
1. 회귀나무
입력 데이터(변수 값)의 결과 예측
- 데이터가 도달한 끝 노드 데이터들의 평균으로 결정
불순도 측정 방법
- 제곱 오차 합 (the sum of the squared errors)
- 오차 = 실제 값 - 예측 값
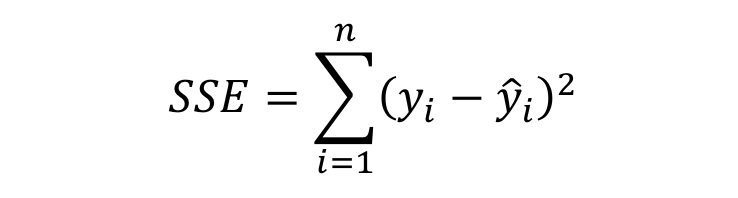
성능 평가 방법
- 예측 모델 평가 방법 : RMSE
2. 앙상블 (Ensemble)
(1) 앙상블
- 여러 모델(의사결정나무, KNN, LDA, 로지스틱 등)을 함께 사용
- 설명보다는 예측이 중요할 경우 사용
- 예측 알고리즘을 조합하여 예측 성능을 향상
- 랜덤포레스트(Random Forest), Boosted Trees
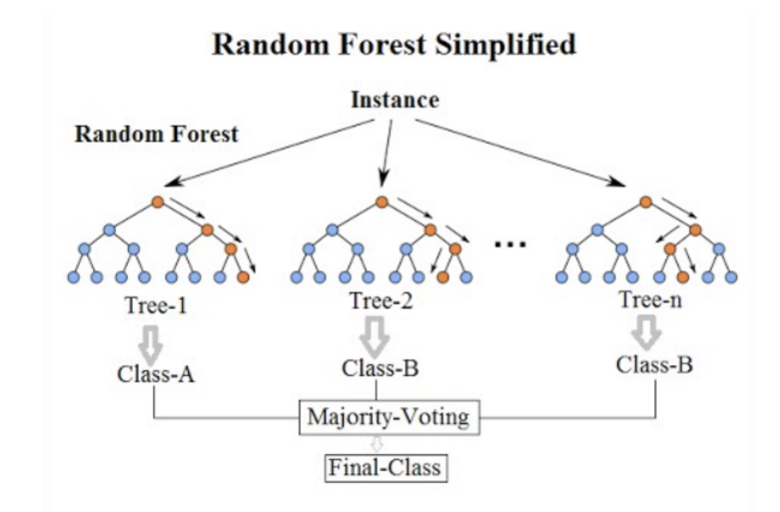
(2) Random Forest
Boostrap 사용
- 데이터로부터 복원 추출(뽑은 표본 원복)을 이용하여 여러 샘플을 추출
Forest 생성
- 무작위로 예측 변수를 선택하여 모델 구축
- 의사결정나무는 예측 변수 선택시 기준 지표를 사용하였으나 랜덤포레스트에서는 무작위로 선택함
앙상블 결과 집합
- 분류문제 → 투표
- 예측문제 → 평균화
나무 구조이지만 숲이 되면서 해석 가능한 모델의 장점은 사라짐
그러나 결과 분석을 통해 설명 변수 중 중요한 변수 판별 가능
'Computer Science > Machine Learning' 카테고리의 다른 글
| Linear SVM : Soft Margin SVM (2) (0) | 2024.06.09 |
|---|---|
| Linear SVM : Hard Margin SVM (1) (1) | 2024.06.09 |
| 의사결정나무(Decision Tree) (2) (0) | 2024.06.09 |
| 의사결정나무(Decision Tree) (1) (1) | 2024.06.09 |
| 데이터 전처리 [통신사 고객 이탈 예측 문제] (3) (0) | 2024.06.09 |



