
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
0. Abstrct
대규모 모델을 사전 학습할수록 모든 모델 파라미터를 재학습하는 전체 미세 조정은 실현 가능성이 낮아진다.
사전 학습된 모델 가중치를 동결하고 학습 가능한 순위 분해 행렬을 Transformer 아키텍처의 각 계층에 주입하여 다운스트림 작업에서 학습 가능한 매개변수의 수를 크게 줄이는 저순위 적응(LoRA)을 제안한다.
Adam으로 미세 조정된 GPT-3 175B와 비교했을 때 LoRA는 훈련 가능한 파라미터 수를 10,000배, GPU 메모리 요구량을 3배까지 줄일 수 있다. LoRA는 훈련 가능한 파라미터 수가 더 적고 훈련 처리량이 더 많으며 어댑터와 달리 추가적인 추론 지연 시간이 없음에도 불구하고 RoBERTa, DeBERTa, GPT-2 및 GPT-3의 모델 품질에서 미세 조정과 동등하거나 더 나은 성능을 발휘한다.
1. Introduction
큰 모델일수록 사전 학습 후에 finetuning을 할 때 많은 파라미터를 학습시켜야 하기 때문에 시간도 오래 걸릴 뿐더러 비효율적이다.
LLM 의 weight 는 최소 1.5~3B로, model을 GPU에 load하고, fine-tuning 학습하는 것은 웬만한 GPU로는 불가능하다. Forward와 backward, 이를 통한 Model weight update는 gradient를 전부 GPU에 저장해야 한다. 또 gradient 뿐만 아니라 optimizer를 위한 이전 기록(=tensor)들도 GPU에 저장해야 한다. 결국 Fully Fine-Tuning 을 위해서는 (모델의 weight 수)*(2~3)배의 GPU vram이 필요하다. Weight의 수가 많은 LLM 을 fully fine-tuning 하지 않는다.
따라서 모든 파라미터를 업데이트 하는 것이 아닌, 일부의 파라미터만 업데이트 하는 방식들이 제시되어 왔다. 그렇지만 이런 방식은 inference latency가 발생할뿐만 아니라 모델의 성능도 하락하는 경우가 많았다.
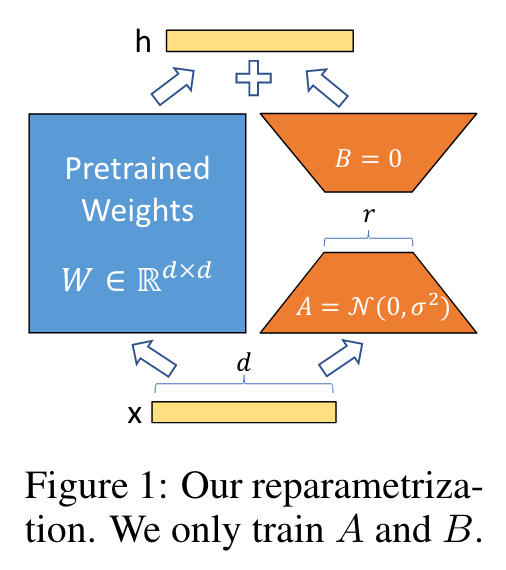
많은 파라미터를 가지는 모델들을 실제로는 저차원에 놓고, 저차원의 intrinsic rank를 이용해 finetuning하는 방법론인 Low-Rank Adaptation(LoRA)를 제시한다. 이를 이용해 사전 학습한 모델의 weight들은 업데이트 하지 않고, LoRA의 rank decomposition matrices의 weight들만 업데이트 하는 것이다.
GPT-3 175B의 경우 rank-1, rank-2 (위 그림에서 r=1, r=2인 경우)와 같은 low rank로도 full rank (rank-d, d는 model의 hidden dimension)를 대체할 수 있음을 증명했다.
2. Problem Statement
기존 fine-tuning 방식 모델의 전체 파라미터 Φ를 업데이트하는 최대우도법 목적식은 식(1)과 같다. 문제는 업데이트가 사전 학습에도 적용되고, finetuning 시에도 전체 파라미터 Φ를 모두 업데이트 하는 것이다.
