
1. 기계학습 순서
① 데이터셋 불러오기
② Label map 제작
③ 데이터 분할 (train과 test로 나누기)
④ (옵션) 입력 데이터의 표준화
⑤ 모형 추정 혹은 사례 중심 학습
⑥ 결과 분석 (confusion matrix로 확인)
2. Iris 데이터셋 불러오기
import seaborn as sns
iris=sns.load_dataset('iris')
print(iris.head()) # 최초 5개의 관측치를 printprint(iris.shape) # iris data의 행과 열의 수
X = iris.drop('species', axis=1) # 'species' 열을 drop하고 input X를 정의
print(X.shape)
y = iris['species'] # 'species'열을 label y를 정의
3. Label map 제작
from sklearn.preprocessing import LabelEncoder
import numpy as np
classle = LabelEncoder()
y = classle.fit_transform(iris['species'].values) # species 열의 문자열은 categorical 값으로 전환
print('species labels :', np.unique(y)) # 중복되는 y 값을 하나로 정리하여 printyo = classle.inverse_transform(y) # 원래의 species 문자열로 전환
print('species :', np.unique(yo))
4. 데이터 분할
학습 데이터(train)와 시험 데이터(test)가 서로 겹치지 않도록 나눈다. 이는 학습데이터로 자료를 학습시키고 학습에 전혀 사용하지 않은 시험데이터에 적용하여 학습 결과의 일반화(generalization)가 가능한지 알아보기 위해서이다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
print(X_train.shape) # (105, 4)
print(X_test.shape) # (45, 4)
print(y_train.shape) # (105,)
print(y_test.shape) # (45,)
5. 입력 데이터의 정규화
특성 자료의 측정 단위(Scaling)에 의해 영향 받지 않도록 하는 과정이다. 시험 데이터(test data)의 표준화는 학습 데이터(train data)에서 구한 특성 변수의 평균과 표준편차를 이용한다. 표준화로 인해 데이터의 분포인 통계적 특성이 깨지면 머신러닝의 학습 저하를 가져온다.
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.transform(X_test)# 표준화된 data의 확인
print(X_train.head()) # X_train 최초 5개의 관측치
X_train_std[1:5,] # X_train_std 최초 5개의 관측치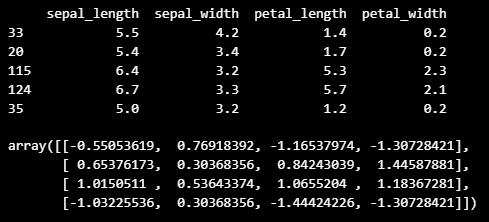
6. 모형 추정 혹은 사례 중심 학습
# KNN의 적용
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2) # 5개의 인접한 이웃, 거리측정기준: 유클리드
knn.fit(X_train_std, y_train) # 모델 fitting 과정y_train_pred = knn.predict(X_train_std)
y_test_pred = knn.predict(X_test_std)
print('Train 오분류 데이터 개수 : %d' %(y_train != y_train_pred).sum()) # Train 오분류 데이터 개수 : 4
print('Test 오분류 데이터 개수 : %d' %(y_test != y_test_pred).sum()) # Test 오분류 데이터 개수 : 3from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_test_pred)) # 0.9333333333333333
7. 결과 분석
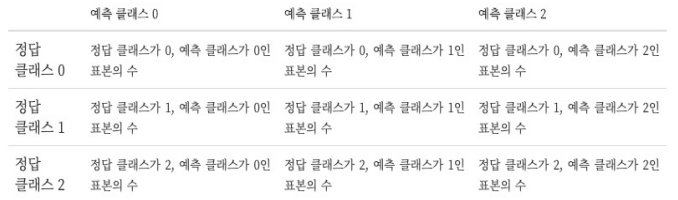
혼합 행렬 (confusion matrix)
타겟의 원래 클래스와 모형이 예측한 클래스가 일치하는지는 갯수로 센 결과를 표나 나타낸 것
from sklearn.metrics import confusion_matrix
conf = confusion_matrix(y_true=y_test, y_pred=y_test_pred) # 대각원소가 각각 setosa, versiolor, virginica를 정확하게 분류한 갯수
print(conf)
# setosa는 모두 정확하게 분류되었고, versicolor는 15개 중 2개가 virginica로 오분류되었고, virginica는 15개 중 1개가 versicolor로 오분류됨
'Computer Science > Machine Learning' 카테고리의 다른 글
| Linear Regression : Multi Linear Regression (1) (0) | 2024.03.23 |
|---|---|
| KNN(K-Nearest Neighbors) [자동차 가격 예측] (5) (0) | 2024.03.23 |
| KNN(K-Nearest Neighbors) [재배환경 별 작물 종류 예측] (4) (1) | 2024.03.23 |
| KNN(K-Nearest Neighbors) [영화 평점 예측] (3) (0) | 2024.03.22 |
| KNN(K-Nearest Neighbors) (1) (0) | 2024.03.21 |



