
0. Overview
(1) 목적
- 본 프로젝트를 통해 음성 데이터를 handcrafted feature로 기술하는 법을 알 수 있다.
- 기술한 feature를 활용하여 음악의 장르를 분류할 수 있다.
(2) 데이터셋
음성/음악 데이터 다루기 - 장르 분류기

본 텀프로젝트에서는 음악 데이터에 대한 양질의 handcrafted feature를 추출하여 총 10가지의 음악 장르를 분류하는 것을 목표로 합니다.
1) 음성 데이터 사전 지식
음성 데이터 활용
음성 데이터는 인공지능 스피커에서의 음성 인식, 유튜브 자막 생성을 위한 오디오 캡셔닝 등 다양한 분야에 활용되고 있습니다. 음성 분야의 최신 기술 동향을 살펴보면, 음성 데이터로부터 handcrafted feature를 추출하여 이를 인공지능 신경망의 입력으로 사용하는 추세입니다. 이를 위해서는 raw data(음성)으로부터 handcrafted feature가 어떻게 기술되는지 알아야 할 필요가 있습니다.
음성 데이터 소개
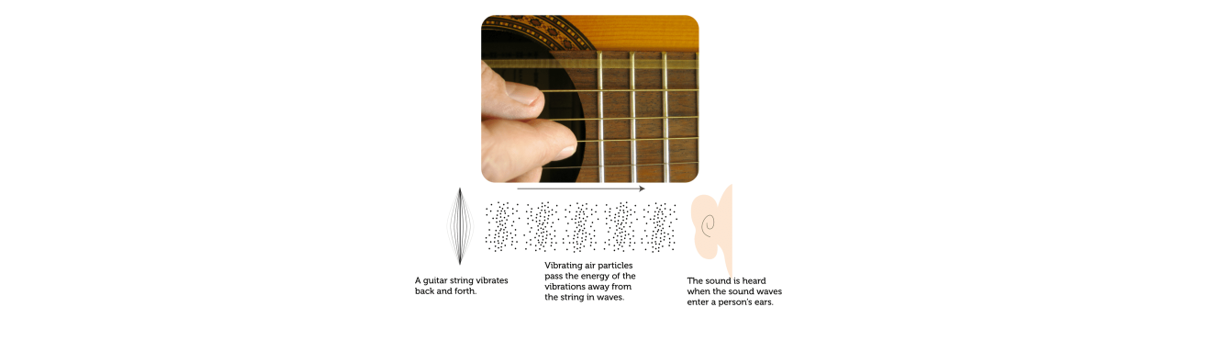
기타 줄을 튕기면 순간적으로 줄이 앞뒤로 흔들리게 됩니다. 이 때 줄 주변의 공기도 앞뒤로 흔들리며 주변으로 퍼져나가게 되고, 이렇게 앞뒤로 흔들리며 이동하는 공기가 우리의 청각 기관으로 들어와 고막을 흔들게되면 우리는 소리를 인식하게 되는 것입니다.
소리가 발생하는 경우 공기는 압축되며, 압축이 얼마나 되었느냐에 따라 진동합니다. 이는 공간이나 매질을 전파해나아가는 현상인 Wave(파동)로 표현할 수 있습니다.
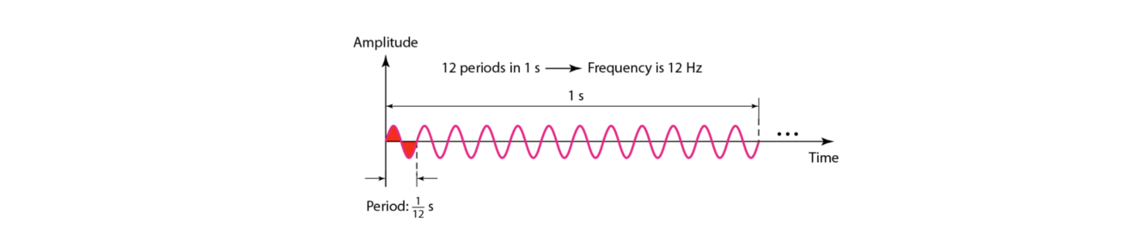
위 그림에서와 같이 시간 축에 대한 파동의 높이를 진폭(amplitude), 한 사이클을 도는 데 걸리는 시간을 주기(period), 1초에 완성되는 주기의 횟수를 주파수(frequency)라고 칭합니다. 주파수의 단위는 Hz이며 낮은 음일수록 주파수가 낮고, 높은 음일수록 주파수가 높습니다. 또한 소리의 크기는 진폭에 따라 결정됩니다.
