
1. 데이터 전처리 정의
(1) 정의
데이터의 품질을 올리는 과정
(2) 데이터 전처리 과정
데이터 실수화
- 컴퓨터가 이해할 수 있는 값으로의 변환
불완전한 데이터 제거
- NULL, NA, NAN 값의 제거
잡음 섞인 데이터 제거
- 가격 데이터에 있는 (-) 값 제거
- 연령 데이터 중 과도하게 큰 값 제거
모순된 데이터 제거
- 남성 데이터 중 주민번호가 '2'로 시작하는 경우
불균형 데이터 해결
- 과소표집(undersampling)
- 과대표집(oversampling)
2. 데이터 전처리 기법
데이터 실수화 (Data Verctorization)
범주형 데이터, 텍스트 자료, 이미지 자료 등을 실수로 구성된 형태로 전환하는 것
데이터 정제 (Data Cleaning)
없는 데이터는 채우고, 잡음 데이터는 제거하고, 모순 데이터를 올바른 데이터로 교정하는 것
데이터 통합 (Data Integration)
여러 개의 데이터 파일을 하나로 합치는 과정
데이터 축소 (Data Reduction)
데이터가 과도하게 큰 경우, 분석 및 학습에 시간이 오래 걸리고 비효율적이기 때문에 데이터의 수를 줄이거나(sampling), 데이터의 차원을 축소하는 작업
데이터 변환 (Data Transformation)
데이터를 정규화하거나, 로그를 씌우거나, 평균값을 계산하여 사용하거나, 사람 나이 등을 10대, 20대, 30대 등으로 구간화하는 작업
데이터 균형 (Data Balancing)
특정 클래스의 관측치가 다른 클래스에 비해 매우 낮을 경우 샘플링을 통해 클래스 비율을 맞추는 작업
3. 데이터 실수화(Data Vectorization)
(1) 정의
범주형 자료, 텍스트 자료, 이미지 자료 등을 실수로 구성된 형태로 전환한는 것
2차원 자료의 예시
- [n_smapl, n_features]
- 2차원 자료는 행렬 혹은 2차원 텐서라 불림
(2) 자료의 유형
연속형 자료 (Continuous data)
범주형 자료 (Categorical data)
텍스트 자료 (Text data)
4. 범주형 자료의 실수화
(1) One-hot encoding을 이용한 데이터 실수화
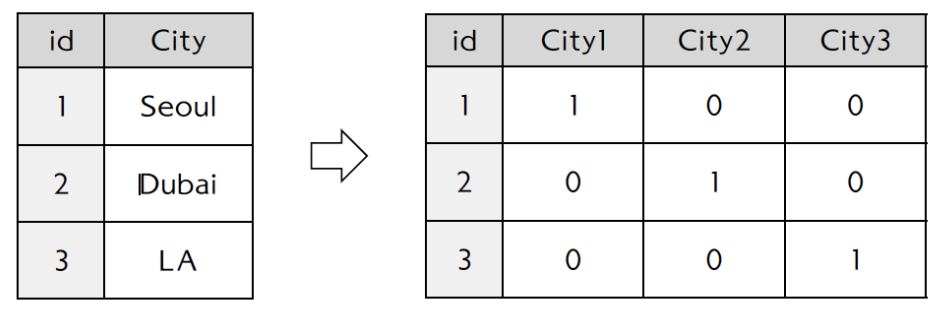
