
1. 의사결정나무
(1) 정의
- 학습 데이터를 분석하여 데이터에 내재되어 있는 패턴을 새롭게 관측된 데이터를 예측 및 분류하는 모델
- 개념적으로 질문을 던져서 대상을 좁혀 나가는 '스무고개'와 비슷한 개념
- 목적(Y)과 자료(X)에 따라 적절한 분리 기준과 정지 규칙을 지정하여 의사결정나무를 생성
- 의사결정방식 과정의 표현법이 나무와 같다고 해서 의사결정나무라 불림
- 의사결정 규칙을 나무 모델로 표현

(2) 의사결정나무의 장점
- 이해하기 쉽고 적용하기 쉬움
- 의사결정과정에 대한 설명(해석) 가능
- 중요한 변수 선택에 유용 (상단에서 상용된 설명 변수가 중요한 변수)
- 데이터의 통계적 가정이 필요 없음 (ex. LDA 가정: 데이터 정규성)

(3) 의사결정나무의 단점
- 좋은 모형을 만들기 위해 많은 데이터가 필요
- 모형을 만드는데 상대적으로 시간이 많이 소요 (Tree building)
- 데이터의 변화에 민감 (데이터에 따라 모델이 변화함)
- 학습과 테스트 데이터의 도메인이 유사해야함 (domain gap이 작아야함)
- 선형구조형 데이터 예측시 더 복잡
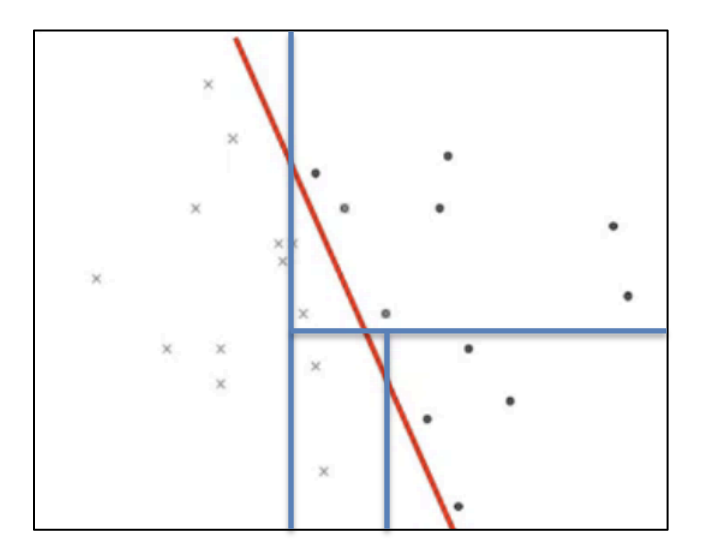
2. 의사결정나무를 활용한 데이터 분석
순서
데이터 → 모델 학습 → 추론
데이터
다변량 변수 사용
모델 학습 (트리 구조 이용)
① 한번에 설명 변수 하나씩 데이터에 접근
