
1. 군집화(Clustering)
(1) 개념
유사한 속성을 갖는 데이터를 묶어 전체 데이터를 몇 개의 군집으로 나누는 것
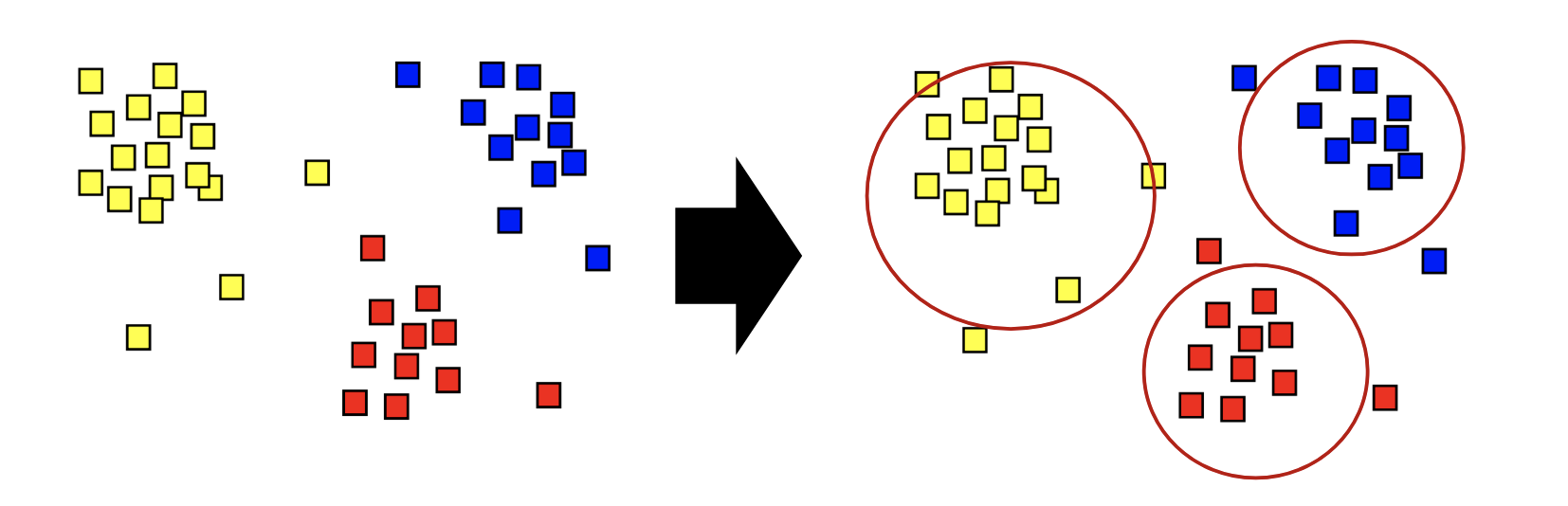
(2) 좋은 군집화의 기준
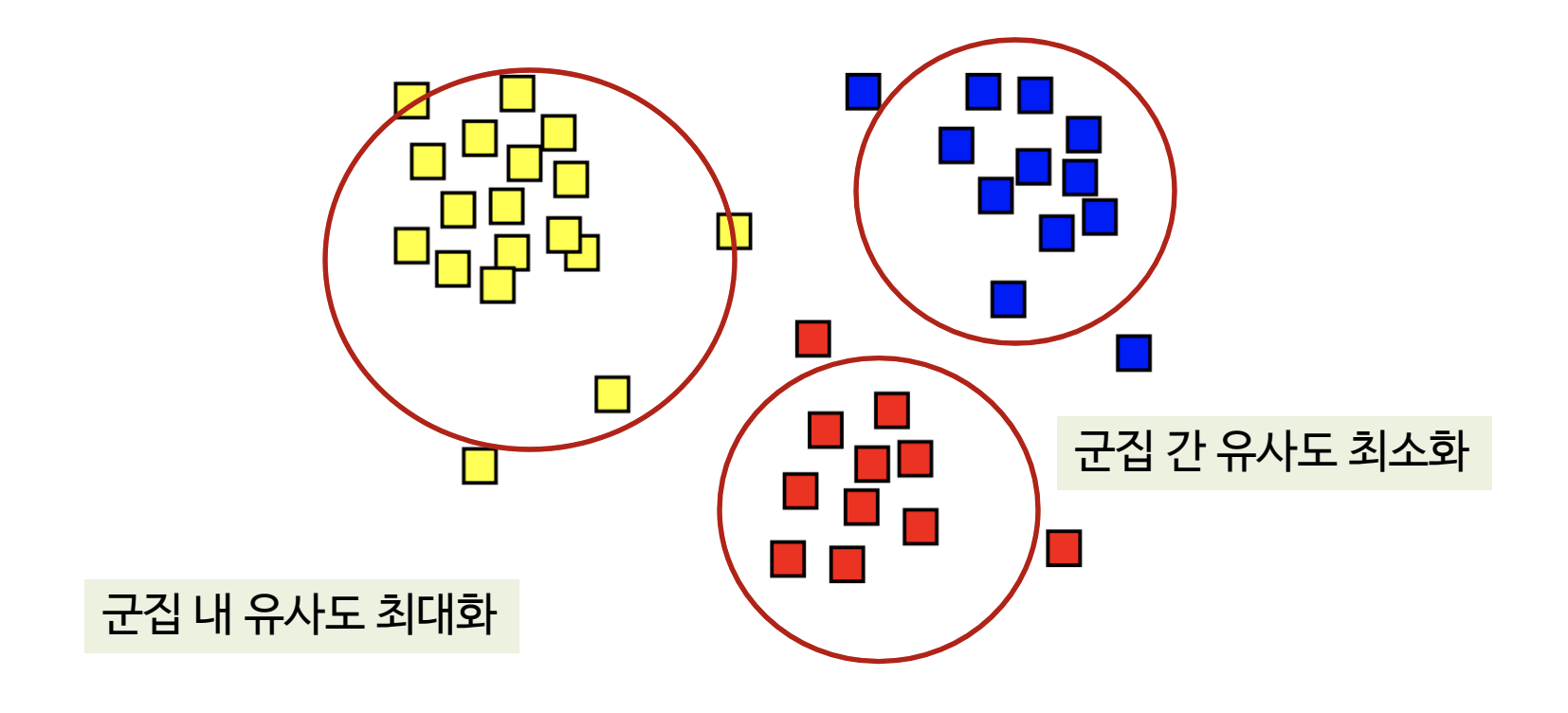
동일한 군집에 소속된 데이터는 서로 유사할수록 좋음 (inter-class similarity)
상이한 군집에 소속된 데이터는 서로 다를수록 좋음 (intra-class similarity)
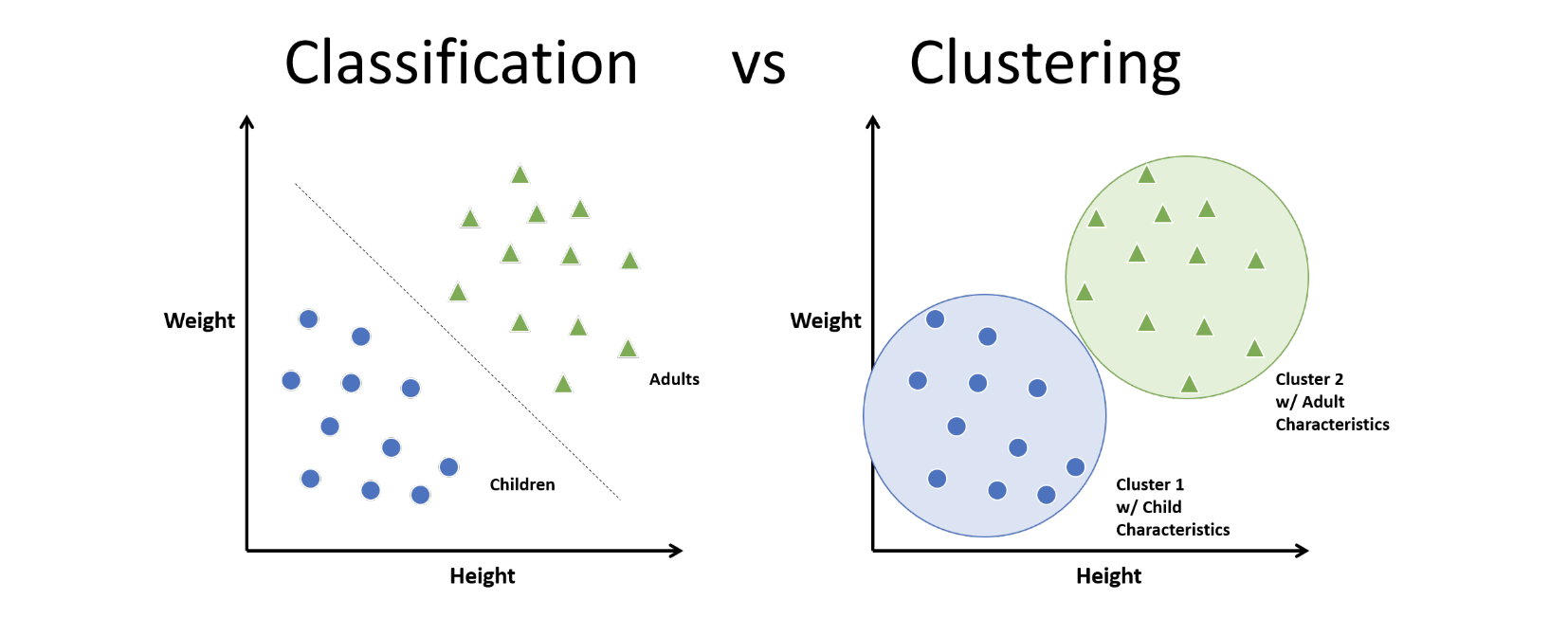
(3) 분류(classification) vs 군집화(clustering)
분류
- 사전 정의된 범주가 있는 데이터로부터 예측 모델을 학습하는 문제
- 지도학습(supervised learning)
군집화
- 사전 정의된 범주가 없는 데이터로부터 최적의 그룹을 찾아가는 문제
- 비지도학습(unsupervised learning)
2. 군집화 적용 사례
유사 문서 군집화
- 스포츠, 경제, 기술, 엔터 등 (문서 내 단어를 이용한 유사 문서 군집화)
유사 영상 군집화
- 사람, 자동차, 오토바이 등 (영상 내 영상 특징을 이용한 유사 영상 군집화)
유사 고객 군집화
- 신한 카드는 고객정보와 카드 결제내역을 통해 남녀 고객을 총 18가지 그룹으로 분류하고 고객 타입 마다 다른 카드 혜택을 제공하는 카드를 선보임
3. 군집화 수행시 주요 고려사항
- 어떤 거리 측도를 사용하여 유사도(similarity metric)를 측정 할 것인가?
- 어떤 군집화 알고리즘을 사용할 것인가?
- 어떻게 최적의 군집 수(K)를 결정할 것인가?
- 어떻게 군집화 결과를 측정/평가할 것인가?
4. 군집화 : 유사도 척도
어떤 거리 척도를 사용하여 유사도(similarity metric)를 측정할 것인가?