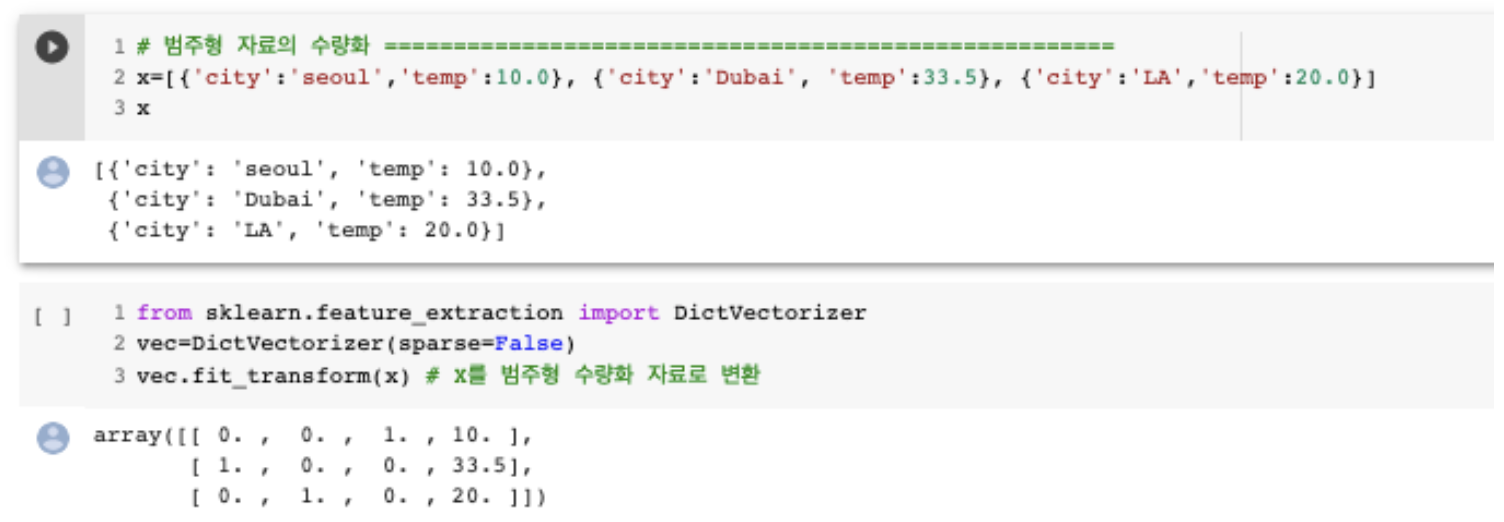
(2) Scikit-learn의 DictVectorizer 함수
- 범주형 자료를 실수화하는 함수
- Input argument: 디폴트 옵션 Sparse=True
(3) 희소행렬 (Sparse Matrix)
- 행렬의 값이 대부분 0인 경우를 가리키는 표현
- 희소행렬은 프로그램 시 불필요한 0 값으로 힌해 메모리 낭비가 심함
- 행렬의 크기가 커서 연산시 시간도 많이 소모됨
- COO 표현식과 CSR 표현식을 통해 문제 해결 가능
CSR 표현식 (Compressed Sparse Row)
COO 형식에 비해 메모리가 적게 들고 빠른 연산이 가능함

5. 텍스트 자료의 실수화
단어의 출현 횟수를 이용한 데이터 실수화
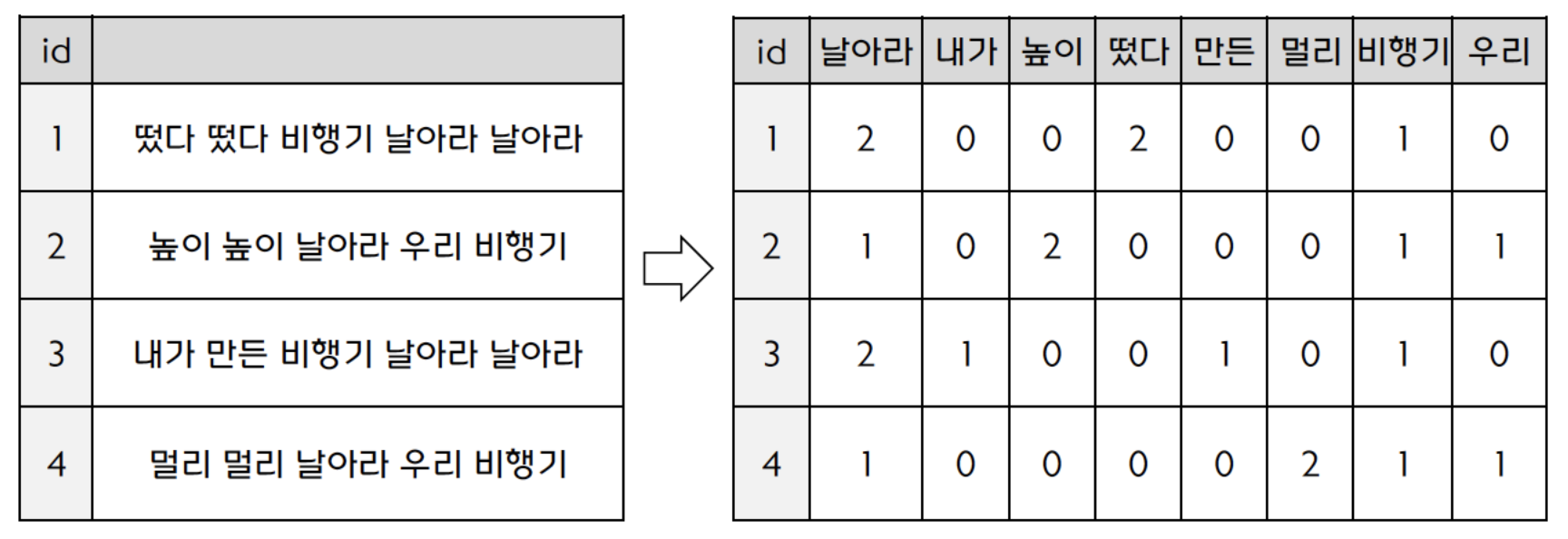
- 출현 횟수가 정보의 양과 비례하는 것은 아니므로, TF-IDF 기법을 이용해야 함
TF-IDF (Term Frequency Inverse Document Freqency)