② 2개 혹은 그 이상의 부분집합으로 분할
③ 데이터의 순도가 균일해지도록 재귀적 분할(recursive paritiioning)
(재귀적 분할 종료 조건)
분류 문제 : 끝 노드에 비슷한 범주(클래스)를 갖고 있는 관측 데이터
예측 문제 : 끝 노드에 비슷한 수치(연속된 값)를 갖고 있는 관측 데이터
추론 (판별)
분류 : 끝 노드에서 가장 빈도가 높은 종속변수(y)를 새로운 데이터에 부여
회귀 : 끝 노드의 종속변수(y)의 평균을 예측값으로 반환
3. 알고리즘
(1) 재귀적 분할 알고리즘
CART (Classification And Regression Tree)
C4.5, C5.0
CHAID (Chi-square Automatic Interaction Detection)
(2) 불순도 알고리즘 (분할 기준)
지니 지수 (Gini index)
엔트로피 지수(Entropy index), 정보 이익(Information Gain)
카이제곱 통계량 (Chi-Square Statistic)
4. 구분
(1) 분류 나무 (Classifiaction Tree)
목표 변수: 범주형 데이터 (분류)
분류 알고리즘과 불순도 지표
- CART: 지니 지수 (Gini Index)
- C4.5: 엔트로피(Entropy index), 정보 이익(Information gain), 정보이익비율(Information gain ratio)