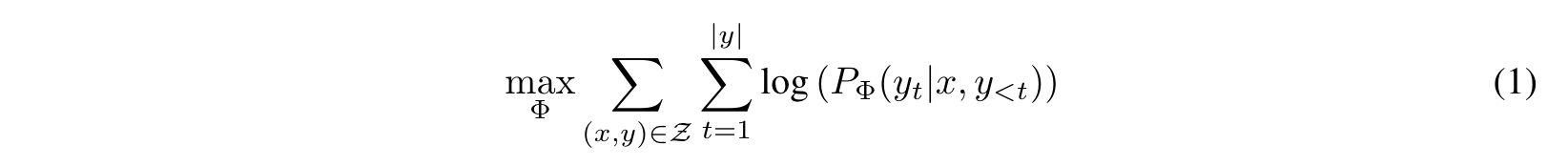
따라서 본 논문에서 제시하는 방법은 각 downstream task마다 다른 LoRA layer를 사용해 효율적으로 파라미터를 업데이트 할 수 있도록 한다. 기존의 model 파라미터인 를 이용해 forward를 진행한 뒤 얻어지는 Φ (의 gradient)를 이용해 backpropagation을 진행할 때, LoRA의 파라미터 Θ를 이용한다. LoRA를 이용해 일부분의 파라미터만 업데이트하는 목적식은 식(2)과 같다.
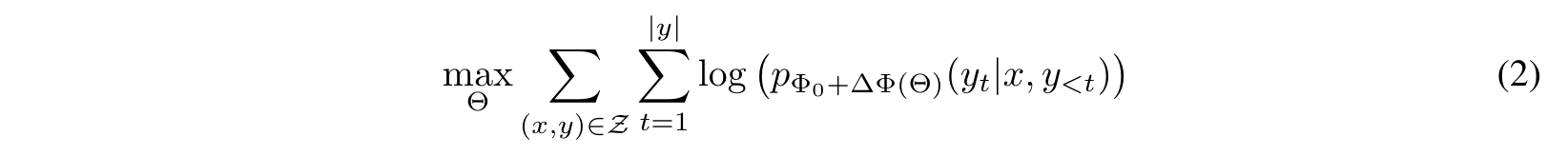
LoRA로 업데이트하는 파라미터 의 크기인 가 기존의 finetuning으로 업데이트하는 파라미터 의 크기인 의 0.01%이다. (훨씬 효율적으로 파라미터를 업데이트하고, task-specific하다.)
3. Aren't Existing Solutions Good Enough?
현재 본 연구에서 해결하고자 하는 fine-tuning 시의 문제를 해결하기 위한 다양한 시도들이 있어왔다. 이러한 방법들을 통틀어 Parameter-Efficient Fine-Tuning (PEFT)라 부른다.
논문에서는 아래와 같이 두 가지 방법을 밝히고 있다.
- Adding adapter layers : Adapter라는 layer를 transformer block에 추가해, 이 부분만 학습하는 것으로 기존 finetuning을 대체
- Optimizing some forms of the input layer activations : Language model의 입력으로 들어갈 input vocab embedding에 prompt embedding을 추가하고, prompt embedding을 다양한 학습 방법으로 학습시키는 것으로 기존 finetuning을 대체
그러나 위의 두 방법 모두 문제가 존재한다.
- Adapter Layers Introduce Inference Latency (adding adapter layers) : Transformer를 이용한 기존 대규모 신경망은 하드웨어의 병렬 처리가 가능하다는 것이 장점이었는데, adapter를 적용하면 추가적인 컴퓨팅 작업이 들어가기 때문에 작업 시간이 증가했다.
- Directly Optimizing the Prompt is Hard (optimizing some forms of the input layer activations) : 대표적인 예시로 prefix tuning이 있는데, 최적화하는 것 자체가 어렵고, 그 성능이 단조적으로 증가하지 않고 진동하는 경우도 있다. 또 sequence input을 넣을 때 prompt 자리를 미리 만들어 놓아야 하기 때문에 downstream task를 처리하는데 사용할 수 있는 sequence length의 길이가 줄어든다.