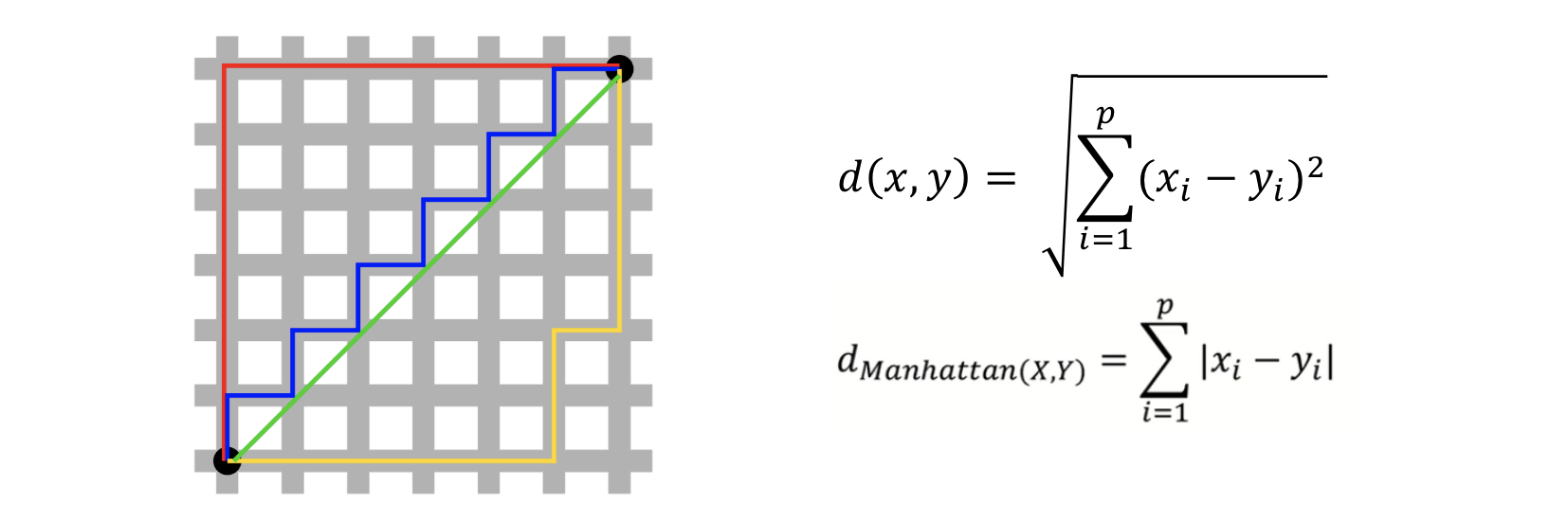
유클리디언 거리 (Euclidean Distance)
- 일반적으로 사용하는 거리 척도, L2 거리
- 두 관측치 사이의 직선 거리를 의미함
맨하탄 거리 (Manhattan Distance)
- 택시 거리, L1 거리
마할라노비스 거리 (Mahalanobis Distance)
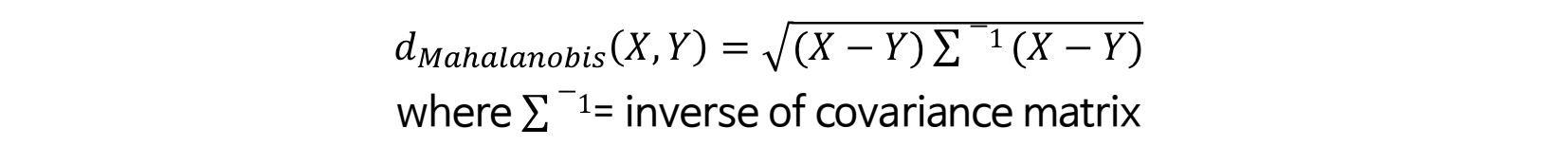
- 변수 내 분산, 변수 내 공분산을 모두 반영하여 X, Y 간 거리를 계산하는 방식
- 데이터의 covariance matrix가 identity matrix인 경우는 유클리디언 거리와 동일

5. 군집화 : 알고리즘
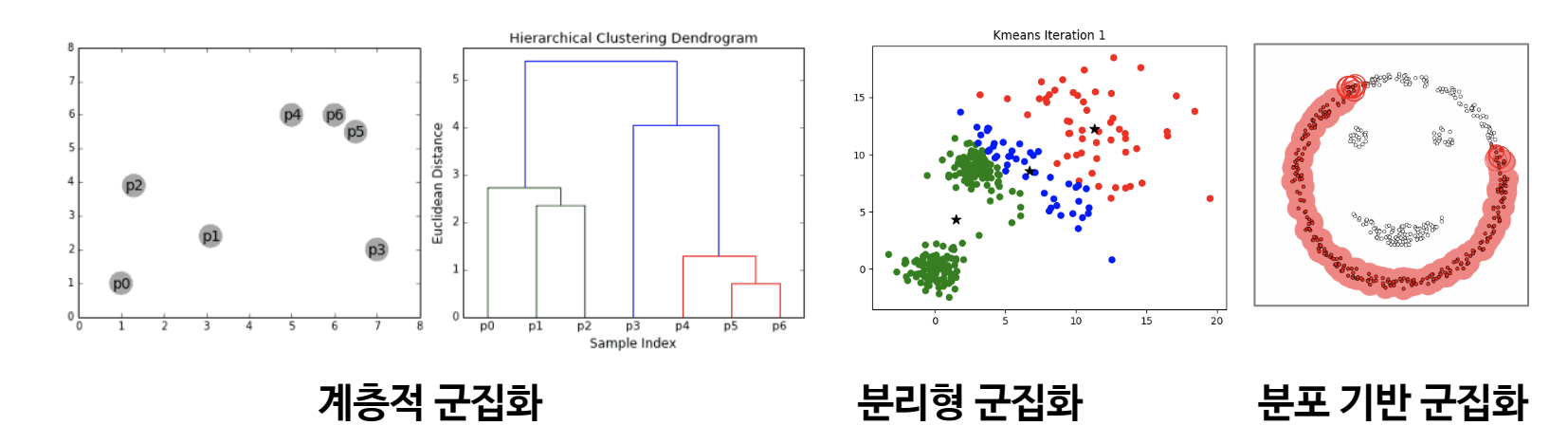
(1) 군집화 알고리즘의 종류
계층적 군집화
- 개체들을 가까운 집단부터 차근차근 묶어 나가는 방식
- 군집화 결과 뿐만 아니라 유사한 개체들이 결합되는 덴드로그램 생성
분리형 군집화
- 전체 데이터 영역을 특정 기준에 의해 동시에 구분
- 각 개체들은 사전에 정의된 개수의 군집 중 하나에 속하게 됨
분포 기반 군집화
- 데이터의 분포를 기반으로 높은 밀도를 갖는 세부 영역들로 전체 영역을 구분
(2) 계층적 군집화 (Hierarchical Clustering)
계층적 트리 모델을 이용하여 개별 개체들은 순차적/계층적으로 유사한 개체/군집과 통합
