
1. Data Preprocessing
(1) Train과 Test 데이터의 자료형 확인
train.info()
test.info()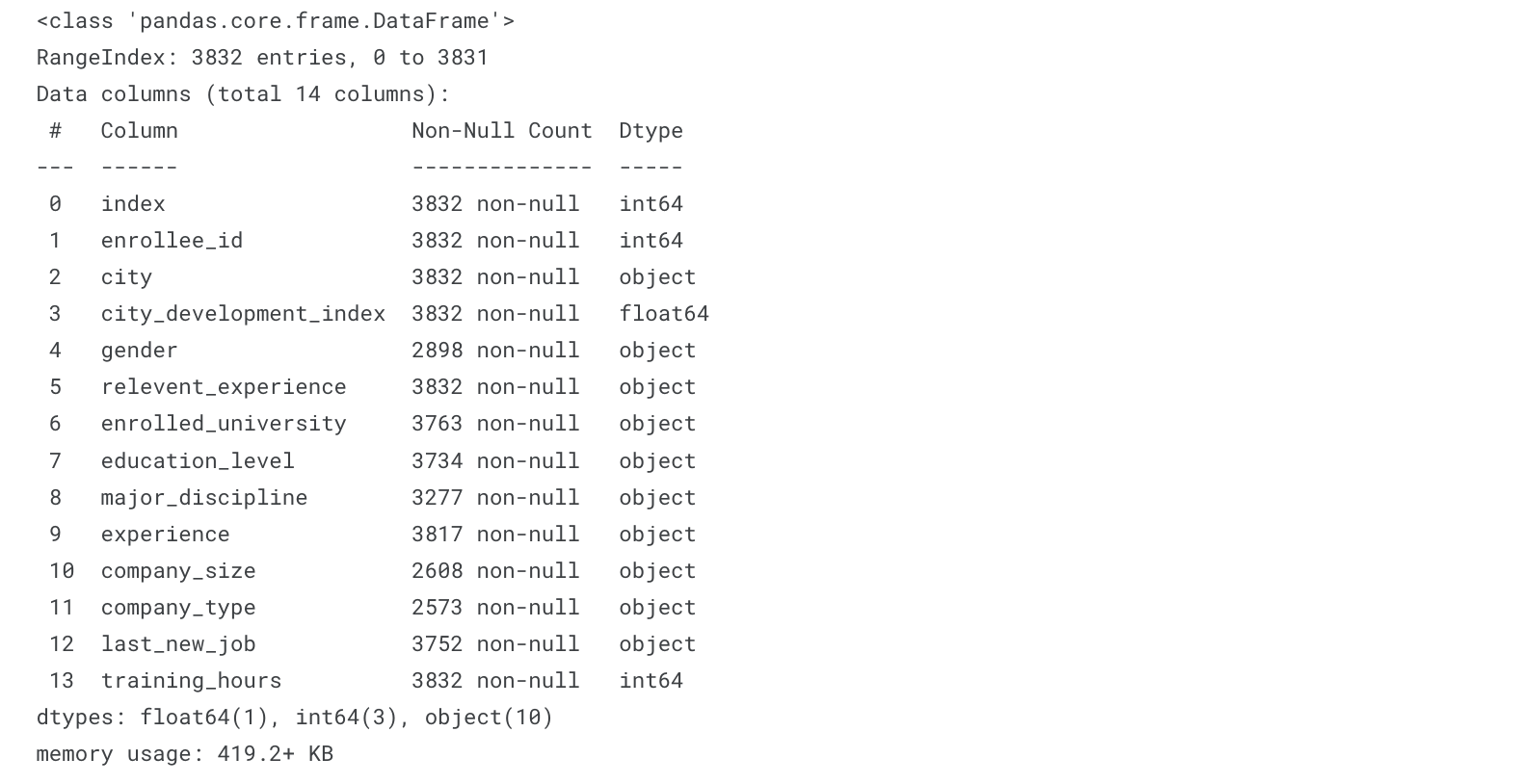
(2) index, enrolled_id, city
예측에 영향을 끼치지 않는 정보로 삭제
# index, enrollee_id, city 지우기
x_train = x_train.iloc[:,3:]
x_test = x_test.iloc[:,3:]
(3) gender, relevent_experience, enrolled_university, education_level, major_discipline, company_type, training_hours
자료형이 object로, label encoder를 이용하여 labeling 진행
# gender
le = LabelEncoder()
x_train['gender'] = le.fit_transform(x_train['gender'])
x_test['gender'] = le.transform(x_test['gender'])
# relevent_experience
le = LabelEncoder()
x_train['relevent_experience'] = le.fit_transform(x_train['relevent_experience'])
x_test['relevent_experience'] = le.transform(x_test['relevent_experience'])
# enrolled_university
le = LabelEncoder()
x_train['enrolled_university'] = le.fit_transform(x_train['enrolled_university'])
x_test['enrolled_university'] = le.transform(x_test['enrolled_university'])
