
0. 분류와 회귀
(1) 지도학습의 대표적인 머신러닝 방법
- 분류 (classification)
- 회귀 (regression)
(2) Classification
미리 정의된 여러 class label 중 하나를 예측
(ex. 얼굴인식, 숫자판별(MNIST) 등)
- Binary classification(이진 분류) : 두 class로 분류
- Multiclass classification(다중 분류) : 셋 이상의 class로 분류
(3) Regression
연속적인 숫자 또는 부동소수점수(실수)를 예측하는 것
(ex. 주식 가격을 예측하여 수익을 내는 알고리즘 등)
1. KNN의 개념
(1) KNN이란?
게으른 학습(lazy learner) 또는 사례 중심 학습(instance-based learning)
게으른 학습
알고리즘은 훈련 데이터에서 판별 함수를 학습하는 대신 훈련 데이터셋을 메모리에 저장하기 위한 방법
데이터 차원이 증가하면, 차원의 저주(curse of demension) 문제가 발생 → 성능 저하
차원의 저주
데이터의 차원이 증가할수록 해당 공간의 크기 (부피)가 기하급수적으로 증가하여 동일한 개수의 데이터 밀도(sparse)는 차원이 증가할수록 희박해진다. 이 때문에, 데이터 분포 분석에 필요한 샘플 데이터의 개수가 지하급수적으로 증가하게 되는 어려움을 표현한 용어이다.
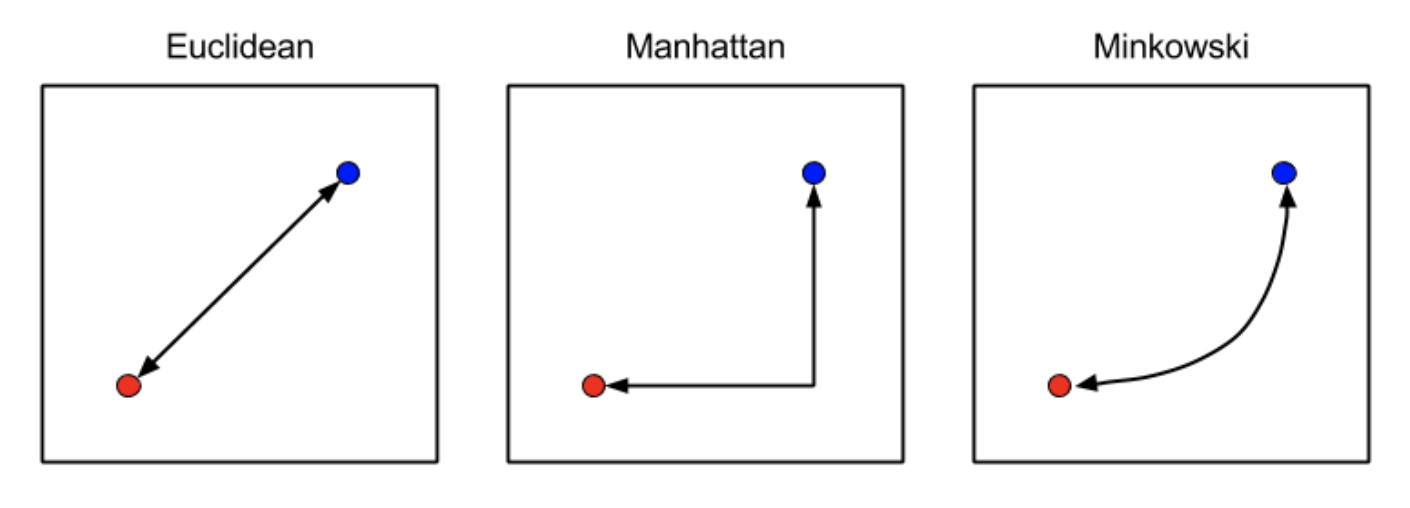
i번째 관측치와 j번째 관측치의 거리로 Minkowski 거리를 이용
$ d(x_i, x_j) = \sqrt[p]{\sum_{k=1}^{d}|x_{ik}-x_{jk}|^p}$
2. KNN의 하이퍼파라미터
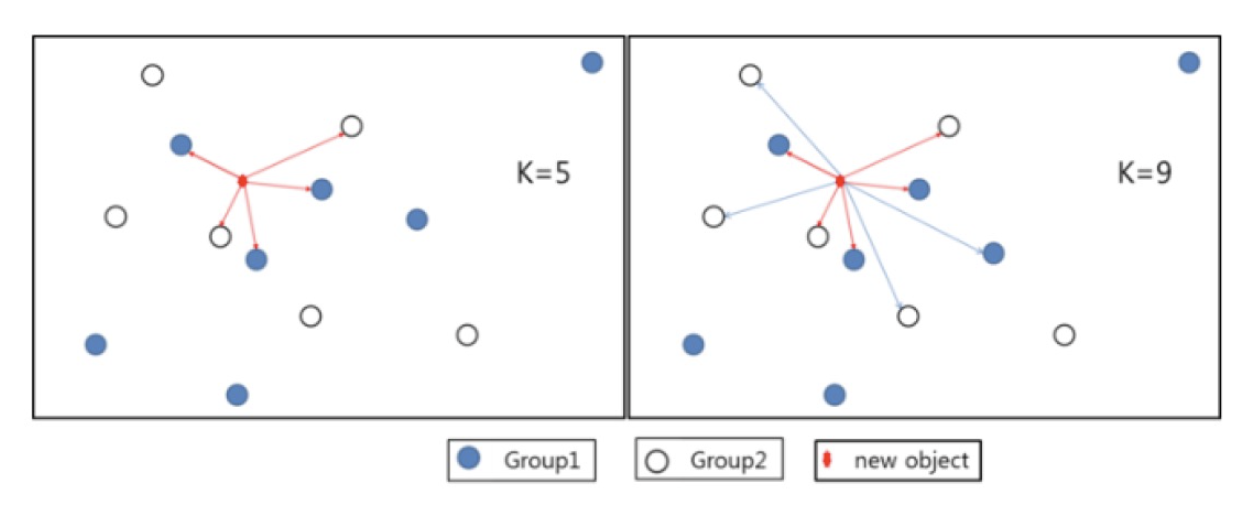
탐색할 이웃 수(k)와 거리 측정 방법
- k가 작을수록 데이터의 지역적 특성을 지나치게 반영하여 과접합(overfitting) 발생
- 반대로 매우 클 경우 과소적합(underfitting) 발생
3. KNN의 K가 가지는 의미
새로운 자료에 대해 근접치 K의 개수에 따라 group이 달리 분류됨
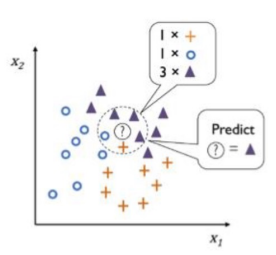
- 다수결 방식 (Majority Voting) : 이웃 범주 가운데 빈도 기준으로 제일 많은 범주로 새 데이터의 범주를 예측하는 것
- 가중합 방식 (Weighted Voting) : 가까운 이웃의 정보에 좀 더 가중치를 부여
4. KNN의 장단점 요약
장점
- 학습 데이터 내에 끼어있는 노이즈에 영향을 크게 받지 않음
- 학습 데이터 수가 많다면 효과적인 알고리즘
- 데이터 분산을 고려할 경우, 매우 강건한 방법론
- Mahalanobis distance(마할라노비스 거리) : 평균과의 거리가 표준편차의 몇 배인지를 나타내는 값, 어떤 값이 얼마나 일어나기 힘든 값인지 또는 얼마나 이상한 값인지를 수치화하는 방법