- CHAID: 카이 제곱 통계량 (Chi-Square statistic)
분류 결과 (판별, 추론)
- 소속 집단 판단, 경향성도 확률로 표현 가능
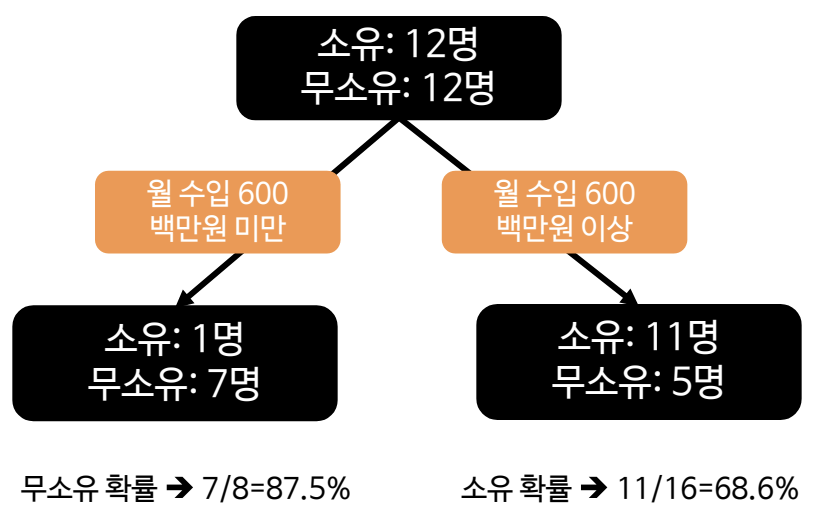
(2) 회귀 나무 (Regression Tree)
목표 변수: 수치형 변수 (예측)
회귀 알고리즘과 불순도 지표
- CART: F 통계량과 분산 감소량 (실제 값과 예측 값의 평균 차이가 작도록)
회귀 결과
- 끝 마디 집단의 평균
- 예측일 경우 회귀나무보다 신경망 또는 회귀분석이 더 좋음
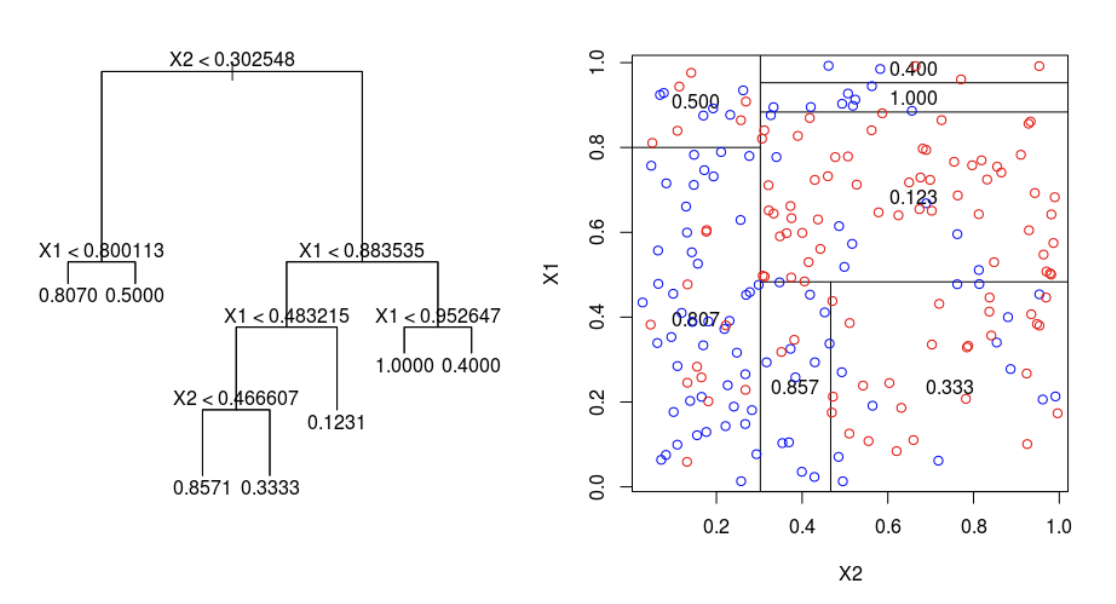
5. 분할

(1) 이진 분할
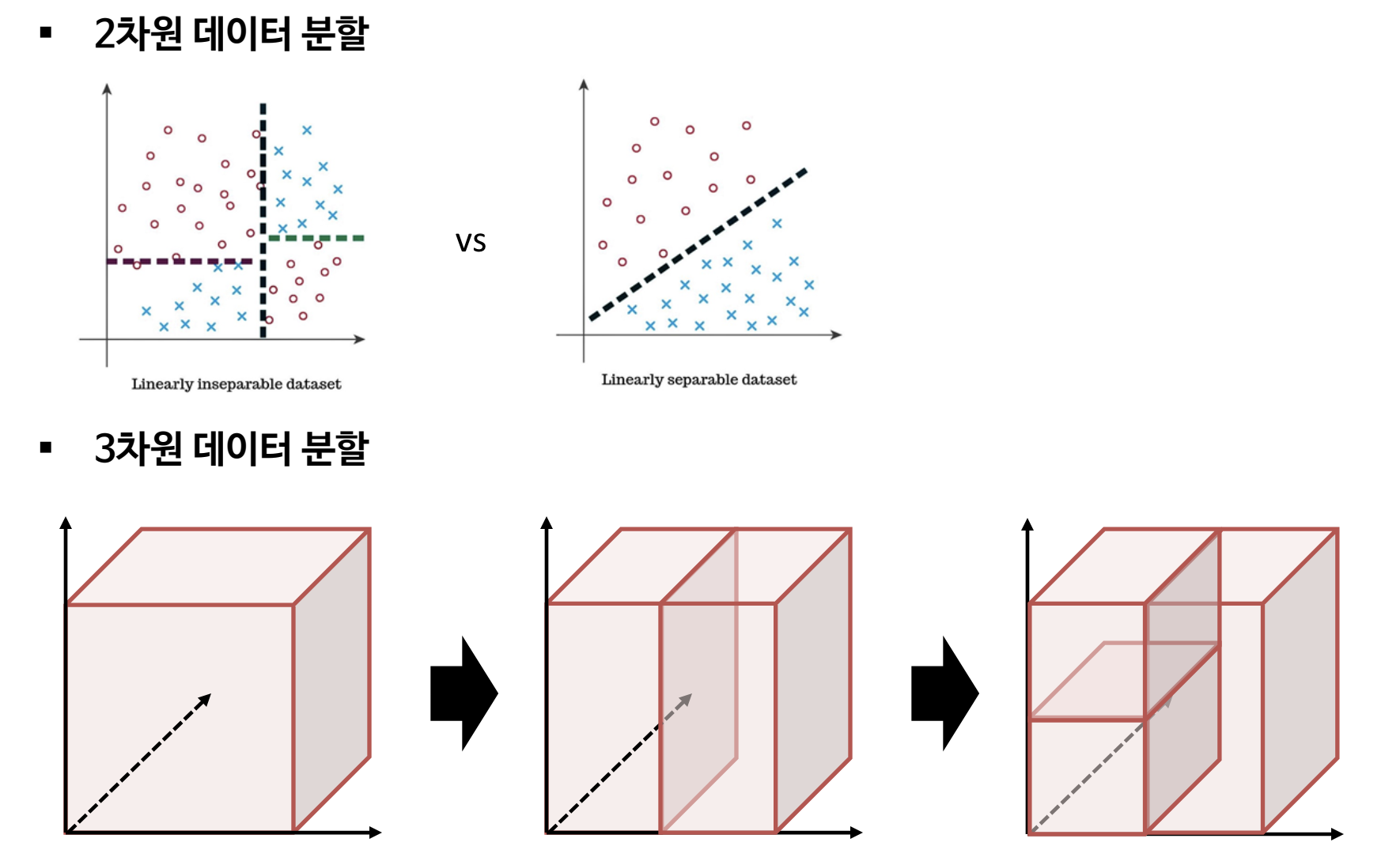
(2) 트리 구조를 이용한 데이터 분할 표현법

'Computer Science > Machine Learning' 카테고리의 다른 글
| 의사결정나무(Decision Tree) (3) (1) | 2024.06.09 |
|---|---|
| 의사결정나무(Decision Tree) (2) (0) | 2024.06.09 |
| 데이터 전처리 [통신사 고객 이탈 예측 문제] (3) (0) | 2024.06.09 |
| 데이터 전처리 [이직을 희망하는 직원 예측 문제] (2) (0) | 2024.06.09 |
| 데이터 전처리 (1) (0) | 2024.06.09 |