덴드로그램(Dendrogram)을 통해 시각화 가능
- 덴드로그램 : 개체들이 결합되는 순서를 나타내는 트리구조
사전에 군집의 수를 정하지 않아도 수행 가능
- 덴드로그램 생성 후 적절한 수준에서 자르면 그에 해당하는 군집화 결과 생성

1) 예시
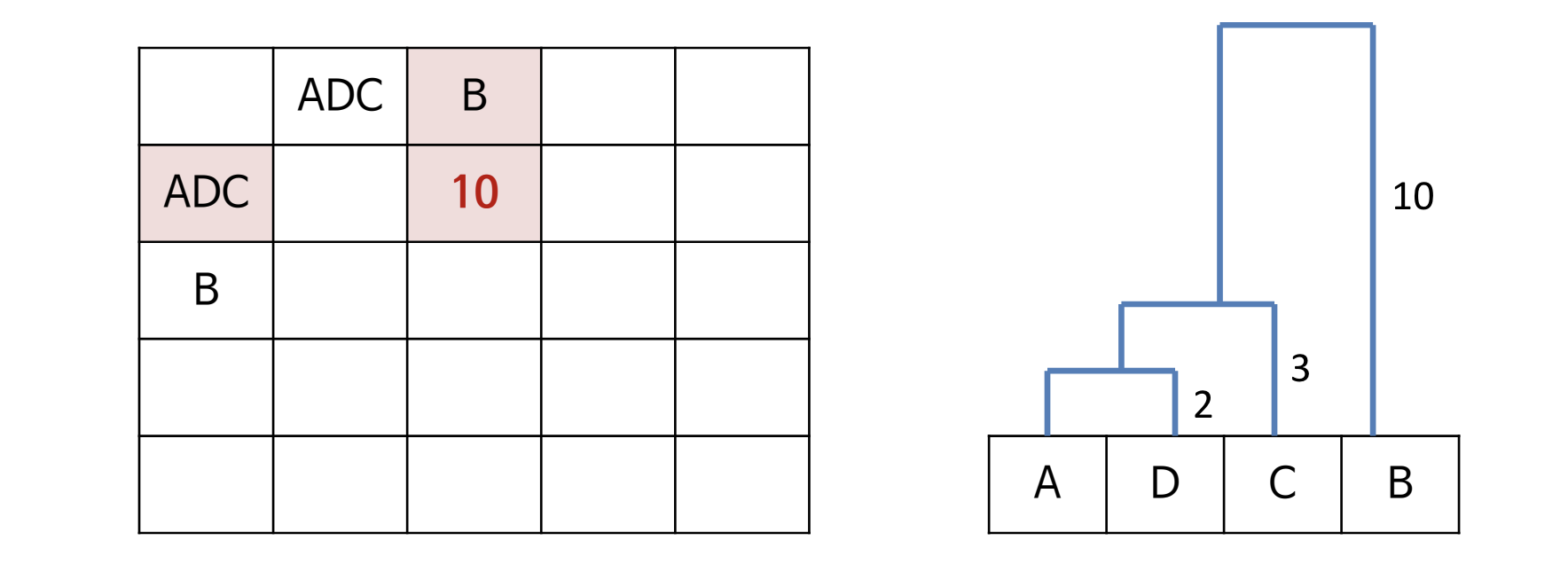
① 모든 데이터 사이의 거리에 대한 유사도 행렬 계산
② 거리가 인접한 데이터끼리 군집 형성
③ 유사도 행렬 갱신
④ ①~③ 반복

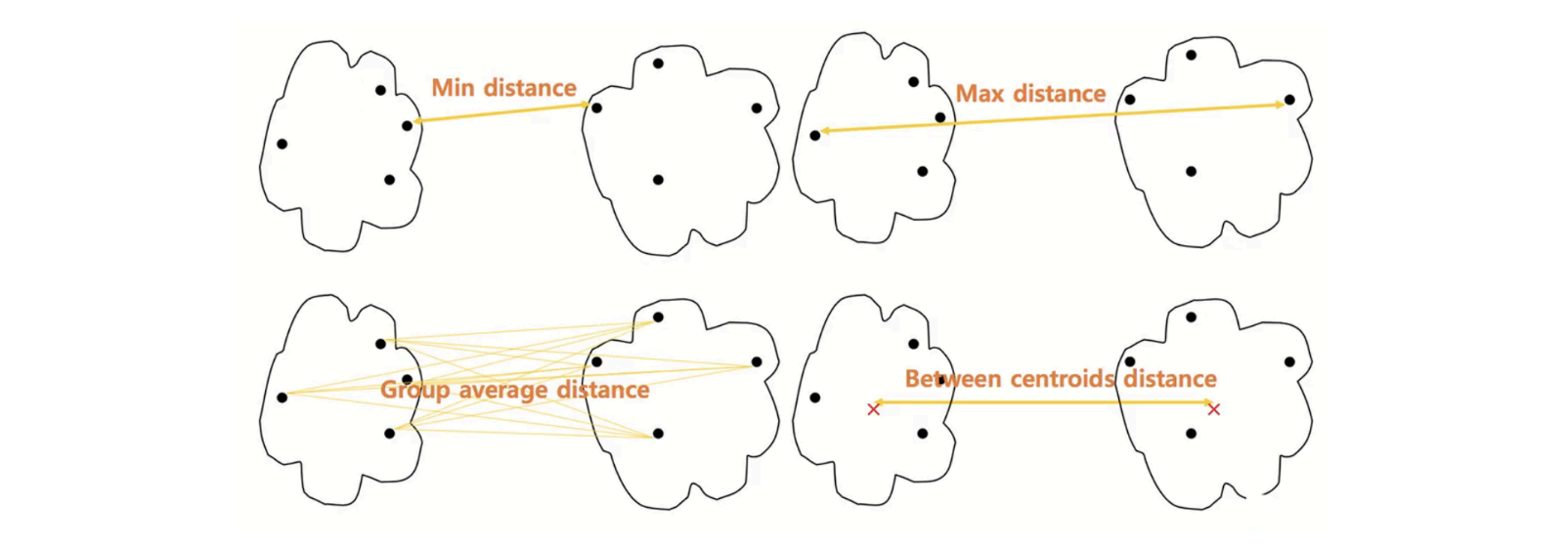
2) 군집과 군집의 거리 계산법
- 군집 내 데이터 간 거리를 모두 계산 하여 가장 작(min)은 거리 값 을 선택
- 군집 내 데이터 간 거리를 모두 계산 하여 가장 큰(max) 거리 값 을 선택
- 군집 내 데이터 간 거리를 모두 계산 하여 평균(avg) 거리 값 을 선택
- 각 군집 내 데이터의 평균을 계산하여 평균과 평균 사이의 거리 값을 선택
- Ward 거리 계산법
3) Ward 거리 계산법 (Ward linkage method)
- 서로 다른 군집에 해당하는 모든 데이터를 포함한 중심(Centroid)을 구하고, 구한 중심과 서로 다른 군집에 포함되는 모든 데이터 사이의 거리를 구한다.
- 각 군집에 해당하는 데이터를 통해 중심을 구하고, 구한 중심과 군집 내 데이터 사이의 거리를 구한다.