자주 등장하여 분석에 의미를 갖지 못하는 단어의 중요도를 낮추는 기법
예) The, a 등의 관사

6. 데이터 변환 (Data Transformation)
(1) 데이터 변환의 필요성
- 머신러닝은 데이터가 가진 특성(Feature)들을 비교하여 데이터 패턴을 찾음
- 데이터가 가진 특성 간 스테일 차이가 심하면 패턴을 찾는데 문제가 발생함
(2) 데이터 변환법
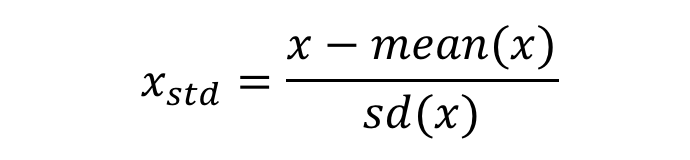
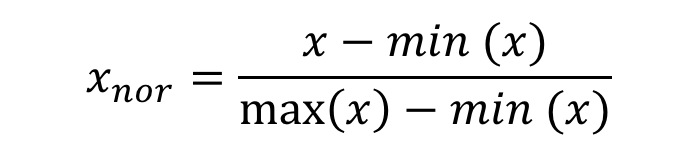
정규화가 표준화보다 유용하지만, 데이터 특성이 bell-shape이거나 이상치가 있을 경우에는 표준화가 유용함

7. 데이터 정제 (Data Cleaning)
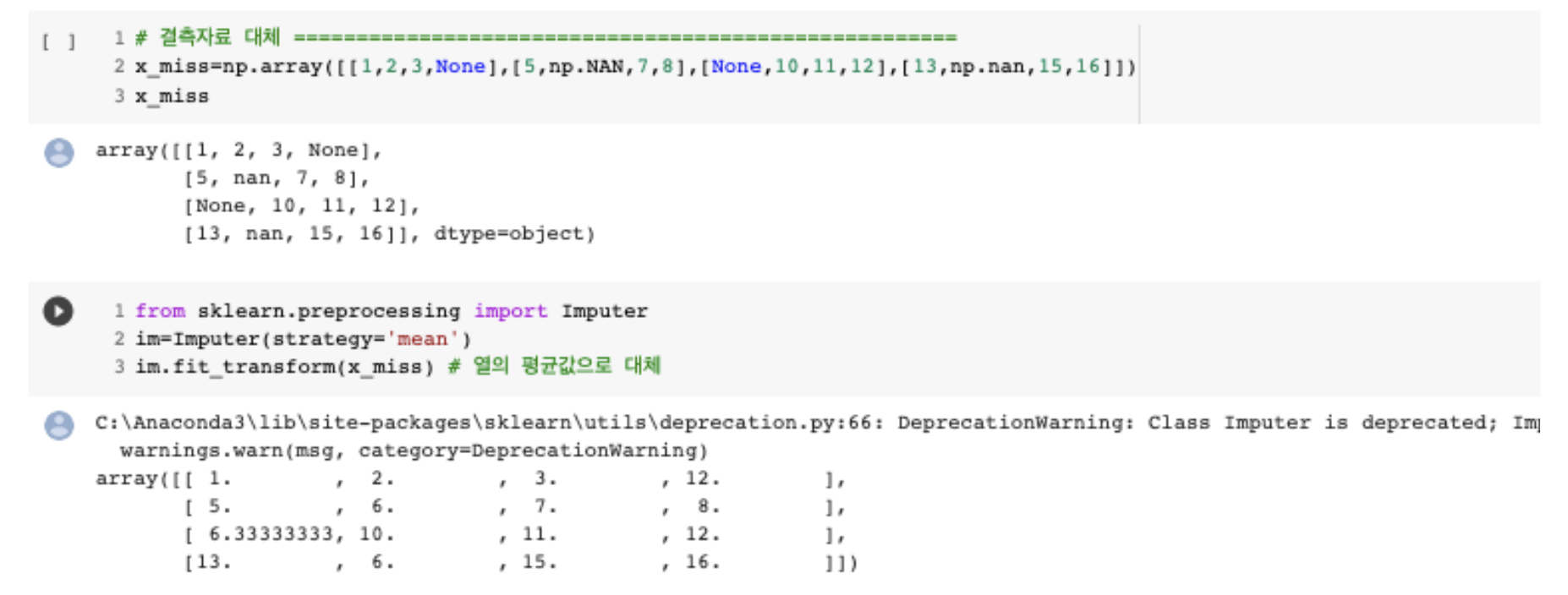
결측 제이터 채우기 (Empty Values)
- 결측 데이터: np.nan, npNaN, None
- 평균(mean), 중위수(median), 최빈수(most frequent value)로 대처하는 기법 사용
- 사용 가능 함수
sklearn의 Imputer(): 입력인자로 평균, 중위수, 최빈수 선택
