
0. Overview
(1) 목적
- 본 프로젝트를 통해 2D 이미지 데이터를 Handcrafted Feature로 기술하는 법을 알 수 있다.
(2) 데이터셋
Caltech101 데이터 셋

- 101종류 영상 데이터 + 백그라운드 영상 데이터 (102번째 종류로 간주)
- 한 종류당 40장~800장까지 영상이 모아져 있음 - 데이터셋 공식 링크
리더보드에서 제공되는 가공된 데이터 셋
- 학습과 테스트 데이터로 제공되는 image_xxxx.csv 는 기존 2D 형태인 RGB영상([256,256,3] uint8)을
([HxWxChannel,1] = [196608, 1],uint64)의 형태로 가공하여 제공한다. - 학습 데이터 : 102개 클래스 X 각 30장 이미지 = 총 3060장의 이미지
- 테스트 데이터 : 1712장의 이미지
(3) Description
딥러닝 이전 시대를 주름잡던 알고리즘 BoVW
- 원래 Bag of Words(BoW)는 문서를 분류하기 위한 방법론으로 사용됐다. 즉, 문서 속 단어의 분포를 통해서 문서의 종류를 예측하는 방법론이다.
- 이러한 방법론을 영상 분류에 적용하기 위해, 그림1 과 같이 "문서 속 단어의 분포"를 "영상의 특징점 분포"로 변경하여 적용한 방법론이 BoVW(Bag of Visual Words)에 해당 한다.
- 기존 BoW가 문서 내 단어의 분포를 보고 문서의 라벨을 추측했다면, BoVW는 영상의 특징점(Local Feature) 분포를 보고 영상의 라벨을 추측한다.