4. Our Method
LoRA의 방법론은 본 논문에서는 트랜스포머에서만 적용되었지만, 다른 딥러닝 구조에서도 적용될 수 있다.
4.1 Low-Rank-Parametrized Update Matrices
신경망의 많은 레이어들은 행렬곱으로 이루어져 있는데, 대부분의 가중치 레이어들은 full-rank이다. 기존의 연구에서 밝힌 바로는, 모든 사전 학습된 언어 모델은 low intrinsic rank를 가질 수 있다. 예를 들어, 기존 모델의 가중치 매트릭스가 크기를 가질 때, 이를 매트릭스 B와 매트릭스 A로 나타낼 수 있다( 보다 작은 차원). 기존의 파라미터 업데이트 과정과, A & B 매트릭스를 이용한 foward pass 과정을 수식으로 나타내면 식(3)과 같다.
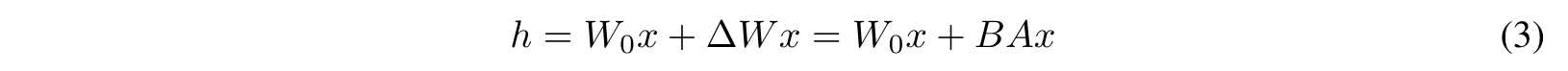
가중치 초기화 시, A 매트릭스는 가우시안 분포를 따르는 랜덤 변수로 초기화하고, B 매트릭스는 0으로 초기화한다.
A Generalization of Full Fine-tuning
LoRA 방법론을 통하면 차원 수는 감소하지만(full-rank → r-rank), 원래 모델과 관련된 가중치만 효율적으로 학습가능하다. Adapter-based 방법론의 경우엔 추가적으로 MLP 레이어를 학습해야 하며, prefix-based 방법론의 경우 input에 prompt embedding을 추가해야하기 때문에 long input sequences 추가하는데 한계가 있다.
No Additional Inference Latency
특정 task를 위해 LoRA 방법론으로 BA 가중치 매트릭스를 이용해 파인튜닝을 한 뒤 다른 downstream task에 적용하고 싶은 경우, 단순히 매트릭스를 매트릭스로 바꾸는 식으로 효율적인 학습이 가능하다.
4.2 Applying LoRA to Transformer
Transformer 한 블럭에는 여러 개의 가중치 매트릭스가 있는데, self-attention module에 4개의 가중치 매트릭스가 있고() 인코더, 디코더 각각에 MLP module이 있다. 이 중에서 본 논문이 LoRA를 적용하는 가중치 매트릭스는 attention 가중치 매트릭스로만 제한한다. (Simplicity와 parameter-efficiency 때문에 MLP module의 가중치 매트릭스는 적용하지 않는다.)
LoRA의 가장 큰 이점은 메모리와 저장 공간을 효율적으로 사용할 수 있다는 것이다. 특히 GPT-3 175B의 경우, VRAM의 사용량을 1.2TB에서 350GB로 줄일 수 있었다. 또 rank=4로 , 매트릭스만 adapt 할 경우 35MB까지 줄일 수 있었다. 이를 통해 속도가 25% 향상되었다.
반면 다른 downstream task를 진행할 때마다 다른 AB 매트릭스들을 사용해야 하는 한계가 존재했다.
5. Empirical Experiments
본 논문에서는 LoRA를 RoBERTa, De-BERTa 그리고 GPT-2에 적용시켜보고, 크기를 키워 GPT-3 175B에도 적용시켜 보았다. Natural language understanding(NLU), natural language generation(NLG), GLUE benchmark, NL to SQL queries, SAMSum 등 다양한 downstream task에서 성능을 평가했다. 모든 실험은 NVIDIA Tesla V100을 이용해 진행했다.
