
1. 전이학습으로 해결할 수 있는 문제
- 전이학습이란 신경망이 어떤 과제에서 얻은 기존 지식(어떤 데이터셋을 학습하며 익힌 것)을 비슷한 다른 문제를 해결하는데 활용하는 것
- 어떤 과제에서 익힌 기존 지식이란 학습과정을 통해 얻어진 추출된 특징(특징 맵 (Feature Map))을 말함
- 딥러닝 분야에서 전이학습이 활발히 이용되는 이유는 더 짧은 시간에 적은 양의 데이터로 신경망을 학습할 수 있음
- 전이학습의 가장 큰 장점은 이미지넷 등 일반적인 컴퓨터비전벤치마크용 데이터셋으로 학습한 모델의 가중치를 간단히 재사용하는 것만으로 다른 문제를 위한 대규모 데이터 수집(레이블링된 데이터)에 드는 수고를 절감할 수 있다는 것
- 전이학습의 또 다른 장점은 일반화 성능을 확보하고 과적합을 방지하는 것
2. 전이학습이란?
신경망이 어떤 task을 위해 많은 양의 데이터를 이용해 학습한 지식(모델가중치)을 학습 데이터가 상대적으로 적은 다른 유사한 과업으로 옮겨오는 것을 말함
(1) 사전 학습된 신경망을 특징 추출기로 활용하는 방법
고양이와 개의 이미지를 분류하는 분류기를 학습하려 할 때 전이학습을 활용
① 해결하려는 문제와 비슷한 특징을 갖는 데이터셋을 물색 (문제와 가장 비슷한 오픈 소스 데이터셋 찾기) → 이미지넷 사용
② 이미지넷 데이터셋으로 학습되었고 준수한 성능을 보이는 신경망을 선택 → 이미지넷 데이터셋으로 학습된 VGG16 신경망 활용
③ 사전 학습된 가중치를 포함하는 VGG16 모델을 내려 받은 다음 분류기 부분을 수정 및 새로 만들어 추가한 후, 새로 구성한 신경망을 학습
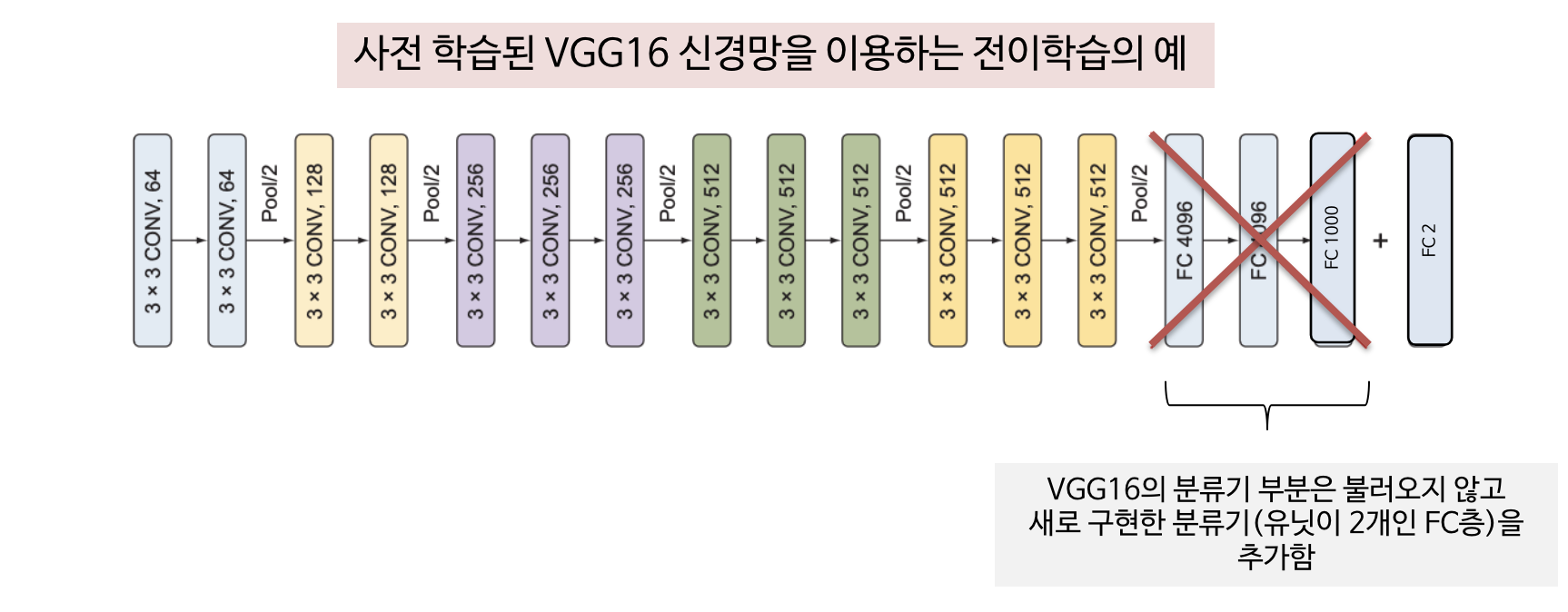
(2) 사전학습된 신경망 이용
1) 가중치를 포함한 VGG16 신경망의 오픈 소스 구현을 내려받아 기반 모델을 만듦