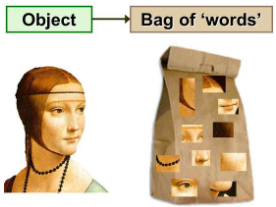
- 설명을 위해 그림 1, 3를 함께 보면, 영상 속에서 특징이라 할 수 있는 (눈,코,입, 턱 등)을 특징점("words") 라고 지칭하고 이를 저장한다.
- 사실 개념적인 이해를 돕기 위해 특징점을 (눈,코,입 등) 으로 표현했지만, 일반적으로 환경 변화에 강인한 코너, 에지 같은 요소들이 특징점으로 사용된다.
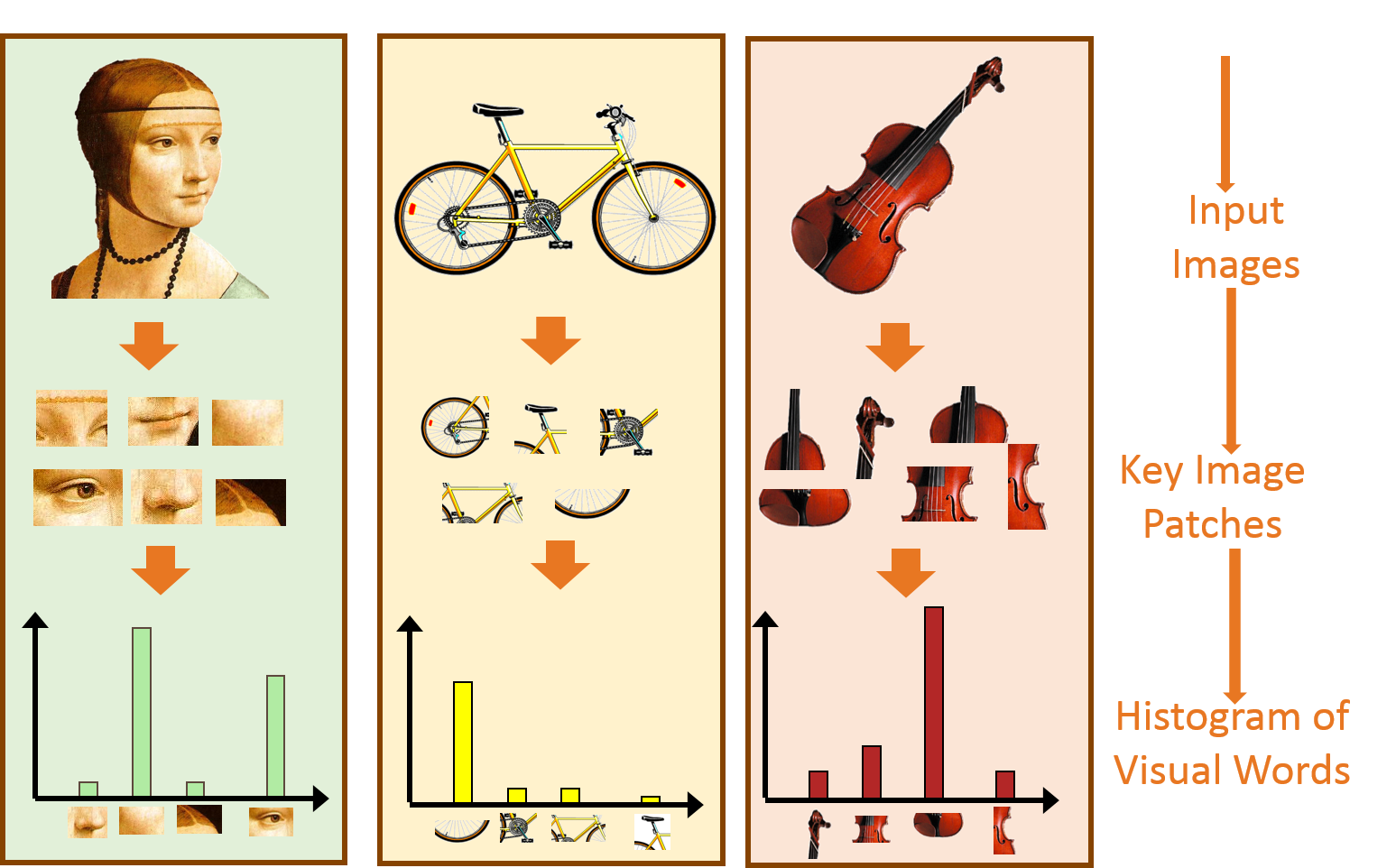
[그림 1] BoVW 개념
BoVW 알고리즘 설명

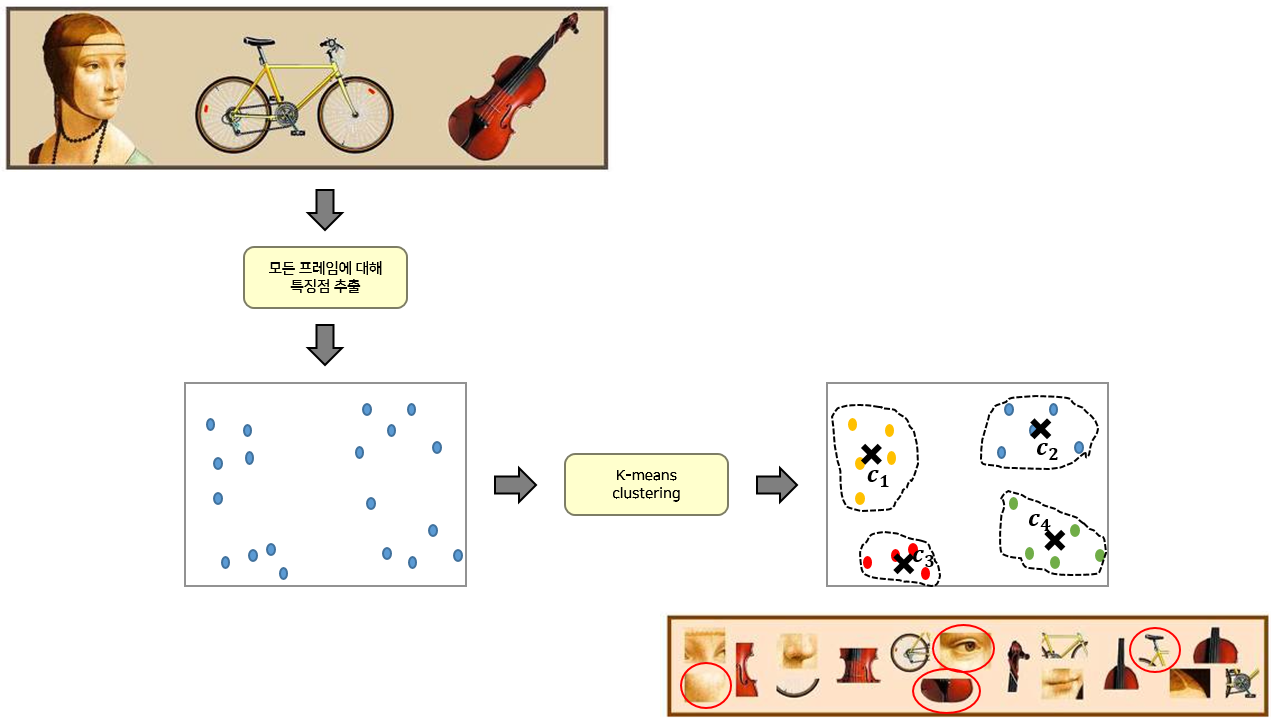
[그림 2] BoVW의 흐름도
BoVW 알고리즘 흐름을 이해를 위해 그림 2를 살펴 보면 아래와 같은 순서로 진행 된다.
- (1) 각 클래스 사진들의 특징점(SIFT)을 검출한 후 모든 특징점을 모은다.
- (2) 하나로 모은 모든 특징점을 군집화(Kmeans) 하여 대표 Visual Words (혹은 Codebook 이라 부름) 를 선정한다.
- (3) 모든 학습 영상에 대해 Visual Words (Codebook)가 각 영상에 포함된 빈도 (histogram)를 구한다. 이 Histogram 이 2D 영상을 표현하는 1D vector 가 된다.
- (4) 3번 과정을 통해 구한 1D vector (피쳐:Feature)를 SVM으로 학습한다.