5.1 Baselines
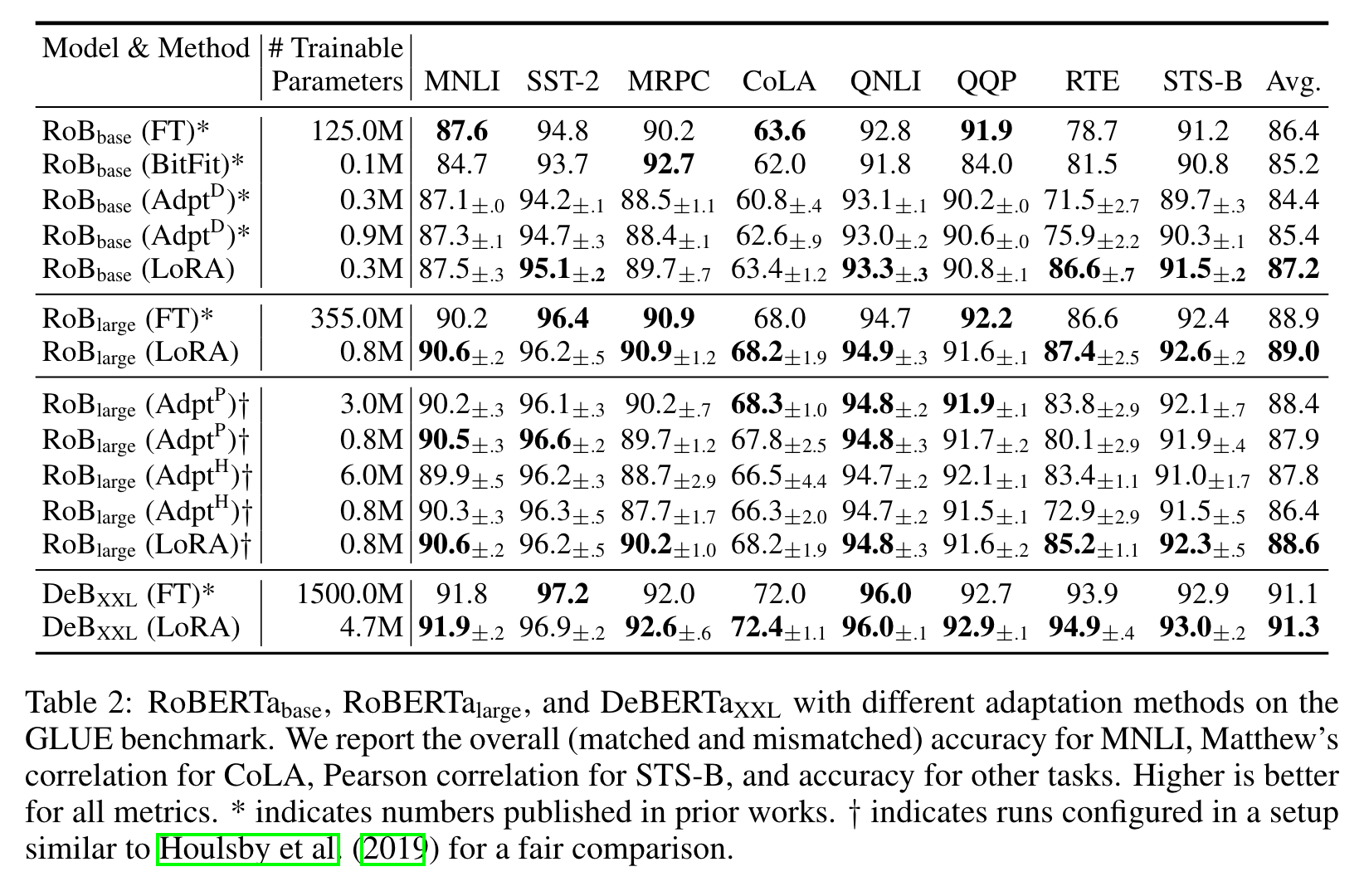
* 표시는 이전 연구의 방법론을 의미하며, † 표시는 공정한 비교를 위해 Parameter-Efficient Transfer Learning for NLP, Houlsby etal., (2019)의 설정을 따라 실험한 결과를 나타낸다.