단점
- 최적의 이웃의 수(k)와 어떤 거리의 척도(distance metric)가 분석에 적합한지 불분명해 데이터 각각의 특성에 맞게 연구자가 임의로 선정해야함
- 새로운 관측치와 각각의 학습 데이터 사이의 거리를 전부 측정해야 하므로 계산 시간이 오래 걸리는 한계
- KNN의 계산복잡성을 줄이려는 시도
- Locality Sensitive Hashing, Network based Indexer, Optimized product quantization
5. KNN Classification(분류)
분류 문제는 회귀 분석과 달리 다양한 성능 평가 기준(metric)이 필요
평가방법마다 장단점 존재
- confusion_matrix(y_true, y_pred)
- accuracy_score(y_true, y_pred)
- precision_score(y_true, y_pred)
- recall_score(y_true, y_pred)
- fbeta_score(y_true, y_pred, beta)
- f1_score(y_true, y_pred)
- roc_curve
- auc
6. KNN Regression(회귀)
(1) 정의
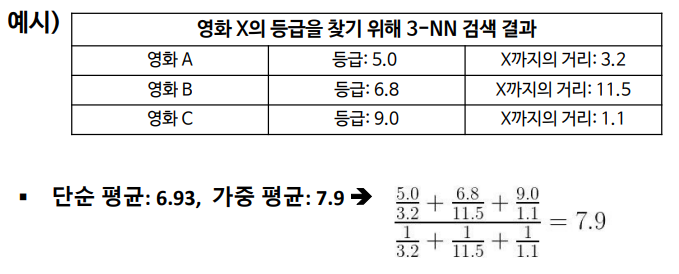
- KNN regression도 $y$의 예측치 계산을 제외한 나머지가 KNN classification과 동일
- K개 관측치 $(x_i,y_i)$에서 $ \overline{y}$를 계산하여 적합치로 사용
- 주어진 특성 변수 x에 대응하는 y의 예측치
- $\frac{1}{k}\sum_{i=1}^{k}y_i$ (단, $y_i$는 x에 가장 가까운 K개의 학습 데이터 y)
(2) 종류
단순 회귀
가까운 이웃들의 단순한 평균을 구하는 방식
가중 회귀 (Weighted regression)
각 이웃이 얼마나 가까이 있는지에 따라 가중 평균(weighted average)을 구해 거리가 가까울수록 데이터가 유사할 것이라고 보고 가중치를 부여하는 방식
'Study > Machine Learning' 카테고리의 다른 글
| Linear Regression : Multi Linear Regression (1) (0) | 2024.03.23 |
|---|---|
| KNN(K-Nearest Neighbors) [자동차 가격 예측] (5) (0) | 2024.03.23 |
| KNN(K-Nearest Neighbors) [재배환경 별 작물 종류 예측] (4) (1) | 2024.03.23 |
| KNN(K-Nearest Neighbors) [영화 평점 예측] (3) (0) | 2024.03.22 |
| KNN(K-Nearest Neighbors) (2) (0) | 2024.03.22 |