- (5) 앞서 구한 Visual Words 를 이용하여 테스트 영상에 대한 Histogram 을 구하고, 이미 학습된 SVM 을 통해 테스트 영상의 종류를 예측한다.
1) 영상 특징 추출 (SIFT)
[Empty Module #2] extract_descriptor 구현 시 참고
- 이미지에서 특징점(visual word)을 추출하는 방법은 여러가지가 있으나 그 중 가장 대표적인 SIFT 알고리즘을 소개한다.
- Local descriptor 라고도 불리우는 특징점(visual word) 추출 알고리즘 SIFT는 이미지 내 물체의 크기와 회전에 강인하도록 설계되었으며, 이미지 내의 특징점(visual word)이 될 위치를 detect(탐지) 하고 이를 describe(기술) 한다.
- 기술된 특징점(visual word)은 128차원의 벡터 형태로 구성되며 이를 특징점으로 사용한다.
- 그림 4-1은 SIFT를 이용해 영상의 특징점을 추출한 예시이다.
- 책을 촬영한 각도, 회전, 조명, 크기가 달라졌어도 책 내부의 비슷한 위치를 특징점으로 가리키는 것을 알 수 있다.
- 이는 SIFT를 통해 특징점을 추출했을 경우 해당 변화 요소들에 불변한 것을 의미하며 주로 이렇게 환경 변화에 강인하게 추출된 특징점들을 군집화하여 대표 Visual Word를 얻는다.

- SIFT는 영상 내에서 알고리즘을 통해 환경 변화에 강인한 부분을 찾아내고 이를 특징점으로 추출한다.
