
You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization
Spatiotemporal action localization requires the incorporation of two sources of information into the designed architecture: (1) temporal information from the previous frames and (2) spatial information from the key frame. Current state-of-the-art approache
arxiv.org
0. Abstract
Spatiotemporal action localization(시공간적 동작 위치 측정)을 위해서는 (1) 이전 프레임의 시간 정보와 (2) 키 프레임의 공간 정보라는 두 가지 정보 소스를 설계된 아키텍처에 통합해야 한다.
현재의 최신 접근 방식은 일반적으로 별도의 네트워크로 이러한 정보를 추출하고 추가적인 융합 메커니즘을 사용하여 탐지 결과를 얻는다. YOWO는 비디오 스트림에서 실시간 시공간적 동작 위치 측정을 위한 통합 CNN 아키텍처(end-to-end)이다. 시간 및 공간 정보를 동시에 추출(2D-CNN과 3D-CNN을 한 모델에서 사용)하고 한 번의 평가로 비디오 클립에서 직접 바운딩 박스와 동작 확률을 예측하는 두 가지 분기가 있는 단일 단계 아키텍처이다.
16프레임 입력 클립에서 초당 34프레임, 8프레임 입력 클립에서 초당 62프레임의 빠른 속도(실시간성)를 제공한다. 또한 J-HMDB-21과 UCF101-24에서 각각 ∼3%, ∼12%의 성능 향상을 보였다.
1. Introduction
기존에는 action localization을 action과 object detection 2단계로 진행했다.
(1) Action detection을 수행
(2) Classification, localization을 진행
기존의 action localization은 video에서 action과 object detection 2단계로 진행됐다. 하지만 이 pipline은 spatiotemporal action localization에서 3개의 단점이 존재한다.
(1) 프레임 간 bounding box로 구성된 action tubes 생성은 2D보다 복잡하고 시간이 오래걸림
(2) Video에서 사람의 동작만 집중하고, 사람과 물체, 배경의 상호작용은 무시
(3) 2개의 모델 구조를 갖기에 전체적으로 최적(global optimum)값을 찾을 수 없음
(train비용이 높고, 시간이 오래걸리고, 메모리를 많이 사용함)
세 가지 단점을 모두 해결하기 위한, single-stage 프레임워크인 YOWO(You Only Watch Once)를 제안한다. YOWO는 인간의 시각 인지 체계에서 영감을 받았다. 예를 들어, 우리가 TV 앞에서 드라마의 스토리에 몰입할 때, 우리의 눈은 매번 하나의 프레임을 포착한다. 각 배우가 어떤 행동을 취하고 있는지 이해하기 위해서는 현재 프레임 정보(키 프레임의 2D 특징)와 기억에 저장된 이전 프레임에서 얻은 지식(클립의 3D 특징)을 연관시킨다. 그 후, 이 두 가지 특징을 융합하여 결론을 도출한다.
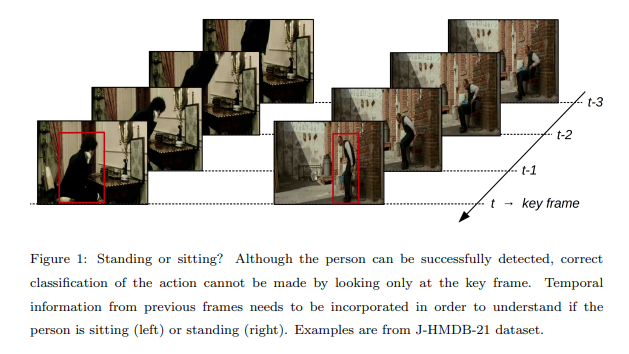
YOWO는 2개의 branch를 갖는 single-stage network로 구성된다. 하나의 분기는 key frame을 추출하고 2D-CNN에 통과시킨다. 다른 분기는 이전 프레임들(clip)을 3D-CNN에 통과시킨다. 그리고 이 둘을 합치기 위해 channel fusion 과 attention mechanism을 사용하여, 프레임 단위의 detection을 만들었다. 실시간 성능을 위해 RGB타입 데이터를 사용했으나 optical flow, depth등의 데이터도 사용 가능하다. 또한 2D-CNN 과 3D-CNN자리에 다른 CNN구조를 사용할 수도 있다.
