
학습 목표
CNN 디자인 패턴 다루기
LeNet, AlexNet, VGGNet, GoogLeNet, ResNet 등의 신경망 구조 이해하기
학습 내용
다섯가지 최신 합성곱 신경망 구조를 살펴본다.
1. CNN의 디자인 패턴
CNN을 이용한 딥러닝 모델 설계 시 사용하는 기존 패턴 구조
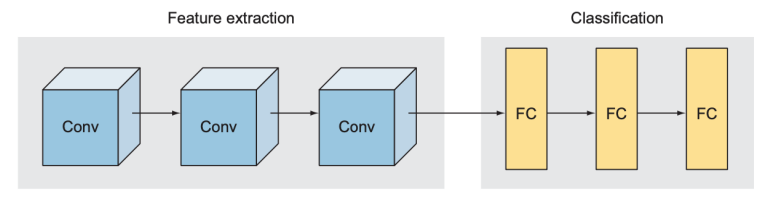
첫번째 패턴 - 특징 추출과 분류
합성곱 신경망은 크게 특징 추출을 맡는 부분과 분류를 맡는 부분으로 나뉨
특징 추출을 맡는 부분은 일련의 합성곱층(CNN), 분류를 맡는 부분은 전결합층(FC Layer)으로 구성됨
LetNet, AlexNet, 인셉션, ResNet 거의 모든 합성곱 신경망이 이 구조를 따름
두번째 패턴 - 이미지 깊이는 증가, 크기는 감소
모든 층의 입력은 이미지
각 층은 이전 층에서 생성된 새로운 이미지에 합성곱 연산을 적용함
이미지는 높이, 폭, 깊이를 가진 3차원 대상이며, 깊이는 색상 채널(color channel)이라고도 함
- 입력층에서 깊이가 1이면 회색조 이미지, 3이면 컬러 이미지를 의미
- 이후 계층에서 깊이는 색상 채널 대신 이전 층에서 추출된 특징을 나타내는 특징 맵이 됨
합성곱층을 지날 때마다 이미지의 깊이가 증가하고 크기는 감소하는 경향은 모든 합성곱 신경망 공통으로 나타나는 특징임
세번째 패턴 - 전결합층
대부분 모든 전결합층은 유닛 수가 같거나, 이어지는 유닛 수가 감소하는 패턴을 보임
이어지는 층에서 유닛 수가 증가하는 경우는 거의 없음
이어지는 모든 전결합층의 유닛을 같게 해서 신경망의 학습 능력이 저해되는 현상은 발생되지 않음
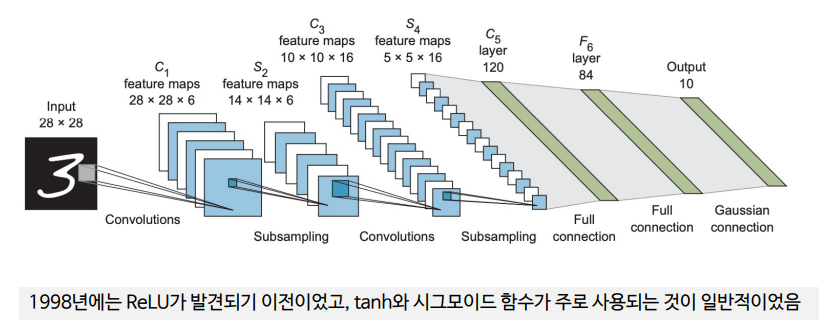
2. LeNet-5
1998년 르쿤 연구진이 발표함
직관적인 구조를 가졌음
LeNet-5는 가중치를 가진 5개의 층(3개의 합성곱층과 2개의 전결합층)으로 구성되었기 때문에 이러한 이름이 붙음

(1) 구조
입력이미지=>C1=>TANH=>S2=>C3=>TANH=>S4=>C5=>TANH=>FC6=>SOFT MAX7
(C는 합성곱층, S는 풀링층(서브 샘플링층), FC는 전결합층)
(2) LeNet-5 구현
각 합성층의 필터 수
C1: 6, C3:16, C5:120
각 합성층의 커널 크기
Kernel_size의 값을 5x5라고 언급
풀링층(서브샘플링층)
수용 영역의 크기는 2x2, 최대 풀링 대신 평균 풀링 사용
활성화 함수
Tanh 함수를 사용, 시그모이드 함수에 비해 가중치가 더 빨리 수렴한다고 생각함