- 최종 결과가 클수록 서로 다른 군집은 유사도가 낮아 멀리 있고, 최종 결과가 작을수록 서로 다른 군집의 유사도는 높아 가까이에 있다.

(3) 분리형 군집화
1) K 평균 군집화 (K-means Clustering)
- 각 군집은 하나의 중심(centroid)을 가짐
- 각 객체는 가장 가까운 중심에 할당되며, 같은 중심에 할당된 개체들이 모여 하나의 군집을 형성
- 사전에 군집의 수 K가 정해져야 알고리즘을 수행할 수 있음

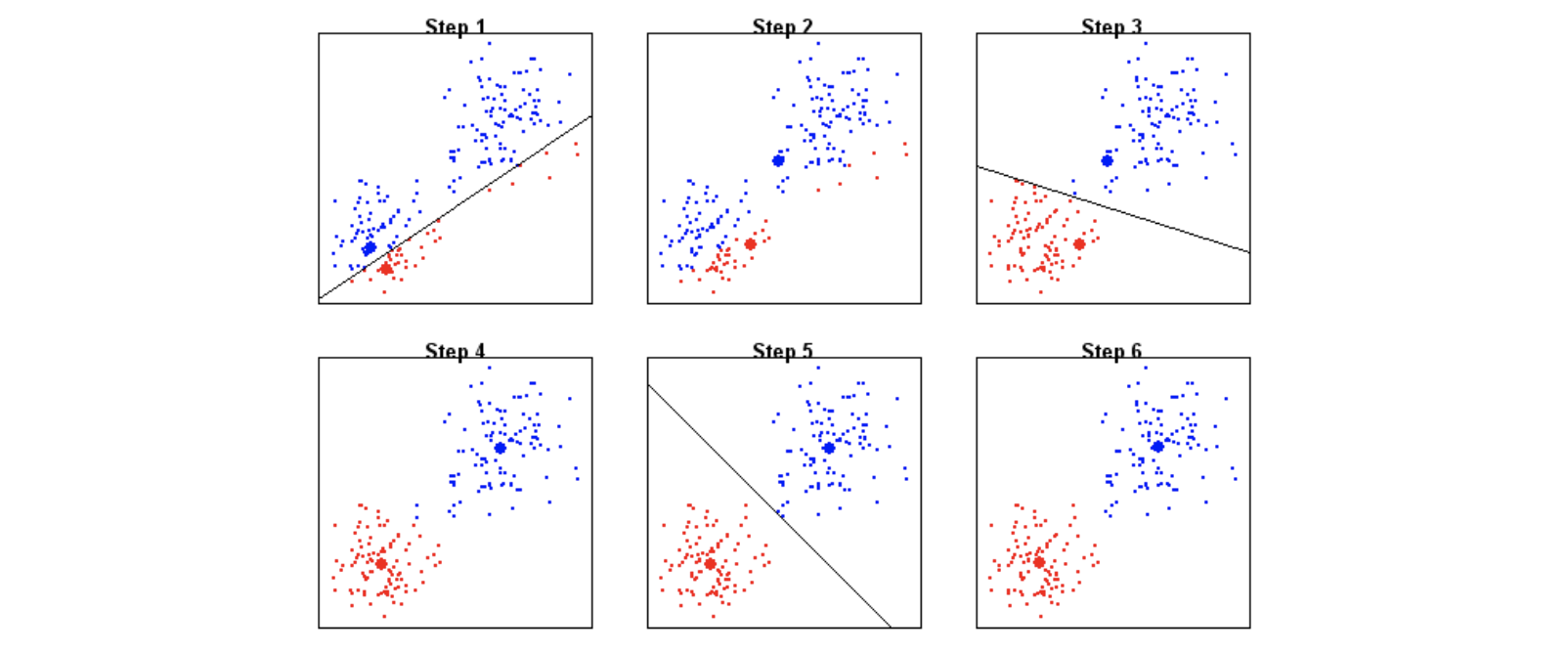
2) K 평균 군집화 예시
(K=2)
① 두 개의 중심을 임의로 생성
② 생성된 중심을 기준으로 모든 데이터에 군집 할당
③ 각 군집의 중심 다시 계산
④ 중심이 변하지 않을 때까지 (2-3)번 반복
(K>2)
① K개의 중심을 임의로 생성
② 생성된 중심을 기준으로 모든 데이터에 군집 할당
③ 각 군집의 중심 다시 계산
④ 중심이 변하지 않을 때까지 (2-3)번 반복

초기 중심 설정은 최종 군집화 결과에 영향을 미칠 수 있음
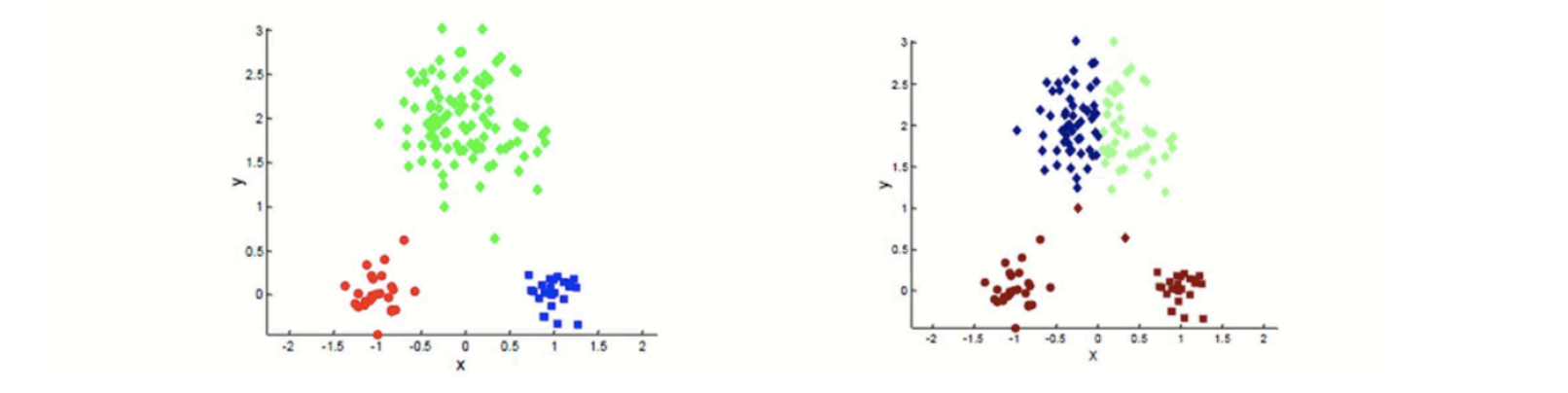
K 평균 군집화 초기화의 바른 예시

K 평균 군집화 초기화의 잘못된 예시

K 평균 군집화의 랜덤 초기화의 단접 극복 방법
여러 번 Kmeans 군집화를 수행하여 가장 여러 번 나타나는 군집을 사용
- 앙상블 (ensemble) 결과 통합
데이터 분포 정보를 활용한 초기화 선정
- 데이터가 Gaussian 분포라면, 중심을 초기 값으로 선정