샘플링(Sampling)

연속적인 음성은 아날로그 데이터이기 때문에 컴퓨터에 입력시키기 위해서는 디지털 정보로 표현해주어야 합니다. 이 때 아날로그 데이터를 무한히 쪼갤 수는 없으므로 기준을 세워 대표값으로 쪼개 사용하는데, 이 과정을 샘플링(Sampling)이라고 합니다. 샘플링은 주로 시간 도메인을 기준으로 이루어집니다. 샘플링 레이트(sampling rate)는 1초당 추출되는 샘플의 개수입니다. 사람의 가청 주파수 영역을 고려한 표준 샘플링 레이트는 44100Hz인데, 이는 1초를 44100등분하여 오디오 데이터를 이산화하는 것을 의미합니다. 샘플링 레이트를 높여 잘게 쪼갤수록 음성 데이터의 정보 손실은 줄어들지만, 데이터의 크기가 늘어날 것입니다.
양자화(Quantization)
앞서 샘플링을 통해 시간 축에 대한 이산화를 진행하였다면, 양자화는 진폭 축에 대한 이산화에 해당합니다. B bit를 기준으로 양자화하는 경우 -2^(B-1) ~ +2^(B)의 구간으로 진폭값들이 이산화되고 마찬가지로 B가 클수록 더 세부적인 정보를 담음으로써 원래 음성 신호의 정보 손실을 줄일 수는 있지만 그만큼 필요한 저장 공간이 늘어나게 될 것입니다.
이렇게 샘플링과 양자화를 거쳤다면 이제 컴퓨터에 입력해줄 수 있는 디지털 정보로 변환된 것입니다.
2) 이번 텀프로젝트에서 사용할 Handcrafted feature
컴퓨터에 입력할 수 있도록 샘플링과 양자화를 거쳤다고 해도, 이를 바로 분류기에 넣는 것은 높은 성능을 보장할 수 없습니다. 이는 음성 정보 안에 여러 주파수가 섞여 있으며 방대한 정보를 담고 있기 때문입니다. 따라서 데이터 중 음성의 대표적인 성질을 나타낼 수 있는 handcrafted feature를 추출하여 사용하는 것이 필수적입니다. 즉, 데이터에서 어떠한 특징을 어떠한 방식으로 추출하는지에 따라 분류기 성능에 큰 영향을 끼칠 수 있기 때문에 feature 추출을 위해서는 신중한 설계가 선행되어야 합니다.
본 텀프로젝트에서 사용되는 음악 데이터들을 잘 표현하기 위해, 두 가지 도메인에서의 feature를 추출하려고 합니다. 첫 번째 도메인은 rhythm 도메인이고, 여러 rhythm feature 중 Tempogram을 사용하려고 합니다. 두 번째는 spectral 도메인으로, 대표적인 음성 feature MFCC와 Chromagram을 사용하고자 합니다.

해당 feature들은 음성 관련 라이브러리인 librosa와 numpy만으로 모두 구현할 수 있습니다.
자세한 설명은 아래에서 이어가도록 하겠습니다.
3) 음악 데이터 특징 추출 구현
(원활한 구현을 위해 본 매뉴얼 뿐만 아니라 스켈레톤 코드 내의 주석 또한 자세히 확인하시기 바랍니다.)
두 도메인의 feature를 추출하기에 앞서, 아날로그 형태의 음악 데이터를 학습에 사용하기 위해서는 먼저 windowing(=sampling) 과정을 거쳐주어야 합니다.