(3) 하이퍼파라미터 설정
LeNet-5는 미리 설정된 일정엔 맞춰 학습률을 감소시키는 학습률 감쇠를 사용 (처음 2 에포크에는 0.005, 그 다음 3 에포크는 0.0002, 다시 그 다음 4 에포크에는 0.00005, 그 이후로는 0.00001의 학습률이 적용)
논문의 실험에서는 20 에포크까지 학습을 수행
(4) MNIST 데이터셋에 대한 LeNet의 성능
MNIST 데이터셋을 대상으로 LeNet 신경망을 학습하면 99% 이상의 정확도를 확보가능함
은닉층의 활성화 함수를 ReLU로 교체하면 어떤 결과가 나오는지 확인
3. AlexNet
LeNet이 MNIST에 대해 AlexNet 보다 높은 성능을 보임
AlexNet은 복잡도가 높은 이미지넷 문제 해결을 위해 제안된 신경망임
AlexNet은 2012년 ILSVRC 이미지 분류 콘테스트에서 우승을 차지함
알렉스크리체프스키 연구진은 새로운 신경망 구조를 120만장의 이미지, 1000가지 클래스로 구성된 <이미지넷 데이터셋>으로 학습 시켰음
AlexNet 은 발표 당시 세계 최고의 성능을 자랑하며 컴퓨터비전분야에서 본격적인 딥러닝을 최초로 도입하여 합성곱 신경망의 응용이 확산되는 계기가 되었음
AlexNet은 LeNet과 구조가 유사하지만 훨씬 층수가 많고, 규모가 큼(한 층당 필터 수가 많음)
일력의 합성곱층과 풀링층의 조합이 이루어진 후 전결합층이 이어지다 소프트맥스 함수를 활성화 함수로 사용하는 출력층 기본 구조는 둘다 비슷
LeNet 신경망 구조는 6만여 개의 파라미터를 가졌음
AlexNet은 65만개 뉴런과 6천만개의 파라미터를 가졌음
AlexNet은 LeNet보다 훨씬 복잡한 특징을 학습할 수 있었고, 덕분에 2012년 ILSVRC 이미지 분류 콘테스트에서 두각을 나타내는 요인이 되었음
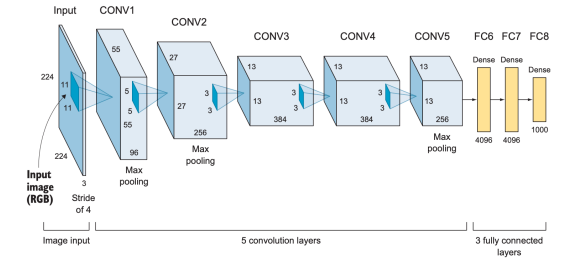
(1) AlexNet 구조
합성곱층의 필터 크기: 11x11, 5x5, 3x3
최대 풀링 사용
과적합 방지를 위한 드롭아웃 적용
은닉층의 활성화 함수는 ReLU, 출력층의 활성화 함수는 소프트맥스 함수 사용
입력이미지=>Conv1=>Pool2=>Conv3=>Pool4=>Conv5=>Conv6=>Conv7=>Pool8=>FC9=>FC10=>SOFTMAX7
(2) AlexNet에서 발전된 부분
AlexNet이 나오기 전에는 음성 인식 등 소수 분야에서만 딥러닝이 적용되고 있었음
AlexNet을 활용하여 이미지넷 대회에서의 우수한 성능을 보인 결과 컴퓨터 비전 분야의 많은 연구자들이 딥러닝을 새로운 돌파구로 생각하게 되었음
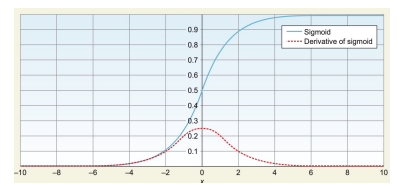
1) ReLU를 활성화 함수로 사용
ReLU를 은닉층의 활성화 함수로 활용해서 학습 시간을 크게 단축 시켰음
기울기 소실 문제(vanishing gradient problem)로 sigmoid/tanh 함수의 경우 빠른 학습에 어려움이 있었음
2) 드롭아웃층
드롭아웃층은 신경망 모델의 과적합을 방지하기 위한 것
드롭아웃을 통해 비활성화된 뉴런은 순방향 계산과 역전파 계산에서 모두 배제됨
같은 입력을 가중치를 공유하는 매번 다른 구조의 신경망으로 학습하는 것과 같은 효과
드롭아웃은 뉴런 간의 상호 적응을 방지하고 다양한 조합의 뉴런에 도움을 주는 유용한 특징을 학습하게 됨
AlexNet에는 두 전결합층에서 0.5의 드롭아웃 비율이 적용되었음
3) 데이터 강화
레이블값을 변화시키지 않고 원 데이터만 변형하는 방식으로 데이터 양을 늘리는 기법도 과적합 방지에 효율적
원 데이터를 변형하는 방법으로는 이미지 회전, 반전, 배율 조절 등이 있음
4) 국소 응답 정규화
AlexNet에는 국소 응답 정규화(local response normalization)가 적용되어 있음
국소 응답 정규화는 배치 정규화와 다른 기법임
정규화는 가중치가 빨리 수렴되도록 하는 것이 목적으로 현재는 '국소 응답 정규화' 대신 '배치 정규화'가 많이 사용됨
5) 가중치 규제화
AlexNet은 0.00005의 가중치 감쇠가 적용되었음
가중치 규제화는 L2 규제화와 같은 개념
6) 다중 GPU 사용
AlexNet 연구진은 3GB 비디오램이 장착된 GTX 580을 사용하여 학습을 진행함
GTX 580은 당시 최신 제품이었지만 1200만 개나 되는 이미지넷 데이터 셋을 학습하기에는 성능이 충분하지 못했음
이에 신경망을 2개의 GPU에 나눠 담아 학습하는 복잡한 방식(각 층을 두 GPU 메모리에 분리하고 이들 GPU가 서로 통신하는 것)을 개발했음
오늘날에는 분산 GPU 환경에서 딥러닝 모델을 학습하는 기법이 매우 발전하였음
(3) AlexNet 구현
AlexNet 신경망 구조는 가중치가 있는 8개의 층으로 구성됨
앞의 다섯층은 합성곱층(CNN)이며, 이어지는 세 층은 전결합층(FC layer)임
마지막 전결합층의 출력은 뉴런이 1000개인 소프트맥스층으로 이어지며, 1000개의 클래스에 대한 예측 확률을 출력함
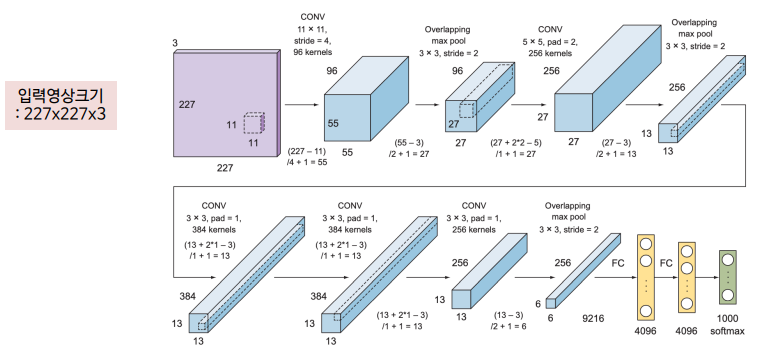
Conv1: 가장 큰 커널 크기(11)와 스트라이드 값(4)이 적용되어 출력 이미지가 입력 이미지 크기의 ¼ 로 줄어듬 (227x227è55x55). 출력 깊이(필터수)는 96이므로 채널을 포함한 출력의 실제 크기는 55x55x96이 됨