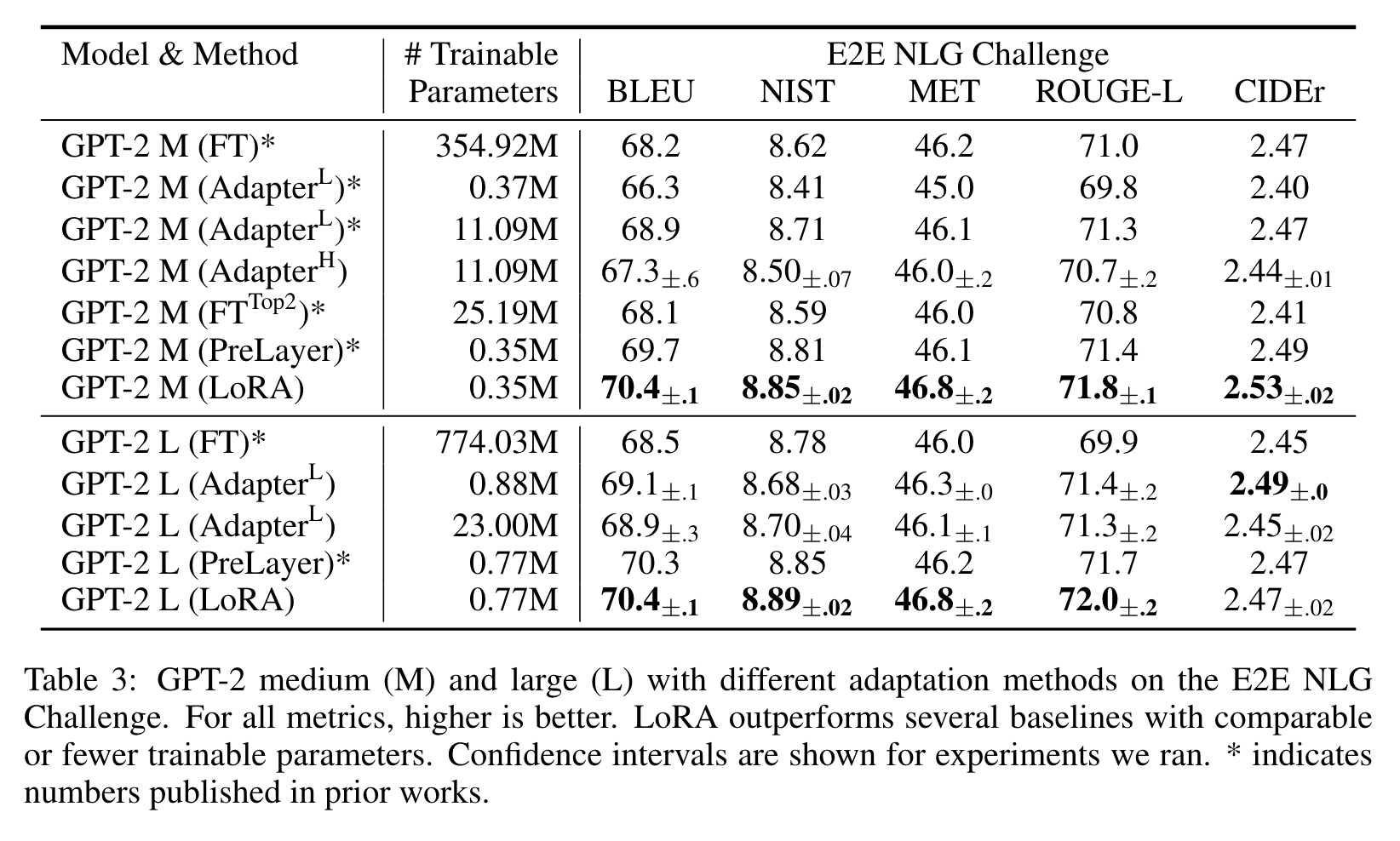
RoBERTa, De-BERTa, GPT-2를 이용한 대부분의 task에서 LoRA를 적용한 방법론이 가장 좋은 성능을 냈다.
