
# 필요한 기본 라이브러리 import
import random
import torch
import numpy as np
import os
import pandas as pd
# 랜덤시드 고정하기
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
1. Load CIFAR-10 Dataset
from torchvision.datasets import CIFAR10 ## CIFAR10 데이터를 불러오기 위해 라이브러리 import
trainset = CIFAR10(root='./data', train=True,download=True)## CIFAR10 train set을 불러오기
testset = CIFAR10(root='./data', train=False,download=True)## CIFAR10 test set을 불러오는 과정
x_train = trainset.data
y_train = trainset.targets
x_test = testset.data
y_test = testset.target
x_train.shape : (50000, 32, 32, 3)
x_test.shape : (10000, 32, 32, 3)
2. Visualize the First 24 Training Images
# 시각화를 위해 필요한 라이브러리 import
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x_train = trainset.data
# 불러온 데이터 셋 중 처음 24개 이미지에 대한 시각화
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
3. Rescale the Images by Dividing Every Pixel in Every Image by 255
# Rescale [0,255] -> [0,1]
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
4. Break Dataset into Training, Testing, and Validation Sets
# torch.nn.CrossEntropyLoss는 one-hot encoding 내장
# pytorch는 모델에 입력하는 데이터가 tensor 형태로 변경
# pytorch는 (Channel, Height, Width)의 형태로 변경
# train set을 train과 validation set으로 나눔
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
# 모델에 입력하기 위해데이터를 tensor 형태로 변경
x_train, y_train = torch.FloatTensor(x_train), torch.LongTensor(y_train)
x_valid, y_valid = torch.FloatTensor(x_valid), torch.LongTensor(y_valid)
x_test, y_test = torch.FloatTensor(x_test), torch.LongTensor(y_test)
# pytorch는 (Channel, Height, Width)의 형태로 이루어짐
x_train = torch.swapaxes(x_train,1,3)
x_valid = torch.swapaxes(x_valid,1,3)
x_test = torch.swapaxes(x_test,1,3)
# print shape of training set
print('x_train shape:', x_train.shape)
# print number of training, validation, and test images
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_valid.shape[0], 'validation samples')
5. Define the Model Architecture
%pip install torchsummary ## model을 요약하기 위해 torchsummary 설치
from torchsummary import summary as summary_## 모델 정보를 확인하기 위해 torchsummary 함수 import
# 모델의 형태를 출력하기 위한 함수
def summary_model(model,input_shape=(3, 32, 32)):