앞서 표준 샘플링 레이트는 44100Hz를 주로 사용한다고 말씀드렸었는데, 본 텀프로젝트에서는 22050Hz를 사용합니다. 즉, 1초를 22050등분하여 음악값들을 샘플링해오겠다는 것입니다.
[Empty Module # 1] Rhythm domain feature extraction
첫 번째 Empty Module에서는 여러가지 rhythm 도메인의 feature 중 Tempogram을 추출합니다.

본 Empty Module #1에서 구현할 rhythm feature 추출 흐름도는 위와 같습니다.
리듬이란, 일반적으로 음악의 기본이 되는 규칙적인 펄스 또는 음악에서 전반적으로 유지되는 반복적 패턴을 의미합니다. 이 때 일정한 간격으로 발생하는 펄스를 비트라고 하며, 비트의 강약이 변화하여 만들어지는 패턴을 박자라고 칭합니다.
리듬과 그에 대한 박자는 사실 다양한 변수들이 혼합된 개념이기에 정확히 한 문장으로 정의하기는 힘들지만, 보통 음악적 리듬의 박자 구조는 일정한 간격을 지닌 시간 축 격자에 표시할 수 있는 연속적인 리듬 이벤트를 의미합니다.
특히나 본 텀프로젝트에서 분류하고자 하는 서양 음악은 박자 시스템에 기반한 리듬 구조를 가지고 있기 때문에 박자 구조를 분석하는 것이 리듬 분석을 위해서는 필수적이라고 볼 수 있습니다. 그리고 이러한 음악의 리듬 패턴을 분석하는데 사용되는 시간적 feature 중 하나가 Tempogram입니다.
그렇다면 음악의 Tempogram은 어떻게 추출할 수 있을까요?
음악의 Tempogram을 추출하기 위해서는 먼저 windowing을 거쳐 시간별로 쪼개진 데이터를 librosa.onset.onset_strength() 함수의 입력으로 주어 onset 지점을 탐지해야 합니다. Onset이란, 주로 박자의 첫 번째 비트나 강조되는 리듬 변화가 발생하는 시점을 의미합니다. 그렇기 때문에 onset 지점을 검출하는 것이 곧 음악의 리듬을 분석하는 것이고, 이를 수행하는 다양한 방식이 있지만 대표적으로 주파수 스펙트럼의 변화, 에너지 변화 등을 파악하여 onset 지점을 검출합니다.
다음으로는 이렇게 탐지된 onset 지점을 작은 프레임 단위로 나누고 각 프레임에 대해 autocorrelation(자기상관) 값을 계산합니다. 이는 각 onset 지점의 자기상관성을 분석한 그래프로, 시간 지연된 타 onset 지점과의 유사도를 계산하여 주기성과 리듬 정보를 파악할 수 있게 됩니다.
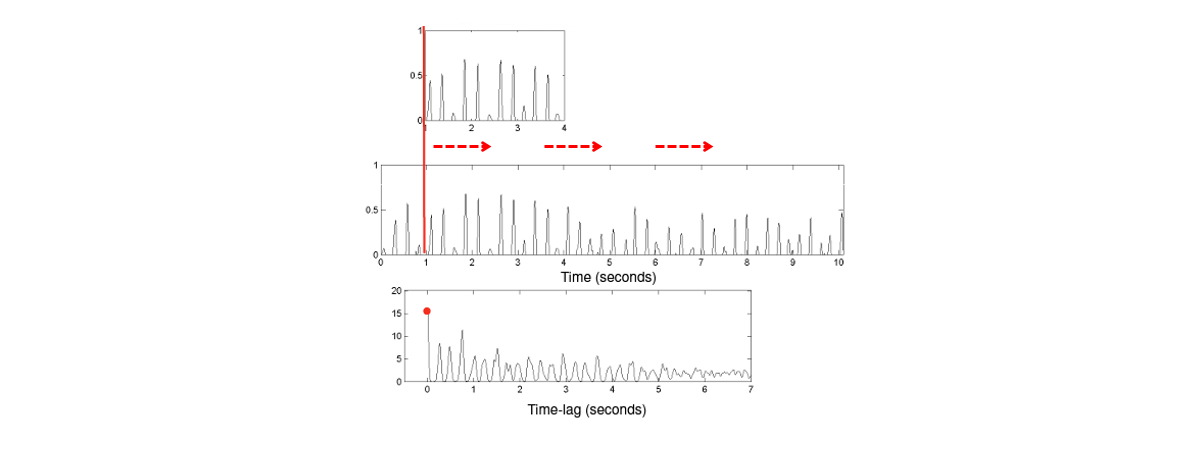
위 그림에서 가운데 그래프가 onset 검출 점수 그래프에 해당합니다. 앞선 과정을 거쳐 시간 지연 축에 대한 자기상관함수 값을 얻었다면, 위 값들을 통해 Tempogram 값을 얻어야 합니다. 현재 자기상관함수는 시간 지연 축에 대해 나타나 있기 때문에, 템포에 대한 축으로 변경해주어야 이 값들을 유의미하게 활용할 수 있습니다.