# education_level
le = LabelEncoder()
x_train['education_level'] = le.fit_transform(x_train['education_level'])
x_test['education_level'] = le.transform(x_test['education_level'])
# major_discipline
le = LabelEncoder()
x_train['major_discipline'] = le.fit_transform(x_train['major_discipline'])
x_test['major_discipline'] = le.transform(x_test['major_discipline'])
# company_type
le = LabelEncoder()
x_train['company_type'] = le.fit_transform(x_train['company_type'])
x_test['company_type'] = le.transform(x_test['company_type'])
# training_hours
le = LabelEncoder()
x_train['training_hours'] = le.fit_transform(x_train['training_hours'])
x_test['training_hours'] = le.transform(x_test['training_hours'])
(3) experience
x_train['experience'].unique()
# experience (train)
xx = x_train['experience'].copy()
xx[xx == '>20'] = 21
xx[xx == '<1'] = 0
xx[xx.isnull()] = -1
x_train['experience'] = xx.astype('int64')# experience (test)
xx = x_test['experience'].copy()
xx[xx == '>20'] = 21
xx[xx == '<1'] = 0
xx[xx.isnull()] = -1
x_test['experience'] = xx.astype('int64')
(4) company_size
x_train['company_size'].unique()
# company_size (train)
xx = x_train['company_size'].copy()
xx[xx == '10000+'] = 1
xx[xx == '5000-9999'] = 2
xx[xx == '1000-4999'] = 3
xx[xx == '500-999'] = 4
xx[xx == '100-500'] = 5
xx[xx == '50-99'] = 6
xx[xx == '10/49'] = 7
xx[xx == '<10'] = 8
xx[xx.isnull()] = -1
x_train['company_size'] = xx.astype('int64')# company_size (test)
xx = x_test['company_size'].copy()
xx[xx == '10000+'] = 1
xx[xx == '5000-9999'] = 2
xx[xx == '1000-4999'] = 3
xx[xx == '500-999'] = 4
xx[xx == '100-500'] = 5
xx[xx == '50-99'] = 6
xx[xx == '10/49'] = 7
xx[xx == '<10'] = 8
xx[xx.isnull()] = -1
x_test['company_size'] = xx.astype('int64')
(5) last_new_job
x_train['last_new_job'].unique()
# last_new_job (train)
xx = x_train['last_new_job'].copy()
xx[xx == '>4'] = 5
xx[xx == '4'] = 4
xx[xx == '3'] = 3
xx[xx == '2'] = 2
xx[xx == '1'] = 1