(데이터가 많을 때) 샘플링 데이터를 활용하여 계층적 군집화를 수행한 뒤 초기 군집 중심으로 사용
하지만 많은 경우 초기 중심이 최종 결과에 영향을 미치지 않음
K 평균 군집화의 단점
- 서로 다른 크기의 군집을 잘 찾아내지 못함

- 서로 다른 밀도의 군집을 잘 찾아내지 못함

- 지역적 패턴이 존재하는 군집을 판별하기 어려움

K 평균 군집화의 K 값 선정 방법
- 다양한 군집 수에 대한 성능 평가 지표를 통해 최적의 군집 수(K) 선택
- 일반적으로 Elbow point에서 최적의 군집 수 결정

군집화 평가 방법
- 지도학습기반 분류 문제처럼 모든 상황에 적용 가능한 평기 지표 부재
- 내부 평가 지표: Dunn Index, Sum of Squared Error(SSE)
- 외부 평가 지표: Rand Index, Jaccard Coefficient 등
군집화 평가 지표: Sum of Squared Error (SSE)
- 군집 내 거리 최소화 (만족), 군집 간 거리 최대화 (불만족)
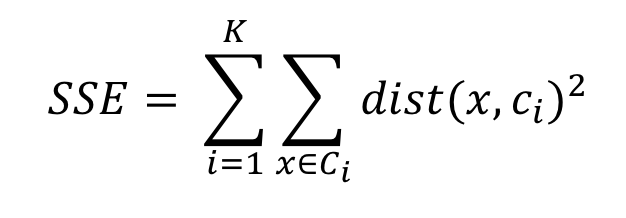

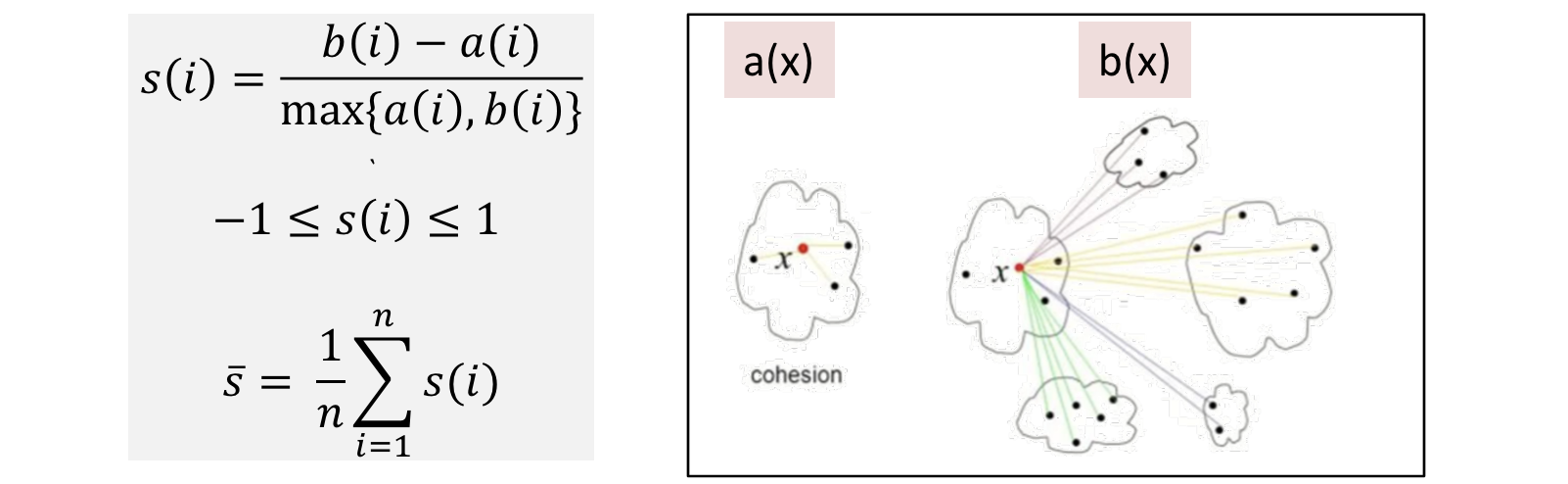
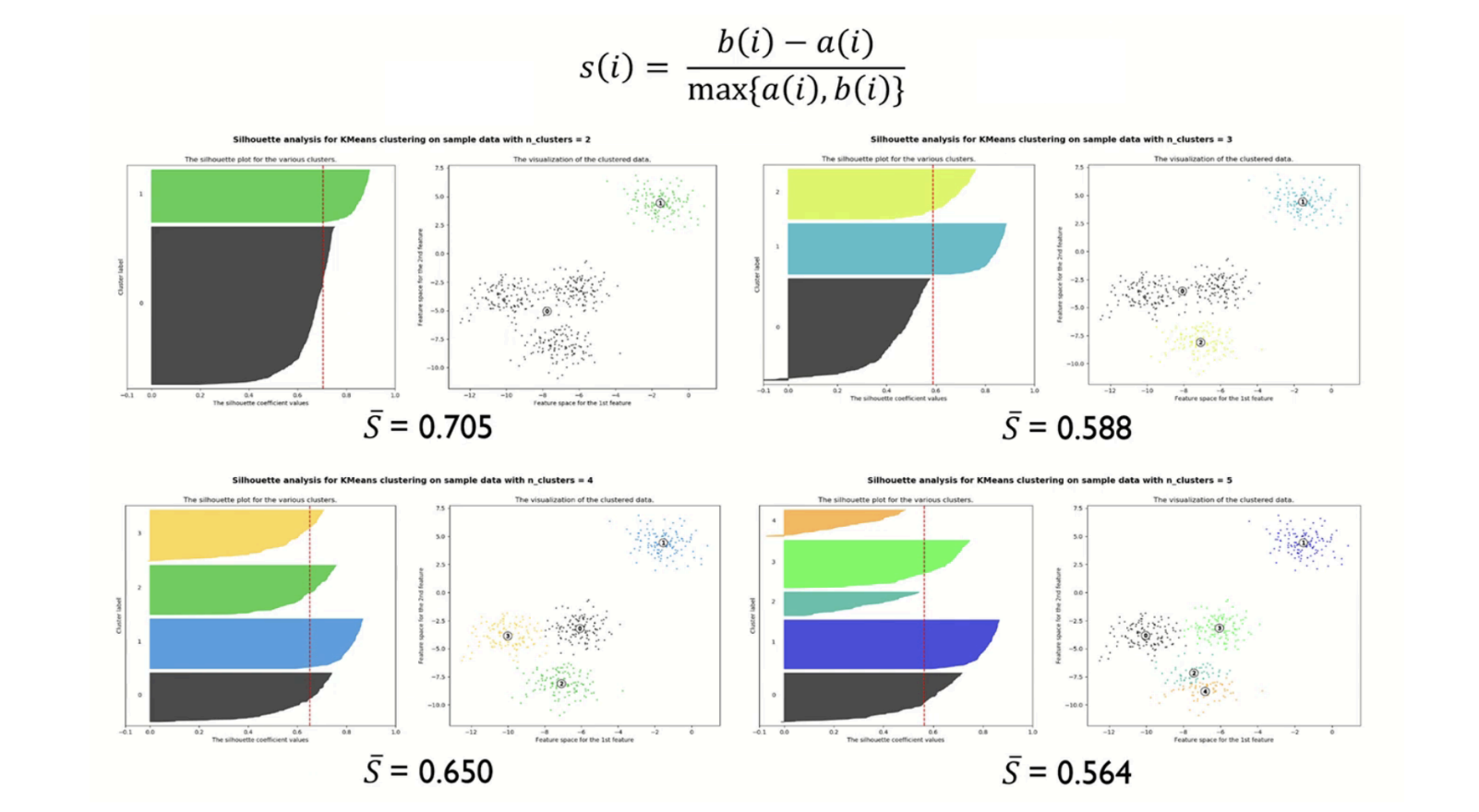
군집화 평가 지표: silhouette 통계량
a(i): i번째 데이터와 같은 군집 내에 있는 모든 데이터 사이의 평균 거리