YOWO는 입력으로 최대 16프레임을 받아 시공간 상의 action localization을 수행한다. 훈련된 3D-CNN을 사용하여 전체 비디오에 대해 겹치지 않는 8-프레임 클립에 대해 3D-CNN으로 기능을 추출하여 long-term feature bank를 활용했고 마지막 perdormance에서 6.9%와 1.3%의 성능향상을 보였다.
2. Related Work
Action recognition with deep learning
Action recognition을 위해서는 각 개별 이미지에서 추출한 공간적 특징 외에도 각 프레임의 시간적 맥락도 고려해야 한다.
Two stream CNN은 공간적 특징과 시간적 특징을 개별적으로 추출하고 이를 통합하는 효과적인 전략 중 하나이다. 이러한 작업의 대부분은 광학적 흐름을 기반으로 하며, 추출에 상당한 연산 능력이 필요하기 때문에 시간이 오래 걸린다. 시간이 지남에 따라 CNN 기능을 통합하는 또 다른 옵션은 recurrent network를 구현하는 것이지만, 이 방법은 최근의 CNN 기반 방법만큼 성능이 만족스럽지 않다. 최근에는 공간적 차원과 시간적 차원에서 동시에 특징을 학습하는 3D-CNN이 비디오 분석 작업에서 점점 더 많이 활용되고 있다.
Spatiotemporal action localization
Object detection을 위해 R-CNN 계열은 1단계에서 선택적 검색 또는 지역 제안 네트워크(RPN)를 사용하여 영역 제안을 추출하고, 2단계에서 이러한 잠재 영역에 있는 객체를 분류한다.
Faster R-CNN은 SOTA를 얻을 수 있지만, 2-stage로 인해 시간이 많이 걸리기 때문에 실시간 작업에 사용하기 어렵다. 반면, YOLO와 SSD는 이 과정을 1-stage로 단순화하여 뛰어난 실시간 성능을 구현했다.
Action localization의 경우, R-CNN 시리즈의 영향으로 대부분은 먼저 각 프레임에서 사람을 감지한 다음 detection box를 액션 튜브로 연결한다. Two stream detector는 광학 흐름 양식을 위해 원래 분류기의 기반에 추가 스트림을 도입한다. 일부 다른 연구에서는 3D-CNN으로 클립 튜브 제안을 생성하고 해당 3D 특징에 대한 분류뿐만 아니라 회귀를 달성하므로 영역 제안이 필요하다. 최근 연구에서는 동작 분류와 함께 픽셀 단위의 동작 분할을 공동으로 수행할 수 있는 비디오 동작 검출을 위한 3D 캡슐 네트워크를 제안한다. 하지만 U-Net 기반의 3D-CNN 아키텍처이기 때문에 계산 복잡도와 파라미터 수 측면에서 비용이 많이 든다는 단점이 있다.
Attention modules
Attention는 멀리 떨어진 데이터 사이의 연관성을 포착하는 효과적인 메커니즘으로, image classification 및 scene segmentation의 성능을 향상시키기 위해 CNN에서 사용하려했다. 이러한 작업에서 attention 메커니즘은 spatial-wise와 channel-wise로 구현되는데, spatial-wise는 특징들 간의 공간적 관계를 다루고, channel-wise는 가장 의미 있는 채널을 강화하고 다른 채널을 약화시킨다. Channel-wise attention block으로 squeeze-and-Excitation 모듈은 적은 계산 비용으로 CNN의 성능을 향상시키는 데 유용하다. 반면에, video classification의 경우 non-local block은 시공간 정보를 고려하여 프레임 간 특징의 의존성을 학습하는 self-attention 전략이다.
3. Methodology
YOWO은 3D-CNN, 2D-CNN, CFAM, bounding box regression 4가지 큰 구조로 이루어져 있다.