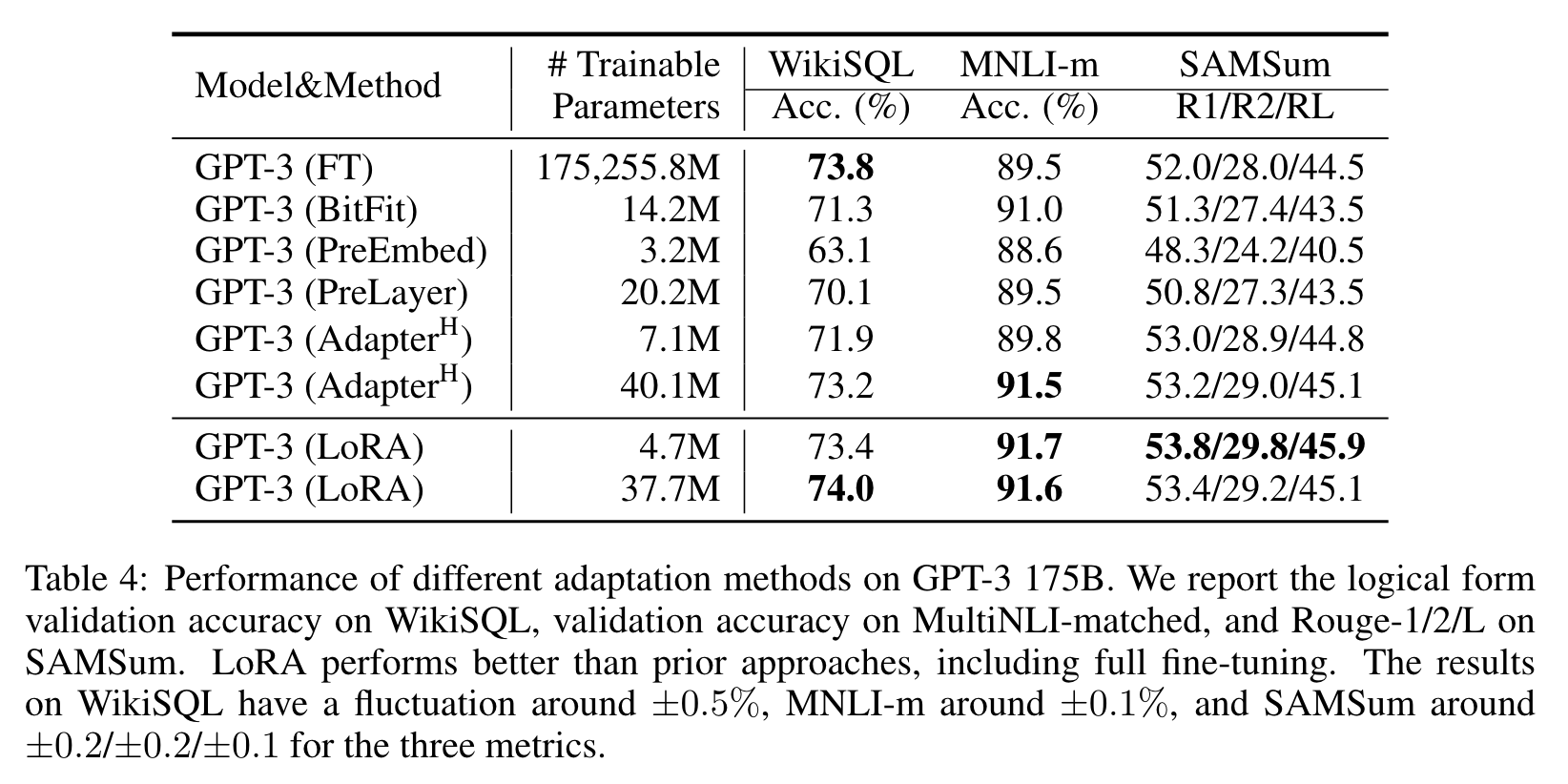
GPT-3를 이용한 task에서도 LoRA를 적용한 방법론이 가장 좋은 성능을 냈다.
6. Understanding the Low-Rank Updates
- 어떠한 가중치 매트릭스에서 LoRA를 이용해야 가장 높은 성능 향상을 기대할 수 있을까?
- LoRA의 최적의 rank는 무엇일까?
- Adaptation matrix Δ와 사이에는 어떤 관계가 있을까?
