
0. Dataset
import numpy as np
import pandas as pd
train_data = pd.read_csv("/kaggle/input/2023-ml-w4p1/train.csv")
test_data = pd.read_csv("/kaggle/input/2023-ml-w4p1/test.csv")x_train = train_data.iloc[:,:-1]
y_train = train_data.iloc[:,-1]
x_test = test_data
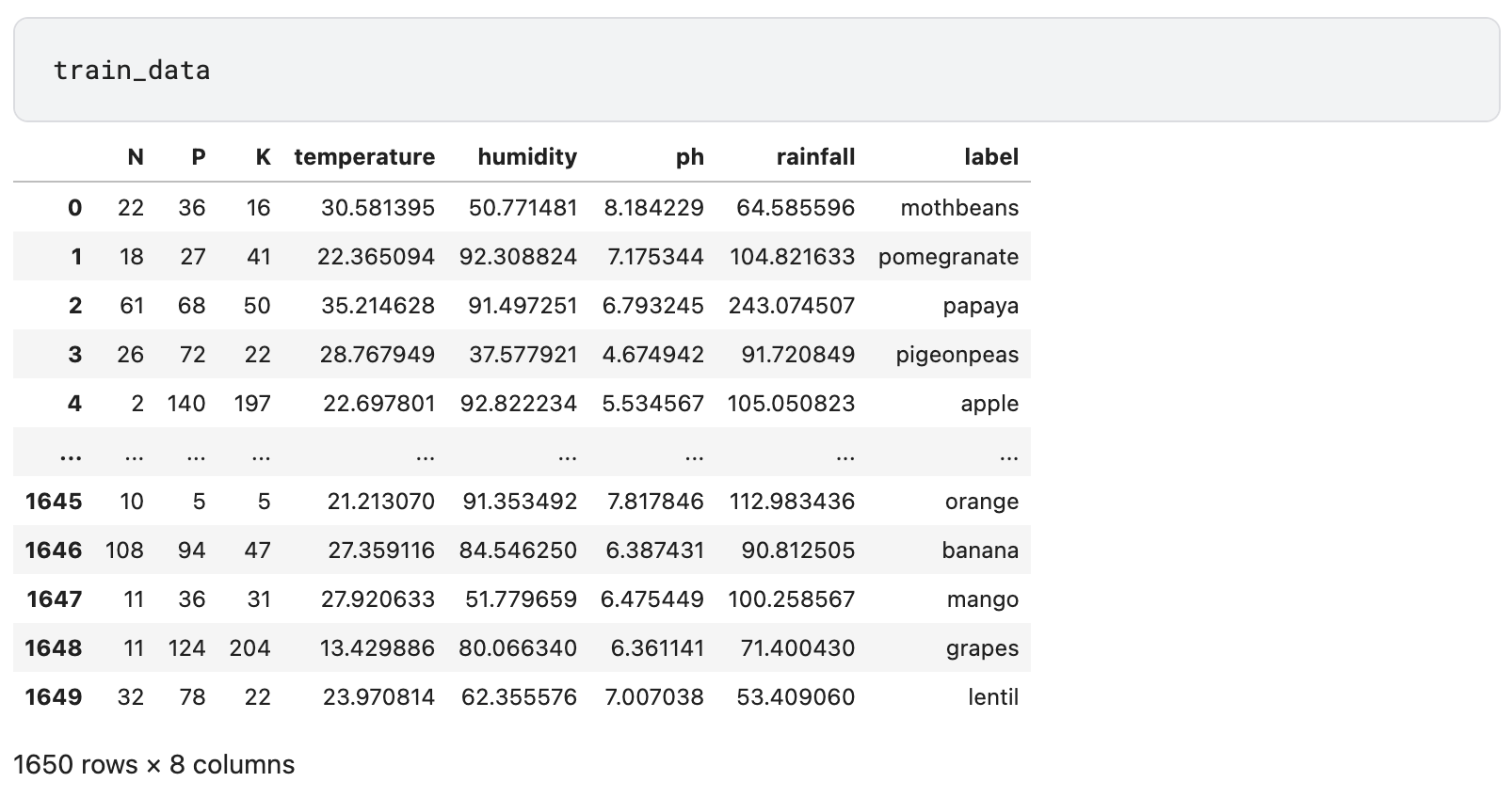
Train Data
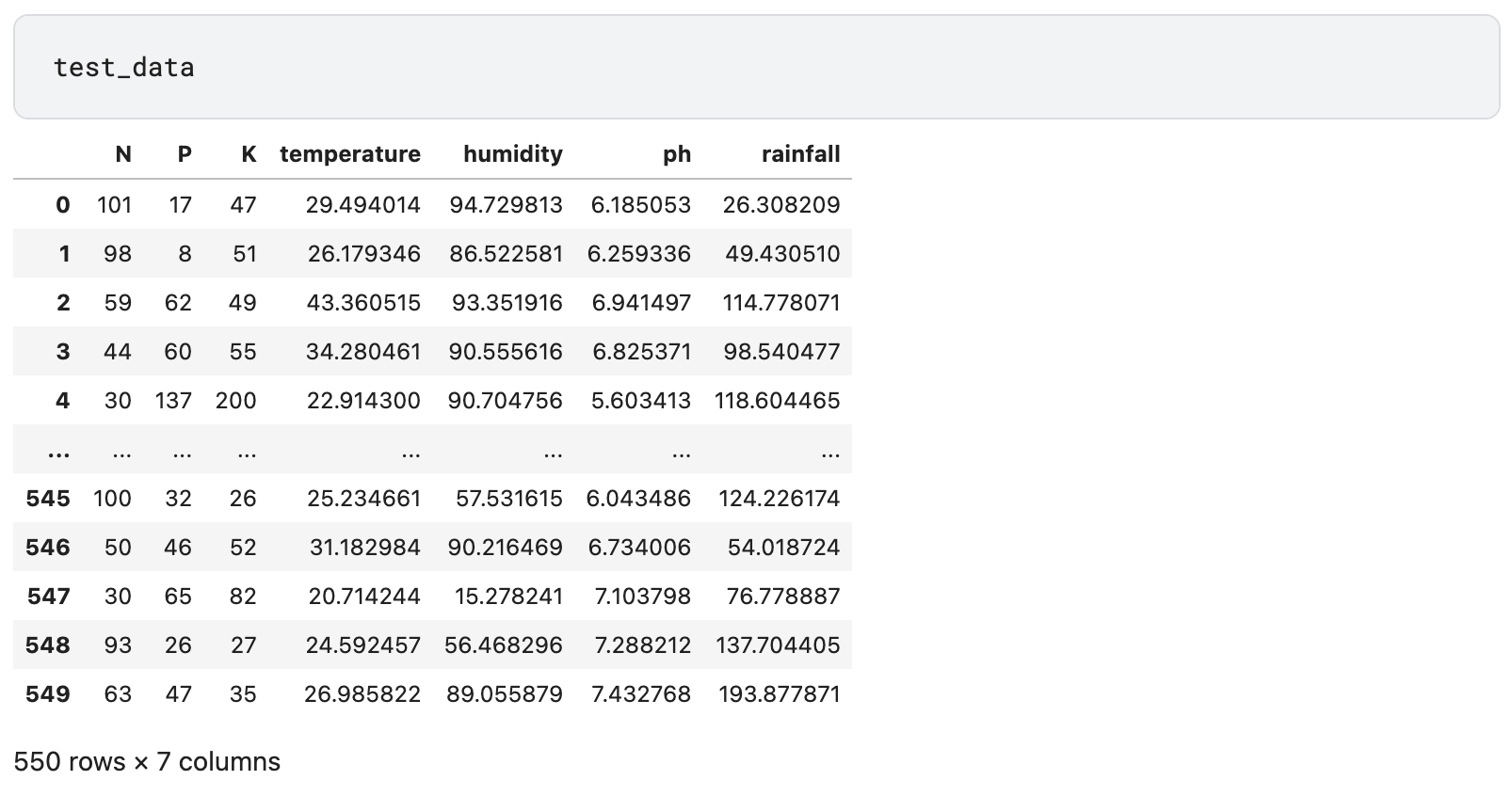
Test Data
1. Label map
label_map = list()
for label in y_train:
if label not in label_map:
label_map.append(label)y_train_label = list()
for pred in y_train:
for n,label in enumerate(label_map):
if pred is label:
y_train_label.append(n)
break
y_train = y_train_label
2. Data Normalization
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
3. Inference
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_test = list()
y_test_label = knn.predict(x_test)
for pred in y_test_label:
y_test.append(label_map[int(pred)])
4. Submission
submission = pd.read_csv('/kaggle/input/2023-ml-w4p1/sample_submit.csv')
submission['label'] = y_test
submission.to_csv('submission.csv',index = False)'Computer Science > Machine Learning' 카테고리의 다른 글
| Linear Regression : Multi Linear Regression (1) (0) | 2024.03.23 |
|---|---|
| KNN(K-Nearest Neighbors) [자동차 가격 예측] (5) (0) | 2024.03.23 |
| KNN(K-Nearest Neighbors) [영화 평점 예측] (3) (0) | 2024.03.22 |
| KNN(K-Nearest Neighbors) (2) (0) | 2024.03.22 |
| KNN(K-Nearest Neighbors) (1) (0) | 2024.03.21 |