필터 크기가 3x3인 Pool: 55x55의 입력이 27x27로 줄어듬. 풀링층은 이미지의 깊이에는 영향을 주지 않아 실제 크기는 27x27x96이 됨

(4) 하이퍼파라미터 설정
AlexNet은 90 에포크를 학습했으며, GTX 580 GPU를 동시에 사용해서 6일이 소요
초기에는 학습률을 0.01, 모멘텀은 0.9로 설정했으며, 검증 오차가 개선되지 않을 때마다 학습률을 이전의 1/10로 조정했음
(5) AlexNet의 성능
AlexNet은 2012 ILSVRC에서 크게 두각을 나타냈음
15.3%의 Top-5오차율을 기록했음
기존 분류기를 사용했던 2위 참가자의 성적과 26.2%의 차이를 보였음
이 성과는 컴퓨터 비전 학계를 놀라게 했고, 이후 복잡한 시각 문제에 합성곱 신경망이 도입되고 이후 고급 합성곱 신경망 구조가 속속 개발되는 계기가 되었음

'Computer Science > Deep Learning' 카테고리의 다른 글
| 전이학습(Transfer Learning) (1) (0) | 2024.06.09 |
|---|---|
| 고급 합성곱 신경망 ② (0) | 2024.04.17 |
| 하이퍼파라미터 튜닝 ② [CIFAR-10] (0) | 2024.04.17 |
| 하이퍼파라미터 튜닝 ① (1) | 2024.04.17 |
| CNN(합성곱 신경망) ④ [Digits] (0) | 2024.04.17 |