이러한 변형은 아래 두 과정을 거쳐 이루어집니다.
- Tempo (in BPM) = 60 / Timelag (in sec) 식을 적용하여 x축 변환
- 음악적으로 유의미한 tempo 축을 갖도록 보간 적용
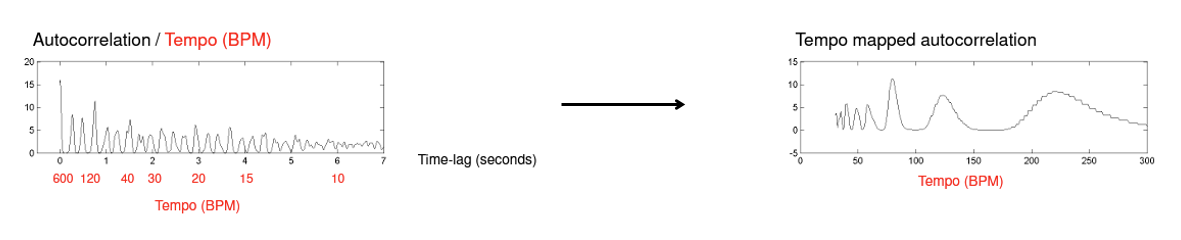
우선 첫 번째 식을 적용해 자기상관함수의 time-lag 축을 tempo(BPM)축으로 바꾸어줍니다. 이렇게 되면 수식에 따라 tempo 축의 범위가 선형적이지 않은데, 이를 펴주기 위해 tempo 축에 대한 보간을 수행합니다.
위와 같은 과정을 거쳐 음악의 Tempogram을 얻을 수 있습니다. 과정이 어렵고 생소할 수 있지만 librosa 라이브러리에서는 단순히 앞서 얻은 onset_strength 값을 librosa.feature.tempogram()의 인자로 넘겨줌으로써 음악의 Tempogram을 얻을 수 있습니다.
<참고>
librosa 라이브러리에서 사용하는 onset 검출 알고리즘 논문
librosa 라이브러리에서 사용하는 Tempogram 추출 알고리즘 논문
[Empty Module # 2] Spectral domain feature extraction
두 번째 Empty Module에서는 spectral 도메인의 여러 feature 중 Chromagram과 MFCC를 추출합니다.