- 그러나 단색의 벽이나 배경, 혹은 단순 에지의 경우 알고리즘에 의해 특징점으로 추출하지 못하게 되는 경우가 생긴다.
- 이러한 것을 해결하고자, 영상 내의 부분적으로 영상 기술에 도움을 줄 수 있는 정보들을 최대한 활용하기 위해 DenseSIFT가 제안되었다.
- DenseSIFT는 영상 내 일정 간격의 위치를 특징점으로 선정하고 이에 대해 기술한다.
- 영상의 부분 정보를 최대한 활용하기에 SIFT를 사용한 BoVW보다 DenseSIFT를 사용한 BoVW가 더 좋은 성능을 보인다.
- [그림 4-2]는 SIFT와 DenseSIFT의 시각적인 차이를 나타낸다.

2) Codebook 생성
- 모든 이미지에서 특징점(visual word)을 추출한 뒤 이들 중 대표가 되는 특징점(codebook)을 선정해야한다.
- 이를 위해 k-means 알고리즘을 사용하며 모든 128차원의 특징점(visual word)을 거리 기준 k개의 군집으로 나누는 방식이며 각 군집의 중심점을 대표 특징점(codebook)으로 사용하는 방식이다.
- 주의할 점은 학습 데이터 셋에서 특징점(visual word)만을 활용해 대표 특징점(codebook)을 선정해야 한다.
- (테스트 데이터 셋에서 얻은 특징점은 codebook의 생성에 관여하면 안된다!!)
(GPU를 사용해야 하기 때문에 꼭 GPU 를 활성화 한 상태로 코드를 실행해야 한다!)

3.a (BoVW 기법) Visual words를 이용한 Histogram 생성
[Empty Module #3] BoVW 구현 시 참고
- 지금부터 이야기하는 Histogram은 영상을 대표하는 정보인 전역 특징량(global feature) 에 해당되며, 개념적으로는 그림 7과 같다.
- 즉, 사람 얼굴 영상은 눈 2개, 코1개로, 자전거 영상은 안장 1개 바퀴 2개로 히스토그램이 구성된다는 것이다.
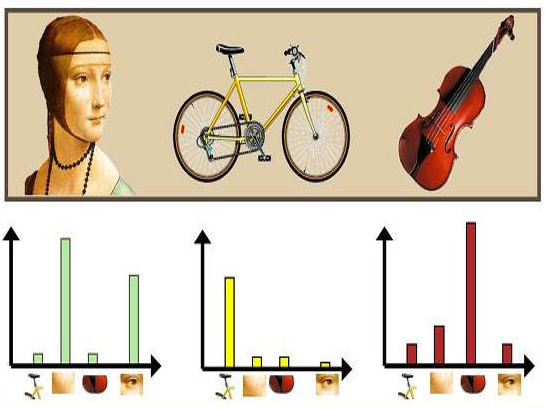
[그림 7] BoVW 설명도 - Histogram Visual words (혹은 Codebook)를 이용하여 영상을 대표하는 Histogram을 구하는 방법을 구체적으로 이야기 하면, 각 영상의 모든 특징점과 codebook을 비교하여, 그 특징점과 가장 유사한 Visual words 의 도수(히스토그램의 Y축)를 높히는 것이다.
- 영상의 모든 특징점(SIFT descriptor)과 codebook을 비교(L2 distance를 구하여 가장 거리 값이 작은 것)하여 histogram을 생성하면 된다.