xx[xx == 'never'] = 0
xx[xx.isnull()] = -1
x_train['last_new_job'] = xx.astype('int64')# last_new_job (test)
xx = x_test['last_new_job'].copy()
xx[xx == '>4'] = 5
xx[xx == '4'] = 4
xx[xx == '3'] = 3
xx[xx == '2'] = 2
xx[xx == '1'] = 1
xx[xx == 'never'] = 0
xx[xx.isnull()] = -1
x_test['last_new_job'] = xx.astype('int64')
(7) Train과 Test 데이터의 자료형 확인
x_train.info()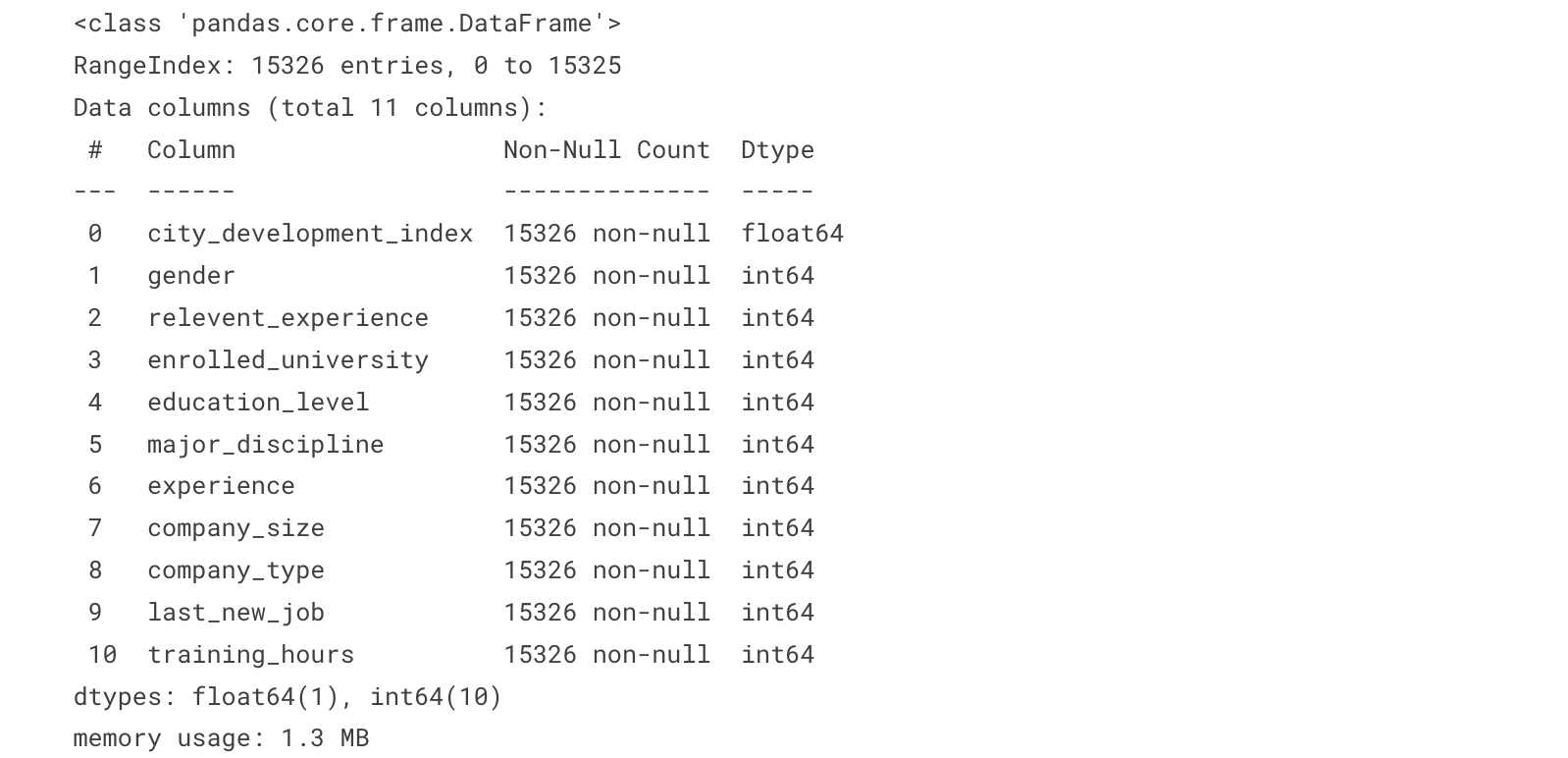
x_test.info()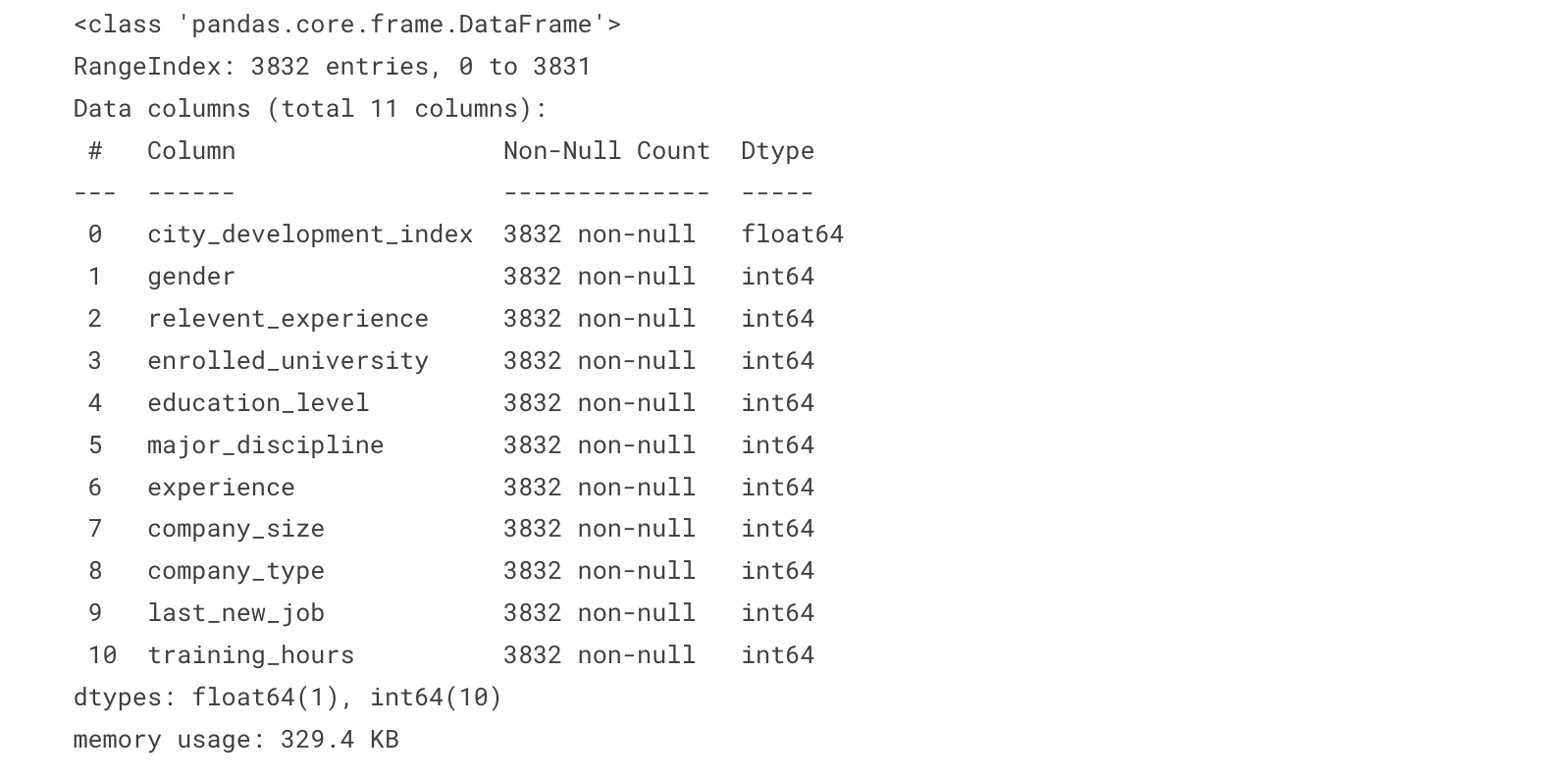
2. Train & Test
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
clf = QuadraticDiscriminantAnalysis()
clf.fit(x_train, y_train)
y_test = clf.predict(x_test).astype('int64')
'Computer Science > Machine Learning' 카테고리의 다른 글
| 의사결정나무(Decision Tree) (1) (1) | 2024.06.09 |
|---|---|
| 데이터 전처리 [통신사 고객 이탈 예측 문제] (3) (0) | 2024.06.09 |
| 데이터 전처리 (1) (0) | 2024.06.09 |
| 군집화(Clustering) (1) (0) | 2024.06.08 |
| Discriminant analysis(판별 분석) [Discriminant Analysis 이용 당뇨병 환자 예측] (4) (0) | 2024.03.31 |