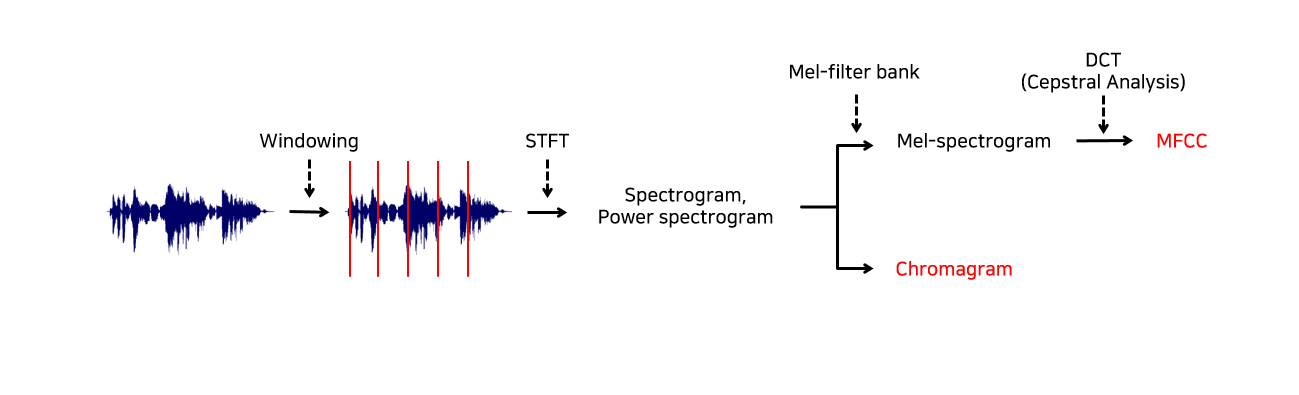
본 Empty Module #2에서 구현할 spectral feature 추출 흐름도는 위와 같습니다.
마찬가지로 처음엔 windowing을 거쳐 음성 데이터를 이산화합니다.
Windowing 과정을 거쳐 잘게 나누어진 프레임들에 각각 STFT(Short Time Fourier Transform)를 적용해 주파수 도메인으로 변환된 spectrogram을 얻는 과정을 거칩니다. 이에 대해서는 아래에서 계속 설명드리겠습니다.
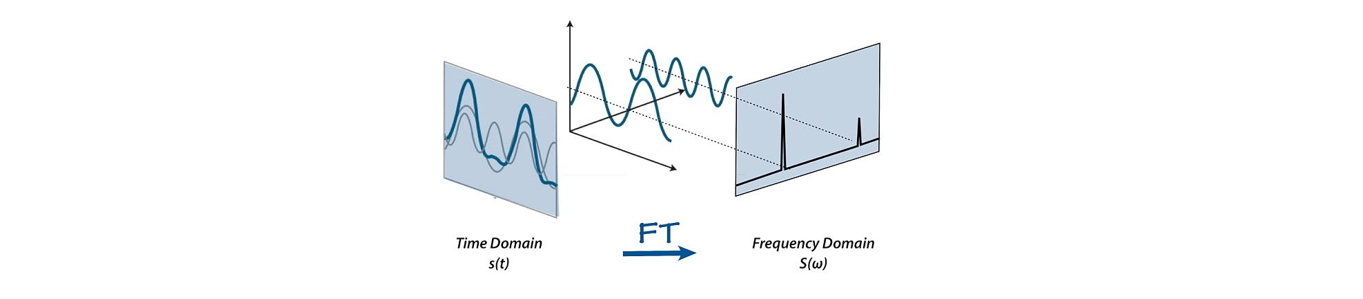
STFT(librosa.stft())는 음성 신호의 시간적 정보를 잘 활용하기 위해 각 프레임마다 FFT(Fast Fourier Transform)을 적용하여 시간 도메인의 데이터를 주파수 도메인으로 변환해주는 과정입니다. 일정 시간 영역에는 수많은 주파수가 혼합되어 있어 정보를 분석하기 어렵기 때문에 음성의 고유 배음구조를 유추할 수 있도록 신호를 위 그림과 같이 주파수 영역으로 변환시켜주는 것입니다.

FFT를 음성의 전체 시간 영역에 한 번에 적용하게 되면 음성의 시계열적 특성 정보를 제대로 활용할 수 없게 됩니다. 따라서 전체 시간 영역에 대해 FFT를 한 번에 적용하는 것이 아닌, 위 그림과 같이 잘게 나뉜 영역에 대해 여러 번(총 window 개수만큼) FFT를 적용하여 주파수 도메인으로 변환(=STFT)해준다면 주파수 정보 뿐만 아니라 시간적 순서와 관련된 time frame에 대한 정보까지 얻을 수 있게 됩니다.