2) 모델의 개요를 출력해보면 VGG16의 신경망 구조와 일치하는 것을 알 수 있음

- 딥러닝 라이브러리에서 제공하는 주요 신경망을 내려받아 이용하면 별도의 모델 학습 시간을 절약할 수 있음
- 주요 신경망 내려 받는 방식 : (신경망 구현 + 가중치) 혹은(가중치만)
3) 특징 추출기 부분에 해당하는 층의 가중치는 고정
“가중치를 고정시킨다"라는 것은 미리 학습된 가중치가 추가 학습으로 변하지 않도록 한다는 것을 의미함 (기존 지식을 활용하는 것)

4) 새로운 분류기 추가
- 분류 대상 클래스가 2개 이므로 유닛이 2개인 FC층 추가
- Pytorch는 CrossEntropyLoss 내에 softmax 연산이 포함되어 있음

5) base_model의 입력을 입력으로, FC 출력을 사용하는 새로운 모델 구축
새 모델은 VGGNet의 측징 추출기 + 아직 학습되지 않은 새 FC층으로 구성됨

3. 전이학습의 원리
- 학습된 신경망 : 가중치 학습과 하이퍼파라미터 튜닝을 거쳐 신경망이 만족스러운 성능을 보이게 된 상태
- 모델 학습이 끝나면 “신경망 구조”와 “학습된 가중치” 두 가지가 결과물로 남음
- 사전 학습된 신경망을 활용하기 위해서는 신경망 구조와 가중치를 함께 내려받음
- 학습 중에 특징이 학습되려면 훈련 데이터에 포함된 특징이어야 함
- 대규모 모델(VGG, ResNet, GoogleNet 등)은 대규모 데이터셋(이미지넷 등)을 대상으로 학습되므로 거의 모든 특징이 이미 추출되어 사용할 수 있는 상태가 됨
- 사전 학습 모델에는 새로운 학습 데이터(새로운 과업용)에 포함되어 있지 않았던 특징까지도 포함되어있어 다른 신경망을 학습하는데 도움을 줌
- 컴퓨터비전 문제 해결을 위해서는 저수준 특징(모서리, 꼭짓점, 다양한 도형)부터 중수준(눈, 원, 사각형, 바퀴) 또는 고수준 특징까지 다양한 특징을 학습해야 함
- 합성곱신경망이 포착할 수 있는 이미지의 세부 사항은 매우 많지만 1000장 또는 25000장 정도의 데이터로는 과업 해결을 위한 특징을 모두 학습하기 어려움
- (대용량 데이터셋으로 학습된) 사전학습된 신경망을 사용함으로써 기존에 배운 지식을 내려받아 새로운 신경망에 포함시킬 수 있고, 빠른 학습과 더 높은 성능을 얻을 수 있음

(1) 신경망이 특징을 학습하는 방법
- 신경망은 단순한 것부터 각 층마다 차근차근 복잡도를 올려가며 특징을 학습함
- 이렇게 학습된 특징을 특징맵이라고 함
- 신경망의 뒤쪽 층으로 갈수록 이미지의 특징적인 특징이 학습됨
- 첫번째 층은 모서리나 곡선 같은 저수준 특징을 포착
- 두번째 층은 원이나 사각형 같은 중수준 특징을 포착
- 첫번째 층의 출력이 두번째 층의 입력으로 활용
- 즉, 앞쪽 층의 특징을 모아 대상의 일부를 구성
- 층을 거쳐가며 보다 복잡한 특징을 나타내는 활성화 맵(Activation Map)이 생성됨
- 고차원 특징을 인식하는 층은 입력된 특징 중 해당 대상을 구별하는데 중요한 특징은 증폭하고 그렇지 않은 특징은 억제함

저수준 특징 : 거의 대부분 다른 어떤 과업에서도 활용할 수 있는 일반적인 정보만 담김
고수준 특징 : 과업에 특화되며 다른 과업에서 재사용하기 어려워짐