6.1 Which Weight Matrices in Transformer Should We Apply LoRA To?
앞서 언급한 것처럼, self-attention module에 있는 가중치 매트릭스들()만 고려했으며, 전체 파라미터 수가 18MB(FP16인 경우 35MB)을 넘지 않도록 설정했다. 업데이트하는 파라미터의 용량을 제한하기 위해, 한 가지 종류의 가중치 매트릭스를 사용한다면 rank=8이며, 두 가지 종류의 가중치 매트릭스를 사용한다면 rank=4로 하는 것이다.
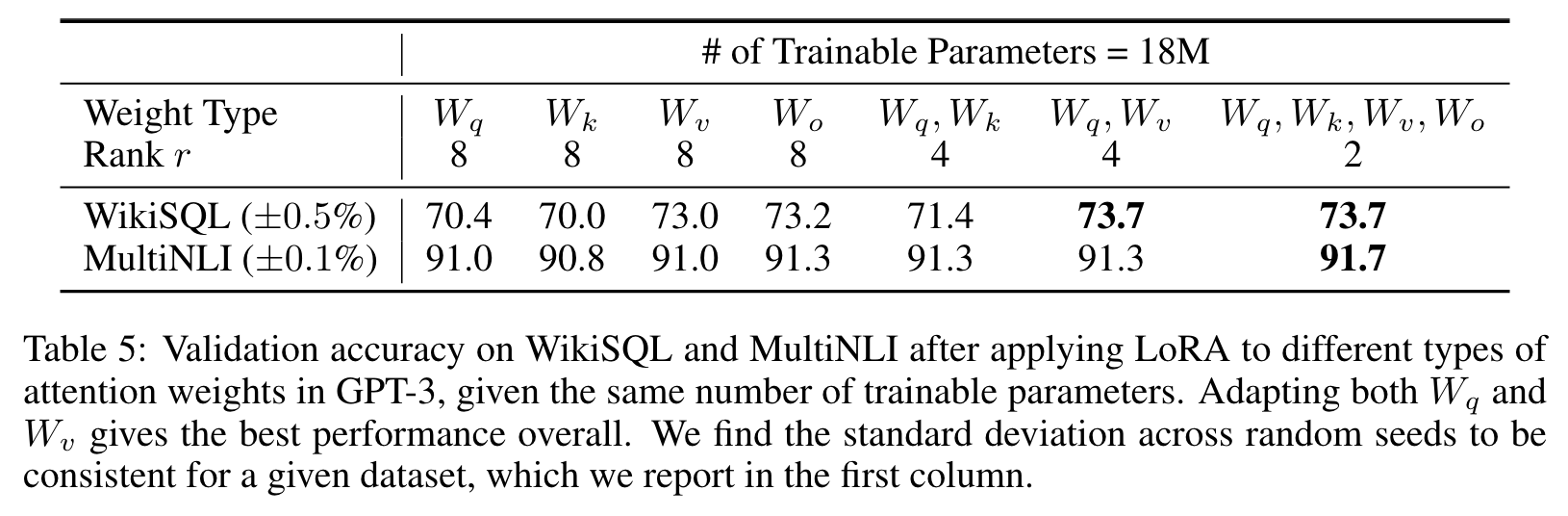
결과를 살펴보면, , 두 가중치 파라미터에 LoRA를 적용하는 것이 업데이트하는 가중치의 종류를 최대한 적게 가지면서 좋은 성능을 냈다. 이를 통해 알 수 있는 것은 rank를 4로 해도 충분히 의 정보를 담을 수 있다는 것이다