STFT를 적용하여 얻은 값(=spectrum)의 magnitude를 사용하기 위해 절대값을 취하여 spectrogram을 얻고, 이렇게 얻은 spectrogram을 제곱하여 power spectrogram을 얻습니다. 다음 함수의 입력으로 spectrogram이 아니라 power spectrogram이 사용되는 이유는 주파수 도메인에서 시간에 따른 신호의 에너지를 강조해줄 수 있기 때문입니다. 제곱을 함으로써 음악 신호의 패턴을 더 쉽게 감지하고, 음악에서 특징점이 될 수 있는 부분을 잡아내는 데에 더욱 도움되는 값을 얻어낼 수 있는 것입니다.
Chromagram
Chromagram이란 음악의 주파수 정보를 사용해 음악의 음계 기반 특성을 파악하는 방법입니다. 음악의 주파수 영역에서 각 음높이에 해당하는 성분들의 빈도 정보를 표현하여 음악의 화음과 멜로디 정보를 추출할 수 있게 되는것입니다.
Chromagram은 기본값으로 하나의 프레임을 12차원의 벡터로 표현하는데, 여기서 12란 숫자는 서양 음악에서 사용되는 12음계 체계(도, 도#, 레, 레#, 미, 파, 파#, 솔, 솔#, 라, 라#, 시)를 기반으로 설정된 것입니다. 참고로 이 12음계를 chromatic scale이라 부르고, 이 음계를 기반으로 분석하는 것이 Chromagram인 것입니다.
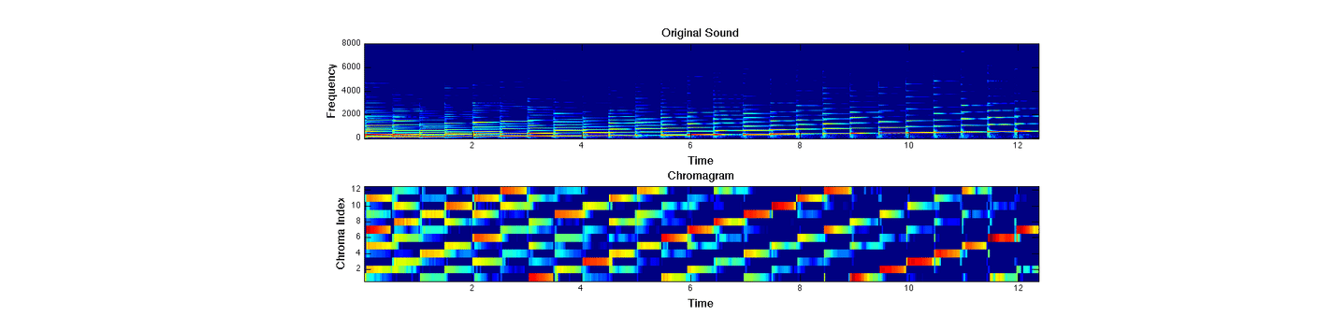
앞서 얻은 power spectrogram을 입력으로 주어 각 프레임에서 12개의 음들이 얼마나 등장하는지를 나타내는 크로마 밴드를 구하고, 이에 해당하는 파형 크기의 제곱 값을 합하여 Chromagram을 만들어냅니다. 위 그림은 12개의 음계를 바탕으로 만들어낸 음악의 Chromagram입니다.
Chromagram은 librosa.feature.chroma_stft()에 power spectrogram을 입력으로 주어 추출할 수 있습니다.
MFCC
MFCC는 Mel Frequency Cepstral Coefficient의 약자입니다. 다양한 음성 feature가 존재하지만, MFCC는 사람의 청각 기관 특성을 가장 잘 살려 설계된 feature 중 하나에 해당하고 현재까지도 음성, 음악 관련 task를 수행하기 위해 많이 사용됩니다.
다시 전체 파이프라인 그림으로 올라가보시면 MFCC는 power spectrogram에 melfilter 필터를 적용해 melspectrogram(librosa.feature.melspectrogram())을 추출하고, 켑스트럴 분석(DCT, Discrete Cosine Transform, librosa.power_to_db())를 거쳐 얻게됩니다.