3.b (VLAD 기법) VLAD(Vector of Locally Aggregated Descriptors) 피쳐 추출 방법
[Empty Module #4] VLAD 구현 시 참고
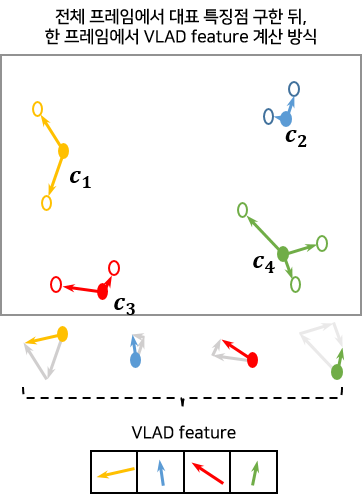
- BoVW에서는 대표 특징점에 대한 분포를 각 이미지마다 계산해 히스토그램 형식의 feature를 사용한다면,
- VLAD는 각 이미지 내의 특징점(visual word)들을 대표 특징점(codebook)에 거리 순으로 할당해 둘 간의 벡터 차이를 계산한 후 동일한 대표 특징점(codebook)에 할당된 특징점(visual word)의 벡터 차이 값을 모두 더해주는 방식으로 feature를 기술하는 방식이다.
- 이로 인해 BoVW 에서 사용한 특징점(visual word) 추출, 대표 특징점(codebook) 선정까지의 방식은 동일하게 사용된다.
- 2번 과정까지는 동일하게 진행되고, 3번 과정에서 3.a와 3.b로 구분된다)
++ <3.a (BoVW), 3.b (VLAD) 피쳐 추출 시 적용 가능한 Spatial Pyramid Matching 기법>
[Empty Module #5] cut_image 구현 시 참고

- 기존 BoVW와 VLAD 방법론은 기본적으로 [그림 9-level 0] 에서 보는 것과 같이 최종 기술자 추출을 위해 이미지 전체에 대해 한번만 계산을 수행한다.
- 반면, 소개할 Spatial Pyramid Matching 방법은 이미지를 여러 단계의 resolution으로 분할한 후 각 단계의 분할 영역 모두를 고려하여 기술자를 추출하게 된다.
- [그림 9]를 보게 되면 Spatial Pyramid Matching 방법에서는 level 0 뿐만 아니라 추가적으로 이미지를 점진적으로 세분(level 1에서는 2x2로 분할, level 2에서는 4x4로 분할, …)해 가면서 각각의 분할 영역마다 기술자를 추출해서 합치게 된다.
- 3.a의 BoVW 방법론에 적용 시 level 0, 1, 2 각각에서 별도로 히스토그램을 구한 후 , 이들 히스토그램들을 전부 모아서 일종의 피라미드(pyramid)를 형성한다.
- 그리고 이렇게 형성된 히스토그램 피라미드들을 합쳐서 최종적으로 기술자를 추출하게 된다.
- 여러 resolution에서 구해진 각각의 히스토그램을 모두 합쳐서 한번에 사용한다고 생각하면 된다.
Spatial Pyramid Matching 기법의 등장 배경
- 기존 Bag of Visual Words 방법은 기본적으로 feature들의 히스토그램(histogram)으로 이미지를 표현한다.
- 그렇기 때문에 추출한 feature들 간의 기하학적인 위치 관계를 잃어버리는 문제점을 가지고 있다.
- 물론 동물 등과 같이 변형이 심한 물체를 인식하는데는 이 특성이 오히려 장점으로 작용한다.
- 하지만 자동차 등과 같이 형태가 고정된 물체의 경우에는 성능저하의 큰 요인 중 하나가 될 수 있다.
- 이를 해결하기 위해 이미지를 점진적으로 분할해서 각 분할 영역마다 기술자를 추출해서 합치는 Spatial Pyramid Matching 기법이 등장했다.
4. SVM 분류기 학습하기
[Empty Module #6] SVM 구현 시 참고
- BoVW, 혹은 VLAD를 통해 기술된 feature vector 를 이용해 분류 모델 학습을 진행할 때, 여러분들이 배운 다양한 분류 모델을 적용해 볼 수 있다.
- 그러나 이번 프로젝트에서는 Bovw와 가장 잘 어울리기로 소문난 SVM 을 사용하기로 한다.