- 작을수록 유사한 데이터가 잘 모여 있다는 의미
b(i): i번째 데이터와 다른 군집 내에 있는 모든 데이터 사이의 최소 거리
- 클수록 서로 다른 데이터가 잘 흩어져 있다는 의미
일반적으로 S 값이 0.5보다 크면 군집 결과가 타당하다고 판단
- S값이 1에 가까울 수록 군집화 Good, -1에 가까울 수록 군집화 Bad
- K=2 인 경우에 통계량이 Best인 경우가 많아서 차 순위 K를 선정하는 것이 일반적임
(4) 분포 기반 군집화
1) DBSCAN (Density Based Clustering)
- 높은 밀도를 가지고 모여 있는 데이터들을 그룹으로 분류
- 낮은 밀도를 가지고 있는 데이터는 이상치 또는 잡음으로 분류
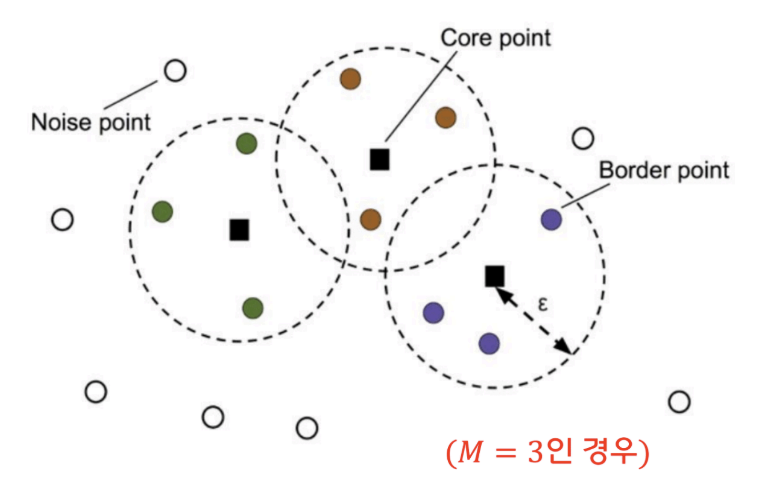
- 데이터의 $ \epsilon $-neighborhood가 M개 이상의 데이터를 포함하는지 고려하여 분류
- $ \epsilon $과 M은 분포 기반 군집화의 파라미터
핵심자료(core point)
- $\epsilon$-neighborhood가 M개 이상의 데이터를 포함하는 자료
주변자료(border point)
- 핵심자료는 아니지만 $\epsilon$-neighborhood에 핵심자료를 포함하 는 자료
잡음자료(noise point)
- 핵심자료도 주변자료도 아닌 자료
① 임의 데이터 선택하고 군집 1 부여
② 임의 데이터의 $\epsilon$-NN 을 구하고 데이터의 수가 M보다 작으면 잡음자료 부여