8. 데이터 통합 (Data Integration)
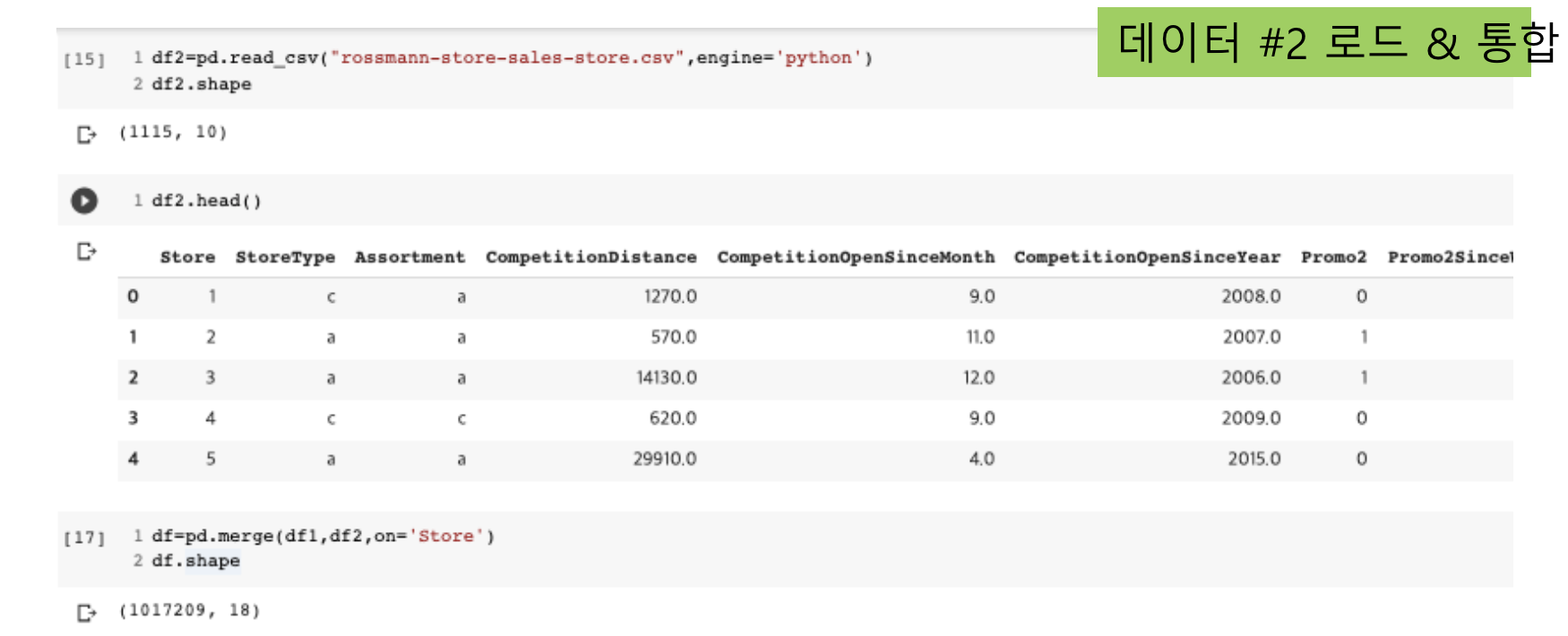
(1) 데이터 통합
- 여러 개의 데이터 파일을 하나로 합치는 과정
- pandas의 merge() 함수 사용

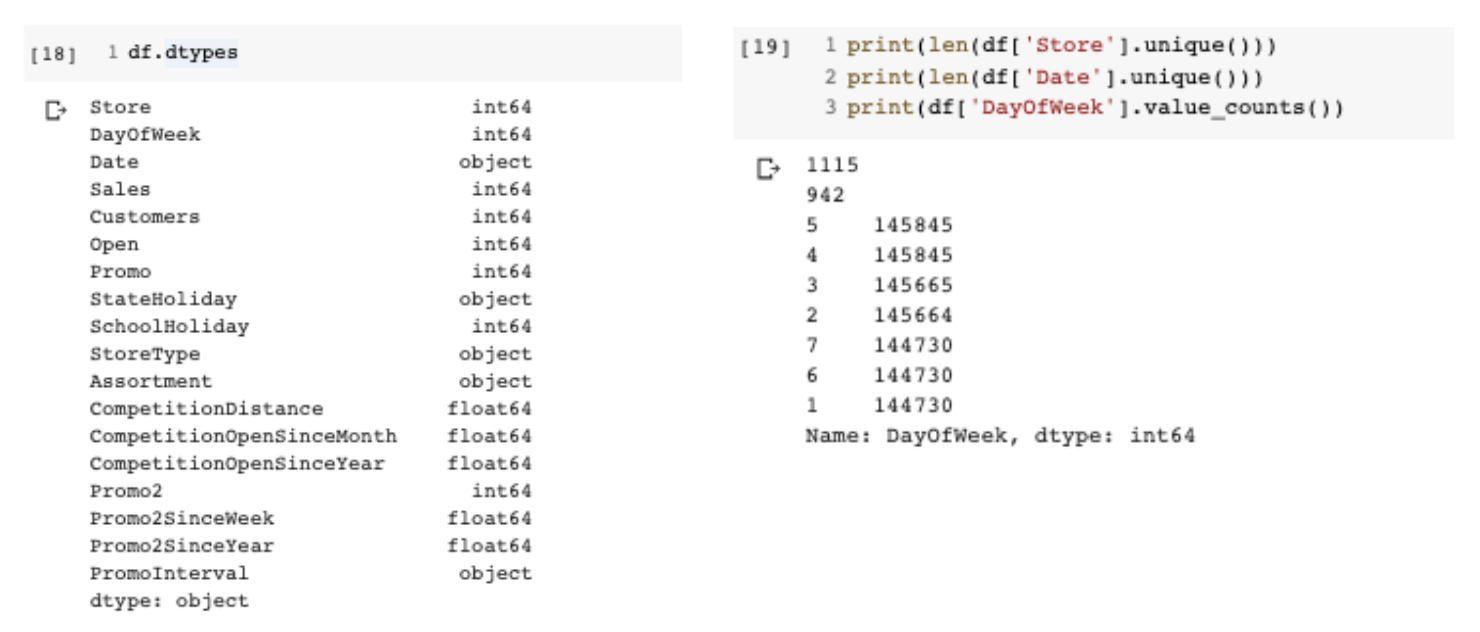
- Pandas의 df.types → 변수의 자료 타입 확인
(2) 데이터 불균형
- 머신러닝의 목적이 분류일때, 특정 클래스의 관측치가 다른 클래스에 비해 매우 낮게 나타나는 현상 (불균형 자료)
(3) 데이터 불균형 해소 기법
- 과소표집(undersampling), 과대표집(oversampling)
- 일반적으로 과소표집보다 과대표집이 통계적으로 유용함
- 의사결정나무(decision tree)와 앙상블(ensemble)은 상대적으로 불균형 자료에 강인한 특성을 보임
- 과소표집(undersampling)
다수 클래스의 표본을 임으로 학습데이터로부터 제거하는 것
- 과대표집(oversmapling)