Melspectrogram
실제로 사람의 달팽이관은 저주파 대역을 감지하는 부분은 굵고, 고주파 대역을 감지하는 부분은 얇습니다. Melfilter는 이렇게 사람의 청각기관이 높은 주파수보다 낮은 주파수 대역에 더욱 민감하게 반응한다는 사실을 반영하여 power spectrogram을 조정하는 역할을 수행합니다.
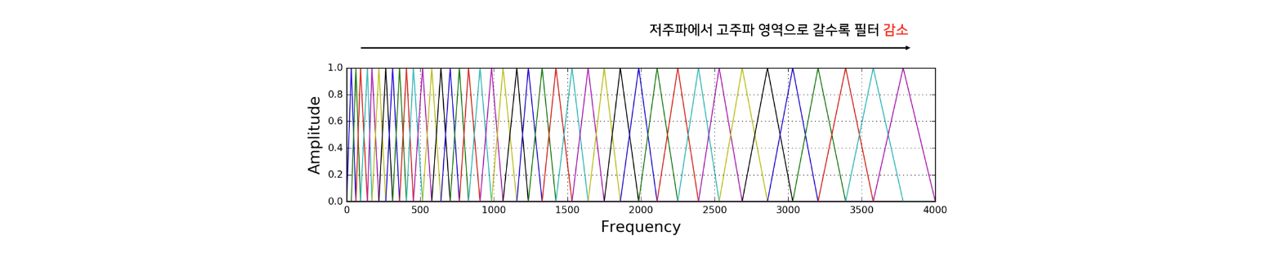
위 그림은 melfilter인데 상대적으로 높은 주파수 대역으로 갈수록 필터가 감소하는 것을 볼 수 있습니다. 이를 적용해 사람이 더욱 민감하게 반응하는 주파수 대역을 강조한 값으로 변환된 melspectrogram을 얻을 수 있게 됩니다.
Cepstral analysis
다음은 앞서 얻은 melspectrogram에 켑스트럴 분석 과정을 적용하고 이를 통해 최종적인 MFCC feature를 얻을 수 있습니다.
과정상으로 보면, melspectrogram을 log scale로 만들어 log spectrogram을 얻고 이에 DCT(Discrete Cosine Transform)를 적용하여 최종 MFCC feature를 추출하게 되는 것입니다.
여기서 log scale로 만드는 이유는, 사람의 소리 인식이 log scale에 가깝기 때문입니다. 다시 말해 사람이 두 배 큰 소리라고 인식하기 위해서는, 실제로 에너지가 100배 큰 소리여야 한다는 특성을 feature 추출 과정에 적용해주었다는 뜻입니다. 다음으로 DCT는 대부분의 실제 신호가 우함수이기 때문에 입력신호를 우함수인 코사인 함수의 합으로 표현해주는 과정입니다. DCT의 변환 결과는 계수 형태로 나타나며, log spectrogram에 DCT를 적용했을 때 주파수 성분으로 분해하여 얻은 계수 중 주로 사용되는 일부 계수들만 선택하면 그것이 MFCC feature로서 사용되는 것입니다.
[Empty Module # 3] 분류기 설계 및 테스트 수행
세 번째 Empty Module에서는 분류기(RandomForestClassifier)를 선언하고 학습 데이터에 대한 fit 및 테스트 데이터에 대한 예측을 수행합니다.
'Computer Science > Machine Learning' 카테고리의 다른 글
| Feature Extract : Speech [영어 음성 국제 분류] (5) (1) | 2024.06.10 |
|---|---|
| Feature Extract : Speech [음악 장르 분류] (4) (0) | 2024.06.10 |
| Feature Extract : NLP [한국어 텍스트 데이터를 활용한 영화 리뷰 분류] (2) (1) | 2024.06.10 |
| Feature Extract : NLP [한국어 텍스트 데이터를 활용한 영화 리뷰 분류] (1) (2) | 2024.06.10 |
| 차원 축소(Dimension Reduction) : 기타 (4) (0) | 2024.06.09 |