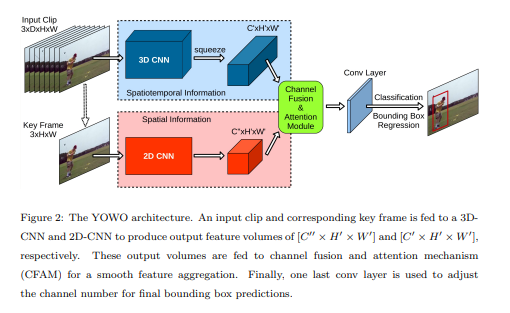
3D-CNN
Human action은 맥락이 중요하기에 3D-CNN에서 시공간적 특성을 추출하는 역할을 한다. 3D-CNN은 convolution을 통해 시간 차원과 공간 차원의 동작을 감지할 수 있다. 여기서 3D-CNN구조는 Kinetics dataset에서 높은 성능을 내는 3D-ResNext-101을 사용했다.
연속적인 프레임을 입력으로 할 때 shape은 $ [C × D × H × W] $이고 3D-ResNext-101의 출력은 $ [C' × D' × H' × W'] $이다.
${C : color\,channel}$
${D : 입력 프레임 갯수}$
${W : 가로}$
${H : 세로}$
출력 feature map의 depth dimension은 2D-CNN의 출력과 일치시키기 위해 $[C' × H' × W']$로 압축(squeezed)시킨다.
${C' : 출력 channel 갯수}$
${D' : 1\,(압축될\,때\,사라짐)}$
${H' : \frac{H}{32}}$
${W' : \frac{W}{32}}$
2D-CNN
Spatial localization 문제를 해결하기 위해 키 프레임의 2D 기능도 병렬로 추출된다. 여기서 2D-CNN구조는 정확도와 효율성이 좋은 Darknet-19를 사용했다.
key-frame의 shape은 $ [C × H × W] $이고 Darknet-19의 출력 shape는 3D-CNN과 유사한 $ [C" × H' × W'] $이다.
${C' : 출력\,channel\,갯수}$
${H' : \frac{H}{32}}$
${W' : \frac{W}{32}}$
YOWO의 특징은 2D-CNN과 3D-CNN을 임의의 CNN구조로 바꿀 수 있기에 유연하다.
Feature aggregation: Channel Fusion and Attention Mechanism (CFAM)
앞서 3D와 2D network의 출력 shape를 동일하게 했기 때문에 둘을 쉽게 결합할 수 있다. concatenation을 이용해 두 결과물을 쌓는다. 결과적으로, motion과 appearance information을 CFAM의 입력으로 인코딩 한다.
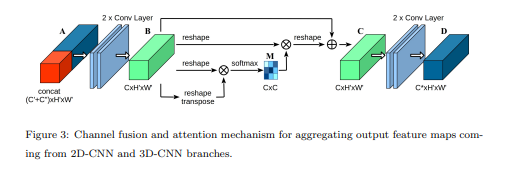
Bounding box regression
bounding box regression는 YOLO와 동일한 방식을 사용했다. 원하는 수의 출력 채널을 생성하기 위해 1×1 커널을 가진 마지막 층의 컨볼루션 레이어가 적용된다.
4. Experiment
YOWO를 검증하기 위해 UCF101-24와 J-HMDB-21 데이터셋을 사용했다.
3D network, 2D network or both?
3D-CNN, 2D-CNN중 하나만 사용해 spatiotemporal localization 문제를 풀 수는 있으나 둘을 함께 사용하면 성능이 증가한다.
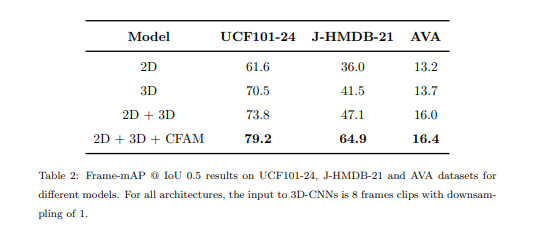
3D-CNN, 2D-CNN과 CFAM까지 활용하여 측정하면 아래와 같은 결과가 나타난다.

Backbone은 사람의 몸통쪽에 더 높은 가중치를 갖는다.
