레이어마다, Flamingo-80B의 경우 7번째 레이어마다 GATED XATTN-DENSE를 추가한다.
- (vi)에서 파라미터 예산이 주어졌을 때 퍼시버 리샘플러와 MLP 및 vanilla transforemr를 비교하는데, 둘 다 perceiver resampler보다 성능이 떨어지고 속도도 느리다.
Vision encoder
- (vii)에서는 contrastive learninng으로 사전 학습된 NFNet-F6 비전 인코더와 224 해상도로 학습된 공개적으로 사용 가능한 CLIP ViT-L/14 모델을 비교한다.
- NFNet-F6는 CLIP ViT-L/14에 비해 +5.8%, 더 작은 NFNet-F0 인코더에 비해 +8.0%의 이점을 가지고 있어 강력한 비전 백본 사용이 필요하다.
Freezing LM components prevents catastrophic forgetting
- (viii)로 훈련에서 LM 레이어를 동결하는 것이 중요하다는 것을 확인했다.
- 처음부터 훈련하면 -12.9%의 큰 성능 저하되고, 미리 학습된 LM을 미세 조정하면 -8.0%의 성능 저하가 발생한다.
- 모델이 새로운 데이터를 학습하는 동안 사전 학습을 점진적으로 잊어버리는 것으로, 언어 모델을 동결하는 것이 사전 학습 데이터 세트(MassiveText)를 혼합하여 학습하는 것보다 더 낫다.
4. Discussion
Limitations
- Pre-train된 LM을 기반으로 구축되며, LM 선행 학습은 일반적으로 도움이 되지만 가끔 hallucination과 근거 없는 추측을 유발할 수 있다. 또한 LM은 훈련 시퀀스보다 긴 시퀀스에는 일반화가 잘 되지 않는다. 또한 훈련 중 샘플 효율성이 떨어지는 문제도 있다.
- Flamingo는 개방형 작업과 같은 더 광범위한 작업을 처리한다.
- 문맥내 내 학습은 gradient 기반의 few-shot learning 방법에 비해 상당한 장점이 있지만 애플리케이션의 특성에 따라 단점도 있다. 수십 개의 예시로만 접근이 제한될 때 인컨텍스트 학습의 효과를 입증한다.
'Multi Modal > Paper Review' 카테고리의 다른 글
| [Survey] VQA (0) | 2024.03.24 |
|---|---|
| VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text (0) | 2024.03.04 |
| RUBi: Reducing Unimodal Biases for Visual Question Answering (1) | 2024.02.28 |