6.2 What is the Optimal Rank for LoRA?
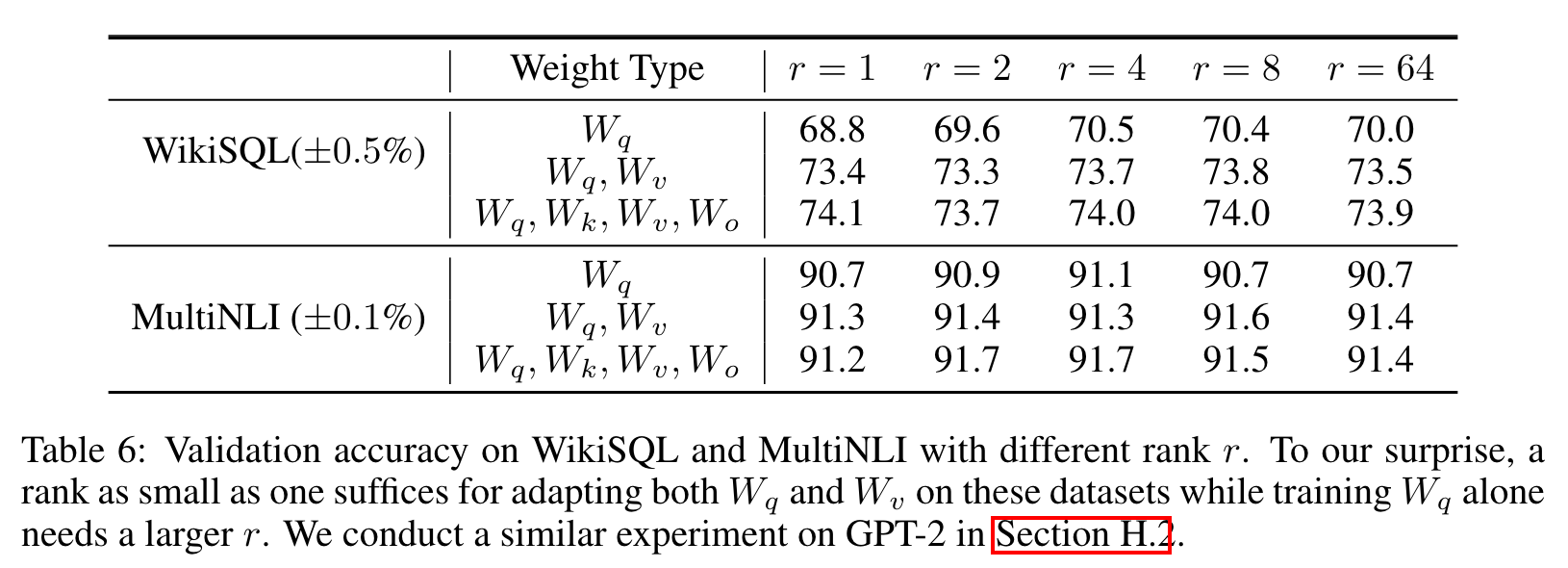
매우 작은 rank로도 준수한 성능을 내는 것을 확인할 수 있다. ( 업데이트 시, 매우 작은 'intrinsic rank'를 이용할 수 있다.)
Subspace similarity between different
똑같은 사전 학습 모델에서 rank 크기가 각각 8, 64인 LoRA를 적용해 학습한 뒤 만들어진 각각의 LoRA 매트릭스를 , 라 할 때, 이들의 singular value decomposition(SVD)를 구한 뒤, 값과 Grassmann distance를 이용해 두 매트릭스의 유사도를 계산한다. 그 결과 , 의 1차원에서 유사도가 제일 높게 나왔으며 차원이 커질수록 유사도가 감소하였다.

LoRA의 rank를 매우 저차원으로 했을 때도(심지어 rank가 1일때도) LoRA를 적용한 GPT-3가 downstream task에서 좋은 성능을 낼 수 있는 이유를 보여준다.
7. Conclusion and Future Work
Large Language Model을 finetuning하는 것은 많은 비용과 시간이 드는 작업이다. LoRA 방법론을 통해, inference latency 줄일 뿐만아니라 input sequence 길이를 줄이지 않고도 finetuning이 가능하다. 또한 다양한 downstream task에서 단순히 적은 수의 LoRA 파라미터만 바꾸면 되기에 효율적이다.
- LoRA와 다른 adaptation 방법론과 결합할 수 있지 않을까
- LoRA의 원리가 명확하게 밝혀지지는 않았음
- LoRA의 weight matrices를 고를 때 휴리스틱한 방법에 의존
- 의 rank 축소가 가능하다면 도 rank를 축소해도 되지 않을까 하는 의문