model = model.cuda()
summary_(model, input_shape) ## (model, (input shape))# CNN 모델 구조 정의 (version 1)
from torch.nn import Sequential
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Dropout, ReLU, Softmax
# nn.Sequential 함수는 네트워크를 인스턴스화하는 동시에, 원하는 신경망에 연산 순서를 인수로 전달함.
model_1 = Sequential(
Conv2d(3,16,kernel_size=2,padding='same'), ## Conv2d(in_channel, out_channel, kernerl_size, padding, bias)
ReLU(),
MaxPool2d(kernel_size=2),
Conv2d(16,32,kernel_size=2,padding='same'),
ReLU(),
MaxPool2d(kernel_size=2),
Conv2d(32,64,kernel_size=2,padding='same'),
ReLU(),
MaxPool2d(kernel_size=2),
Dropout(0.3),
Flatten(),
Linear(1024,500),
ReLU(),
Dropout(0.4),
Linear(500,10),
Softmax()
).cuda() ## GPU로 올리기
print(model_1)
summary_model(model_1)# CNN 모델 구조 정의 (version 2)
import torch.nn
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# 컨볼루션 커널 정의
self.conv1 = torch.nn.Conv2d(3,16,kernel_size=2,padding='same')
self.conv2 = torch.nn.Conv2d(16,32,kernel_size=2,padding='same')
self.conv3 = torch.nn.Conv2d(32,64,kernel_size=2,padding='same')
# dense 레이어 정의
self.dense1 = torch.nn.Linear(1024,500) # 1024:(64 * 4 * 4)
self.dense2 = torch.nn.Linear(500,10)
self.maxpool = torch.nn.MaxPool2d(kernel_size=2) ## Maxpooling 레이어 정의
self.flatten = torch.nn.Flatten()## Flatten 레이어 정의
self.dropout1 = torch.nn.Dropout(0.3)## Dropout 정의 (확률 0.3)
self.dropout2 = torch.nn.Dropout(0.4)## Dropout 정의 (확률 0.4)
self.relu = torch.nn.ReLU() ## 활성화함수 정의
self.softmax = torch.nn.Softmax() ## softmax 함수 정의
def forward(self, x): # forward 정의
y = self.relu(self.conv1(x))
y = self.maxpool(y)
y = self.relu(self.conv2(y))
y = self.maxpool(y)
y = self.relu(self.conv3(y))
y = self.maxpool(y)
y = self.dropout1(y)
y = self.flatten(y)
y = self.relu(self.dense1(y))
y = self.dropout2(y)
y = self.softmax(self.dense2(y))
return y
model_2 = Net().cuda() ## GPU로 올리기
print(model_2)
summary_model(model_2,(3,32,32))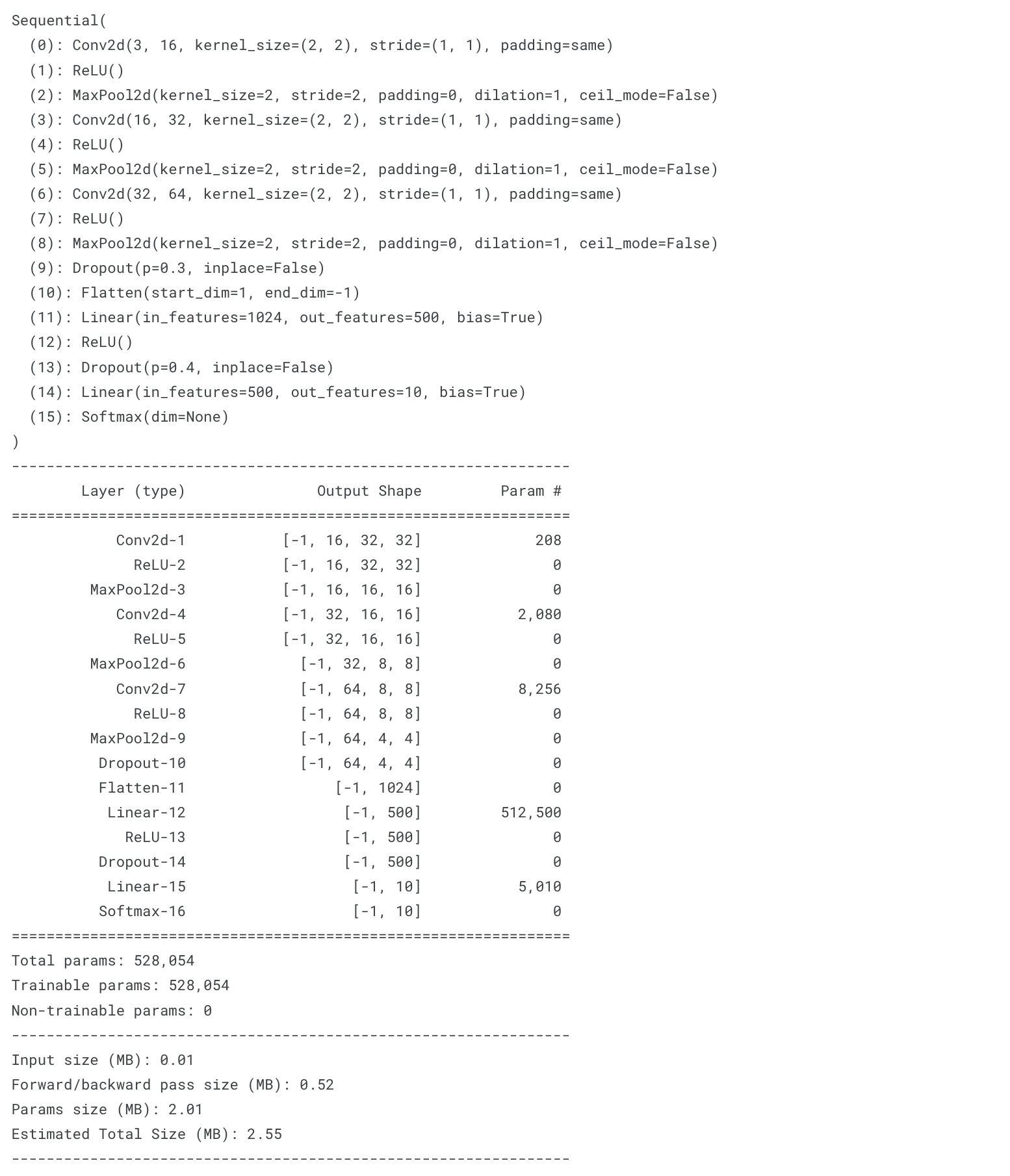
7. Train
model = Net().cuda()
learning_rate = 0.001
optimizer = torch.optim.RMSprop(model.parameters(),lr = learning_rate)## RMSprop을 최적화 함수로 이용함. 파라미터는 documentation을 참조!