(2) 뒤쪽 층에서 학습된 특징의 재사용성
- 신경망의 뒤쪽 층에서 학습된 특징의 재사용 가능 여부는 기존 모델 학습에 사용한 데이터셋과 새로운 데이터셋의 유사성과 관계가 깊음
- 모든 이미지에서 모서리나 직선을 찾아볼 수 있으므로 저수준 특징(앞쪽 층)은 서로 다른 과업에서도 재사용 가능함, 그러나 고수준 특징은 과업마다 크게 다름
- 따라서 원 도메인과 목표 도메인의 유사성에 따라 고수준 내지 중수준 특징의 재사용 여부를 판단항 수 있음
4. 전이학습의 세 가지 방식
- 전이학습 방식은 ①사전학습된 신경망을 분류기로 이용하거나 ②사전학습된 신경망을 특징 추출기로 이용하거나 ③미세 조정으로 이용하기 등 세가지로 크게 나뉨
- 전이학습의 세 가지 방식 모두 층수가 많은 CNN 모델을 구축하고 학습하는 과정에서 상당한 시간을 절약 할 수 있으며 뛰어난 성능을 얻을 수 있음
(1) 사전학습된 신경망을 분류기로 이용하기 → 견종 분류기
사전 학습된 신경망을 분류기로 이용하는 방식은 사전 학습된 신경망의 가중치를 고정하거나 추가적인 학습이 불필요함
비슷한 과업에 대해 학습된 신경망을 골라 직접 새로운 과업에 그대로 투입하는 방식
원 도메인과 목표 도메인이 매우 유사하고, 사전 학습된 신경망을 즉시 사용할 수 있는 경우에 적용함
이미지넷 데이터셋을 학습된 VGG16 신경망을 그대로 사용할 수 있음
- 이미지넷 데이터에는 개 이미지가 많이 포함되어 있으므로 견종을 구분하는데 필요한 특징의 상당수가 이미 추출되어 있음



(2) 사전 학습된 신경망을 특징 추출기로 이용하기 → 개/고양이 분류기
이미지넷 데이터셋을 학습한 CNN의 특징 추출기 부분 가중치를 고정하고 분류기 부분을 제거한 다음 새로운 분류기 부분을 추가하여 문제 해결
원 도메인의 데이터셋과 새로운 과업이 큰 차이가 없을 때 사용하는 방식
- 이미지넷 데이터셋에는 고양이나 개 이미지를 상당수 포함하고 있기 때문에 개/고양이 분류기와 같은 새로운 과업에 사용할 수 있음
- 즉, 이미지넷 데이터셋에서 추출한 고수준 특징을 다른 과업에 재사용할 수 있음
사전 학습된 신경망의 가중치를 모두 고정하고 새로 추가한 분류기 부분의 전결합층만 새로운 데이터셋으로 학습 진행
- 사전 학습된 신경망의 분류기 부분은 원 분류 과업에 특화된 경우가 많고, 이후 모델이 학습된 클래스셋에만 한정되기 때문에 제거해야 함 - 예를들어 이미지넷은 1000개 이상의 분류 클래스가 있으므로 기존 신경망의 분류기 부분 역시 1000가지로 분류하도록 설계 및 학습되었으므로 개와 고양이만 분류하면 되는 새로운 과업에서는 새로운 분류기 부분을 만들어 추가하는 것이 훨씬 효율적임
(3) 미세 조정하기
- 목표 도메인과 원 도메인이 많이 동떨어진 경우 (전혀 다른 경우 포함), 미세 조정(fine-tuning)을 거쳐 문제를 해결할 수 있음
- 미세 조정의 정의는 특징 추출에 쓰이는 신경망의 일부 층을 고정하고 고정하지 않은 층과 새로 추가된 분류기 부분의 층을 함께 학습하는 방식임
- 이 방식을 미세 조정이라 부르는 이유는 특징 추출기 부분을 재학습 하면서 고차원 특징의 표현이 새로운 과업에 적합하게 조정되기 때문임

- 미세 조정의 특징 맵 고정 범위는 대개 시행착오를 통해 결정됨
- 하지만 직관적으로 따를 수 있는 가이드라인도 존재함
- 학습 데이터 양과 원 도메인과 목표 도메인의 유사성, 두가지 요소의 의해 결정됨
- 네 가지 시나리오를 상정해 적합한 특징 맵의 보전 범위를 살펴보려함
1) 미세 조정이 모델을 처음부터 학습시키는 것보다 나은가?
- 미세 조정의 이점은 사전 학습된 신경망의 가중치는 이미 학습 데이터를 학습하며 최적화된 상태이므로 새로운 문제에서 재사용하면 한번 최적화된 가중치를 대상으로 학습이 진행됨
- 따라서 무작위 값으로 초기화된 가중치와 비교하면 가중치 수렴이 빨리 일어남
- 사전 학습된 신경망 전체를 재학습 하더라도 처음부터 모델을 학습시키는 것(스크래치 단계에서부터 학습) 보다 학습 속도가 빠름
2) 미세 조정에서는 학습률을 작게 설정한다
- 미세 조정에서는 합성곱층의 학습률을 무작위 값으로 초기화된 가중치를 가진 분류기 부분보다 작게 설정함
- 이미 최적값에 가까워서 바르게 수정할 필요가 상대적으로 적기 때문
'Study > Deep Learning' 카테고리의 다른 글
| 전이학습(Transfer Learning) [개, 고양이 분류] (3) (0) | 2024.06.09 |
|---|---|
| 전이학습(Transfer Learning) (2) (1) | 2024.06.09 |
| 고급 합성곱 신경망 ② (0) | 2024.04.17 |
| 고급 합성곱 신경망 ① (0) | 2024.04.17 |
| 하이퍼파라미터 튜닝 ② [CIFAR-10] (0) | 2024.04.17 |