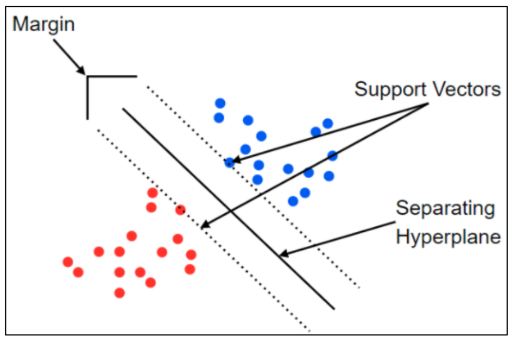
- 여러분도 잘 알고 있다시피, SVM은 결정 경계(Decision Boundary) 즉 분류를 위한 기준 선을 정의하는 모델이며, 이 모델은 그림 8의 margin 즉 선과 데이터의 최단 거리가 최대로 하기 위한 결정 결계를 찾는 것을 목표로 한다.
- SVM 을 통해 학습 데이터 간의 결정 경계를 찾고 이를 활용해 테스트 영상의 클래스를 분류한다.
- 평가 영상의 라벨(클래스)을 추정하기까지의 과정을 요약하자면 아래와 같다.
[모델 학습]
- 1. 학습 영상들의 특징점(SIFT or Dense SIFT) 검출
- 2. 추출된 학습 데이터의 특징점들을 군집화하여 대표되는 특징점을 모아 Codebook 생성 : K-means Clustering
- 3. 생성된 Codebook과 각 학습 데이터마다의 특징점들을 비교해 Histogram 기술자 생성
- 4. 학습 데이터의 Histogram 기술자로 SVM의 결정 경계 학습 : SVM
[모델 추론]
- 5. 평가 데이터의 특징점(SIFT or Dense SIFT) 추출
- 6. 학습 데이터로 생성된 Codebook과 각 평가 영상 내 특징점들을 비교해 Histogram 생성
- 평가 데이터로 Codebook을 재생성하는 것이 아닌 학습 데이터로 생성된 Codebook을 사용해야함
- 7. 학습 데이터로 기 학습된 SVM을 이용해 평가 데이터의 Histogram 기술자가 속하는 그룹을 선정하고 해당 그룹의 라벨을 할당
- 8. 평가 데이터의 라벨 CSV 파일로 기록
[베이스라인 정보]
- DenseX_BoVW_[0] : 0.23481
- 일반 SIFT 사용(Dense X), BoVW 기술자 사용, level 0에서만 기술자 추출
- Dense_BoVW_[0] : 0.34988
- Dense SIFT 사용, BoVW 기술자 사용, level 0에서만 기술자 추출
- Dense_BoVW_[0,1,2] : 0.40128
- Dense SIFT 사용, BoVW 기술자 사용, level 0,1,2 모두에서 기술자 추출
- Dense_VLAD_[0] : 0.49649
- Dense SIFT 사용, VLAD 기술자 사용, level 0에서만 기술자 추출
[성능 향상 팁]
- VLAD 기술자의 경우 벡터들의 합에 대한 정보를 가지게 됩니다. 이때 최종 벡터 합들의 크기 값을 균등하게 scaling 해 보면 어떨까요?
- 결국 이미지를 표현하는 기술자들은 codebook의 codeword와의 계산을 통해 구해집니다. codeword의 역할에 대해 잘 생각해보시길 바랍니다.
- Spatial Pyramid Matching에서 level 값을 더 다채롭게 조정해보면 어떨까요?
- PCA 차원 축소를 통해 메모리 부족 이슈가 있는 VLAD 에서도 Spatial Pyramid Matching을 사용해보자
'Computer Science > Machine Learning' 카테고리의 다른 글
| Linear Classification (구현) (0) | 2024.06.11 |
|---|---|
| Linear Regression (구현) (0) | 2024.06.11 |
| Feature Extract : Speech [영어 음성 국제 분류] (5) (1) | 2024.06.10 |
| Feature Extract : Speech [음악 장르 분류] (4) (0) | 2024.06.10 |
| Feature Extract : Speech [음악 장르 분류] (3) (1) | 2024.06.10 |