loss = torch.nn.CrossEntropyLoss().cuda() ## 분류문제이므로 CrossEntropyLoss를 이용함# train the model
import time
train_dataset = torch.utils.data.TensorDataset(x_train,y_train)
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=32,shuffle=True)
valid_dataset = torch.utils.data.TensorDataset(x_valid,y_valid)
validloader = torch.utils.data.DataLoader(valid_dataset, batch_size=1,shuffle=False)
# 파라미터 설정
total_epoch = 35
best_loss = 100
for epoch in range(total_epoch):
start = time.time()
print(f'Epoch {epoch}/{total_epoch}')
# train
train_loss = 0
correct = 0
for x, target in trainloader:## 한번에 배치사이즈만큼 데이터를 불러와 모델을 학습함
optimizer.zero_grad()## 이전 loss를 누적하지 않기 위해 0으로 설정해주는 과정
y_pred = model(x.cuda())## 모델의 출력값
cost = loss(y_pred, target.cuda())## loss 함수를 이용하여 오차를 계산함
cost.backward()# gradient 구하기
optimizer.step()# 모델 학습
train_loss += cost.item()
pred = y_pred.data.max(1, keepdim=True)[1] ## 각 클래스의 확률 값 중 가장 큰 값을 가지는 클래스의 인덱스를 pred 변수로 받음
correct += pred.cpu().eq(target.data.view_as(pred)).sum()# pred와 target을 비교하여 맞은 개수를 구하는 과정.
# view_as함수는 들어가는 인수의 모양으로 맞춰주고, .eq()를 통해 pred와 target의 값이 동일한지 판단하여 True 개수 구하기
train_loss /= len(trainloader)
train_accuracy = correct / len(trainloader.dataset)
# eval (validation 데이터를 이용하여 모델을 검증)
eval_loss = 0
correct = 0
with torch.no_grad(): ## 학습하지 않기 위해
model.eval()# 평가 모드로 변경
for x, target in validloader:
y_pred = model(x.cuda())## 모델의 출력값
cost = loss(y_pred,target.cuda())## loss 함수를 이용하여 test 데이터의 오차를 계산함
eval_loss += cost
pred = y_pred.data.max(1, keepdim=True)[1]## 각 클래스의 확률 값 중 가장 큰 값을 가지는 클래스의 인덱스를 pred 변수로 받음
correct += pred.cpu().eq(target.data.view_as(pred)).cpu().sum()# pred와 target을 비교하여 맞은 개수를 구하는 과정
eval_loss /= len(validloader)
eval_accuracy = correct / len(validloader.dataset)
## validation 데이터의 loss를 기준으로 이전 loss 보다 작을 경우 체크포인트 저장
if eval_loss < best_loss:
torch.save({
'epoch': epoch,
'model': model,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': cost.item,
}, './bestCheckPoint.pth')
print(f'Epoch {epoch:05d}: val_loss improved from {best_loss:.5f} to {eval_loss:.5f}, saving model to bestCheckPiont.pth')
best_loss = eval_loss
else:
print(f'Epoch {epoch:05d}: val_loss did not improve')
model.train()
print(f' - {int(time.time() - start)}s - loss: {train_loss:.5f} - acc: {train_accuracy:.5f} - val_loss: {eval_loss:.5f} - val_acc: {eval_accuracy:.5f}')
8. Load the Model with the Best Validation Accuracy
# Load Checkpoint
best_model = torch.load('./bestCheckPoint.pth')['model'] # 전체 모델을 통째로 불러옴, 클래스 선언 필수
best_model.load_state_dict(torch.load('./bestCheckPoint.pth')['model_state_dict']) # state_dict를 불러 온 후, 모델에 저장
9. Calculate Classification Accuracy on Test Set
correct = 0
with torch.no_grad(): ## 학습하지 않기 위해
best_model.eval()
y_pred = best_model(x_test.cuda())
pred = y_pred.data.max(1, keepdim=True)[1]
correct = pred.cpu().eq(y_test.data.view_as(pred)).cpu().sum()
eval_accuracy = correct / len(y_test)
print(f"Test accuracy: {100.* eval_accuracy:.4f}")'Study > Deep Learning' 카테고리의 다른 글
| 하이퍼파라미터 튜닝 ① (1) | 2024.04.17 |
|---|---|
| CNN(합성곱 신경망) ④ [Digits] (0) | 2024.04.17 |
| CNN(합성곱 신경망) ② [MNIST] (0) | 2024.04.14 |
| CNN(합성곱 신경망) ① (1) | 2024.04.13 |
| 딥러닝과 신경망 ② (0) | 2024.04.12 |