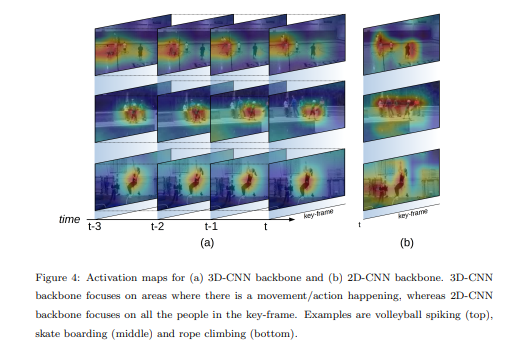
How many frames are suitable for temporal information?
3D-CNN의 경우, 다운샘플링 속도가 다른 클립 길이가 다르면, 전체 YOWO 아키텍처의 성능이 달라질 수 있다. 따라서 표 4와 같이 다운샘플링 속도가 다른 8프레임과 16프레임 클립으로 실험을 진행했다.
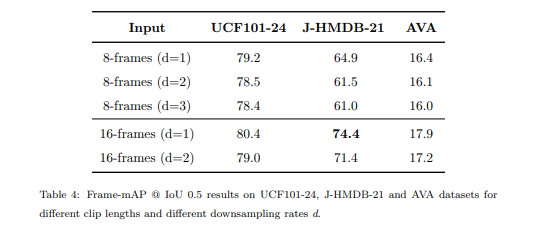
예를 들어 8프레임(d=3)은 24프레임 창에서 8프레임을 다운샘플링 비율 3으로 선택했다. 구체적으로 클립 길이 8프레임의 경우 다운샘플링 비율 d = 1, 2, 3의 세 가지를, 클립 길이 16프레임의 경우 다운샘플링 비율 d = 1, 2의 두 가지를 비교한다. 예상대로 긴 프레임 시퀀스에 더 많은 시간 정보가 포함되어 있기 때문에 16프레임 입력 프레임워크가 8프레임보다 성능이 더 좋은 것을 관찰했다. 그러나 다운샘플링 속도가 증가함에 따라 성능이 저하된다. 다운샘플링이 모션 패턴을 제대로 캡처하는 데 방해가 되고 너무 긴 시퀀스는 시간적 맥락 관계를 깨뜨릴 수 있기 때문인 것으로 추측된다. 특히 일부 빠른 모션 클래스의 경우 긴 시퀀스에는 관련 없는 프레임이 여러 개 포함될 수 있으며, 노이즈로 간주될 수 있다.
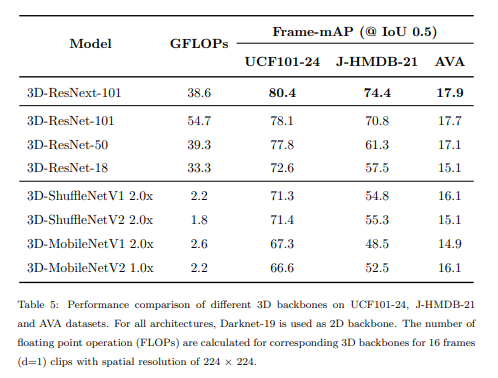
Is it possible to save model complexity with more efficient networks?
저자는 많은 가중치를 갖는 모델이 복잡한 내용을 학습할 수 있다고 생각하여 3D-ResNext-101를 사용했다. 아래 table을 보면 모델이 가벼워질수록 성능이 떨어지는 것을 확인할 수 있다.
5. Conclusion
본 논문에서 저자는 비디오에서 시공간 action localization인 YOWO를 제시했다. 또한 UCF101-24 와 J-HMDB-21로 테스트를 수행했다. 본 방식은 실시간 동작이 가능하며 기존보다 좋은 성능을 내므로 모바일 기기에서 사용할 수도 있다.
'CV > Paper Review' 카테고리의 다른 글
| (DeepSORT) SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC (1) | 2024.05.07 |
|---|---|
| A Unified Approach to Interpreting Model Predictions (0) | 2024.05.07 |
| (DDPM) Denoising Diffusion Probabilistic Models (0) | 2024.03.20 |
| Show and Tell: A Neural Image Caption Generator (4) | 2024.02.28 |
| (ViT) AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2024.02.28 |