소수 클래스의 표본을 복제하여 이를 학습데이터에 추가하는 것
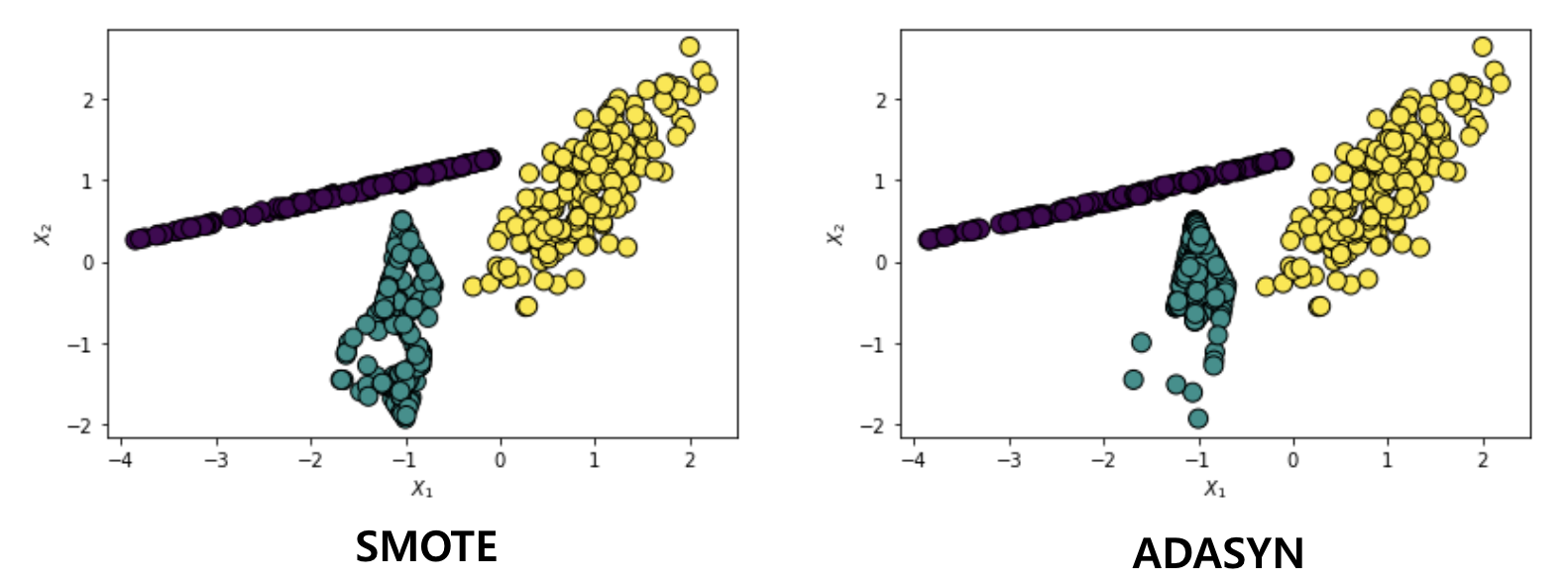
SMOTE(Synthetic minority oversampling technique), ADASYN(adaptive synthetic sampling method)



'Computer Science > Machine Learning' 카테고리의 다른 글
| 데이터 전처리 [통신사 고객 이탈 예측 문제] (3) (0) | 2024.06.09 |
|---|---|
| 데이터 전처리 [이직을 희망하는 직원 예측 문제] (2) (0) | 2024.06.09 |
| 군집화(Clustering) (1) (0) | 2024.06.08 |
| Discriminant analysis(판별 분석) [Discriminant Analysis 이용 당뇨병 환자 예측] (4) (0) | 2024.03.31 |
| Discriminant analysis(판별 분석) [Discriminant Analysis 이용 원자력발전소 상태 예측] (3) (0) | 2024.03.31 |