③ M 보다 크면 $\epsilon$-NN 모두 군집1 부여, 군집 1 모든 데이터의 $\epsilon$-NN 의 크기가 M보다 큰 것이 없을 때까지 반복
④ 군집 2 에 대해 동일하게 반복 (모든 데이터에 군집이 할당되거나 잡음으로 분류될 때까지 절차 (1-3) 반복)
파라미터 설정
$\epsilon$ : 너무 작으면 많은 데이터가 잡음으로 분류되고 너무 크면 군집의 개수가 적음
HDBSCAN의 경우 $\epsilon$ 자동 설정
M : 일반적으로 “특성 변수 개수+1”을 사용
2) DBSCAN (Density Based Clustering) 예시


'Computer Science > Machine Learning' 카테고리의 다른 글
| 데이터 전처리 [이직을 희망하는 직원 예측 문제] (2) (0) | 2024.06.09 |
|---|---|
| 데이터 전처리 (1) (0) | 2024.06.09 |
| Discriminant analysis(판별 분석) [Discriminant Analysis 이용 당뇨병 환자 예측] (4) (0) | 2024.03.31 |
| Discriminant analysis(판별 분석) [Discriminant Analysis 이용 원자력발전소 상태 예측] (3) (0) | 2024.03.31 |
| Discriminant analysis(판별 분석) [Iris] (2) (0) | 2024.03.31 |


