
1. Data Preprocessing
(1) Train과 Test 데이터 자료형 확인
train.info()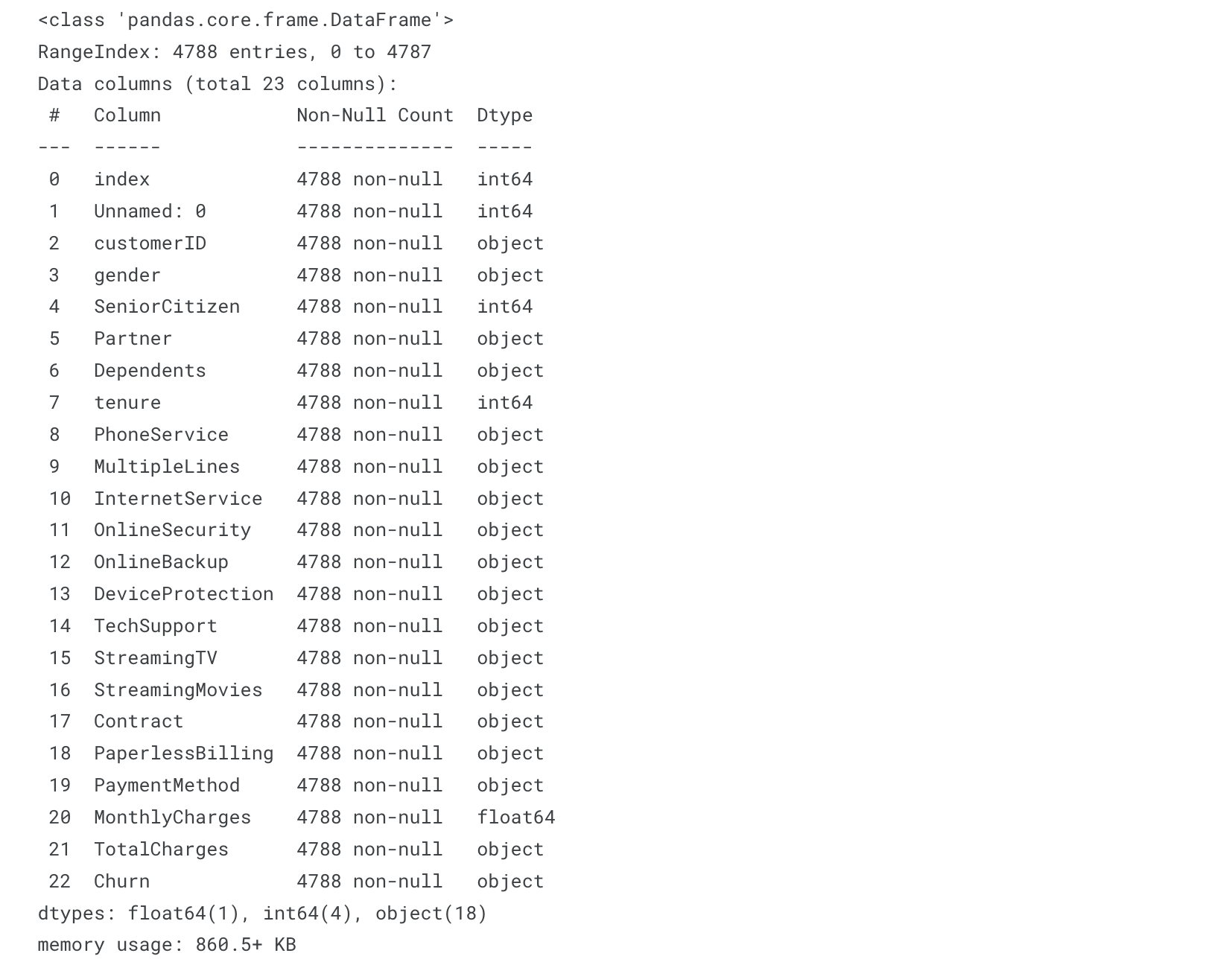
test.info()
(2) Churn
y_train, y_test에 들어갈 자료로, label encoder를 이용하여 labeling해준다.
x_train = train.drop(['Churn'], axis=1)
y_train = train['Churn']
x_test = testle = LabelEncoder()
y_train = le.fit_transform(y_train)y_train = pd.DataFrame(y_train)
(3) index, Unnamed: 0, customerID
예측에 영향을 끼치지 않는 정보로 삭제
x_train = x_train.iloc[:,3:]
x_test = x_test.iloc[:,3:]
(4) 자료형이 object인 데이터
자료형이 object로, label encoder를 이용하여 labeling 진행
columns = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
for column in columns:
le = LabelEncoder()
x_train[column] = le.fit_transform(x_train[column])
x_test[column] = le.transform(x_test[column])
(5) TotalCharges
x_train['TotalCharges']에서 NaN 값이 들어있는 부분을 제외하고 학습
(x_train['TotalCharges'] == ' ').sum() # NaN 값의 개수 : 10
train과 test 데이터의 자료형이 달라, test 데이터와 같이 train 데이터의 자료형을 object에서 float64로 맞춤
drop_idx = x_train[x_train['TotalCharges'] == ' '].index
x_train = x_train.drop(drop_idx, axis=0)
y_train = y_train.drop(drop_idx, axis=0)
x_train['TotalCharges'] = x_train['TotalCharges'].astype('float64')
(6) Train과 Test 데이터 자료형 확인
x_train.info()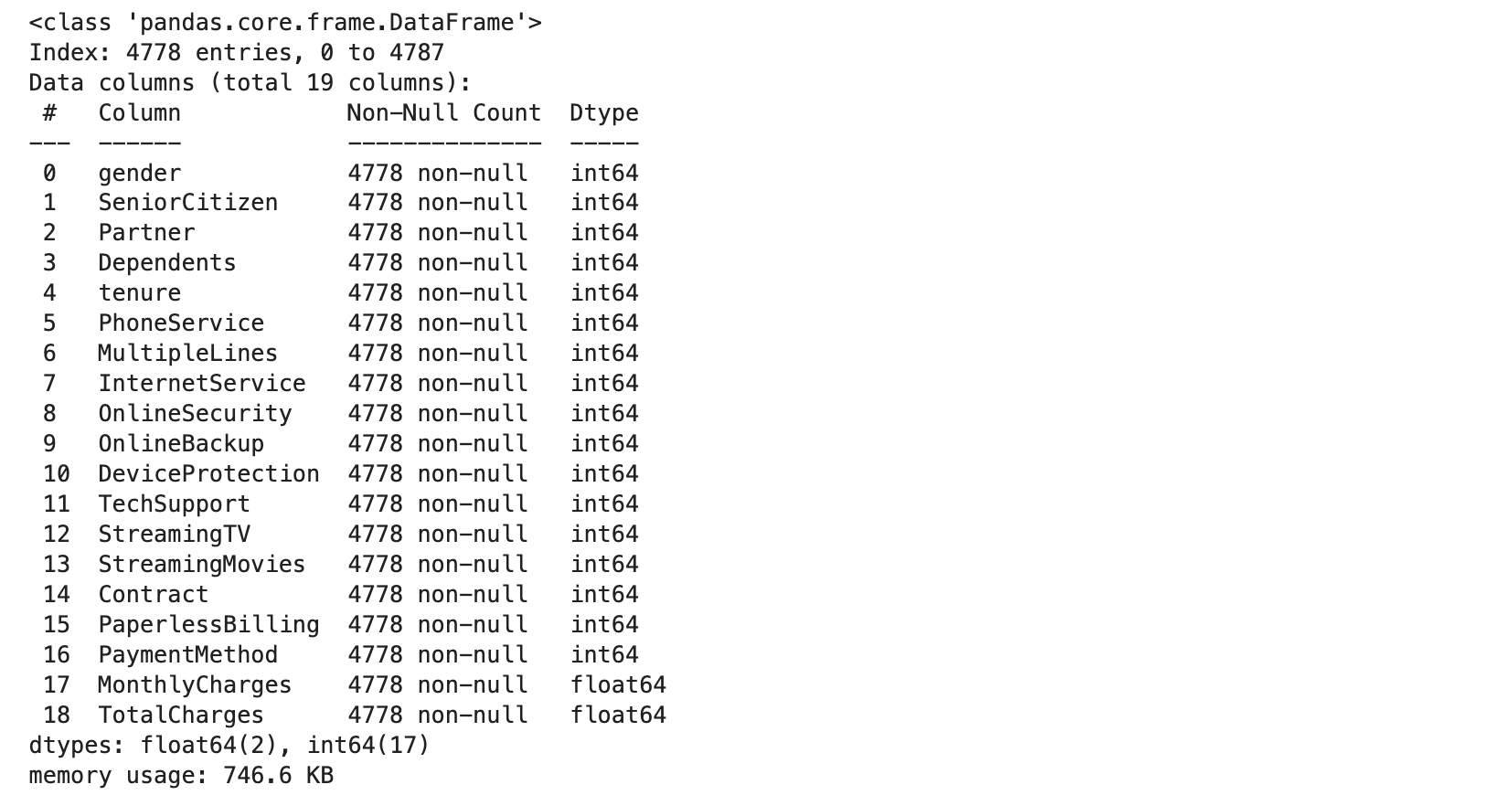
x_test.info()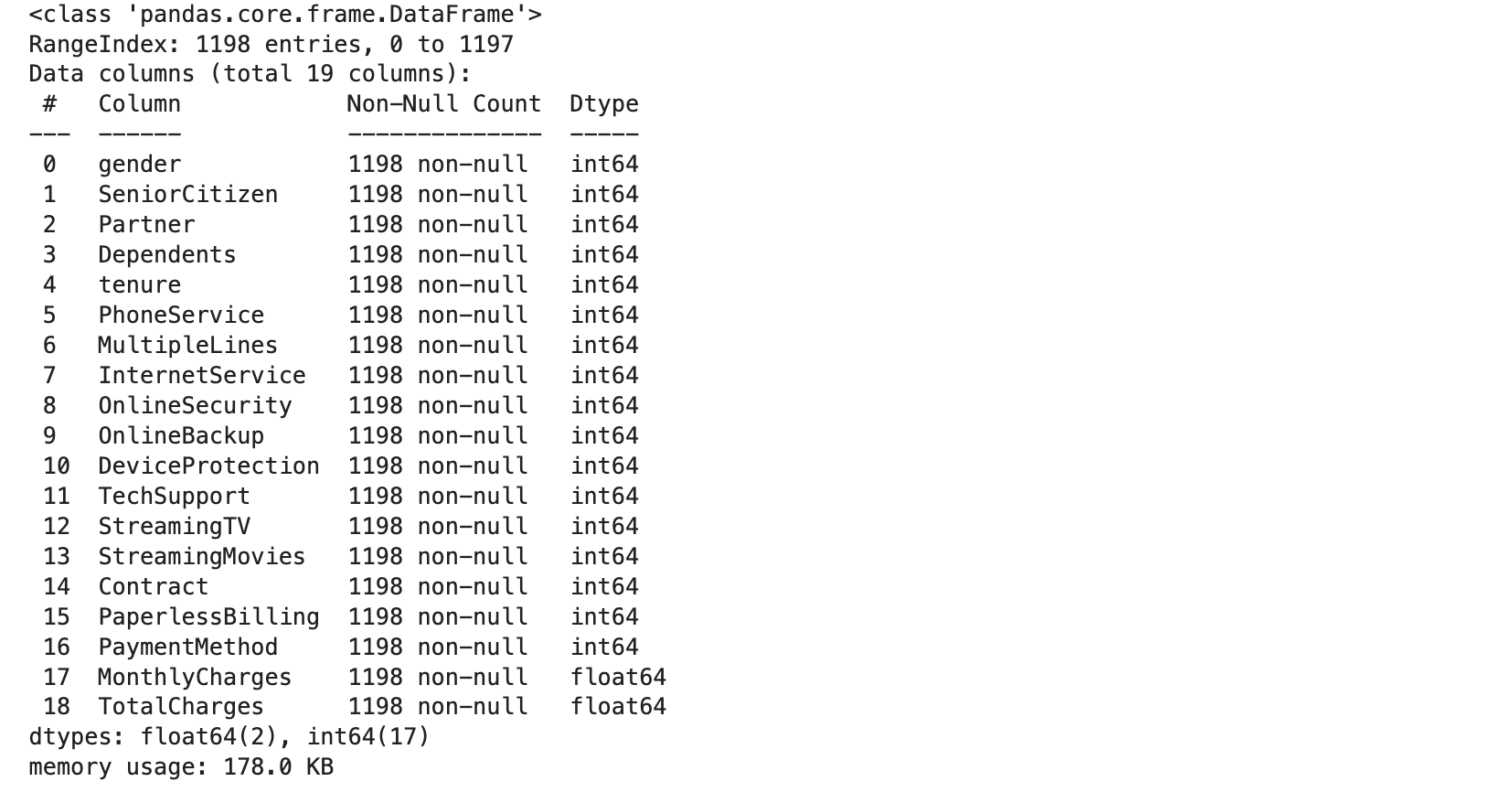
2. Train & Test
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=1000)
clf.fit(x_train, y_train)
y_test = clf.predict(x_test)'Computer Science > Machine Learning' 카테고리의 다른 글
| 의사결정나무(Decision Tree) (2) (0) | 2024.06.09 |
|---|---|
| 의사결정나무(Decision Tree) (1) (1) | 2024.06.09 |
| 데이터 전처리 [이직을 희망하는 직원 예측 문제] (2) (0) | 2024.06.09 |
| 데이터 전처리 (1) (0) | 2024.06.09 |
| 군집화(Clustering) (1) (0) | 2024.06.08 |



