
5. 적합한 전이학습 수준 선택하기
전이학습의 적합한 수준을 결정하는 중요한 요소
- 목표 데이터셋의 크기 (많음 또는 적음) : 목표 데이터셋의 크기가 작다면 많은 층을 학습시키기 어렵고 새로운 데이터에 대해 과적합을 일으키기 쉬움. 이런 경우에는 미세 조정 범위를 줄이고 원 데이터셋의 의존도를 높여야 함
- 원 도메인과 목표 도메인의 유사성 : 해결하려는 문제가 자동차와 배를 분류하는 것이라면 비슷한 특징을 다수 포함하는 이미지넷 데이터셋으로도 충분함. 반면 새로운 문제가 엑스레이 사진에서 폐암 병변을 찾아내는 것이라면 도메인이 전혀 달라지므로 미세 조정 범위가 넓어져야 함
전이학습의 적합한 수준을 결정하는 네 가지 시나리오
- 목표 데이터셋의 크기가 작고, 원 도메인과 목표 도메인이 유사
- 목표 데이터셋의 크기가 크고, 원 도메인과 목표 도메인이 유사
- 목표 데이터셋의 크기가 작고, 원 도메인과 목표 도메인이 크게 다름
- 목표 데이터셋의 크기가 크고, 원 도메인과 목표 도메인이 크게 다름
(1) 시나리오 1 : 목표 데이터셋의 크기 작고, 두 도메인이 유사한 경우
- 원-목표 데이터셋이 서로 유사하므로 사전 학습된 고수준 특징도 재사용 가능
- 따라서 특징 추출기 부분의 가중치를 고정하고 분류기 부분만 새로 학습
- 미세 조정이 유리하지 않은 또 다른 이유는 목표 데이터셋의 크기가 작기 때문
- 특징 추출기에 해당하는 층을 미세 조정 범위에 포함시키면 과적합이 발생하기 쉬움
- 데이터 셋의 크기가 작으면 대상의 모든 가능한 특징을 담지 못할 가능성이 높기 때문에 일반화 성능이 떨어짐
- 따라서 미세 조정 범위를 넓힐수록 신경망이 과적합을 일으킬 가능성이 높음
- 예를 들어 목표 데이터셋의 개 이미지가 특정 날씨 조건(눈)에 국한되었다면 개의 특징으로 눈이 내린 희 배경을 포착할 것이므로 다른 날씨에 찍힌 개 사진을 제대로 분류하지 못할 것임
- 목표 데이터셋의 크기가 작다면 사전 학습된 신경망의 미세 조정 범위를 넓히는데 주의해야 함
(2) 시나리오 2: 목표 데이터셋의 크기가 크고, 두 도메인이 유사한 경우
- 시나리오 1의 해법과 비슷함
- 원-목표 도메인이 유사하므로 특징 추출기 부분의 가중치를 고정하고 분류기 부분을 재학습 하면 됨
- 하지만 목표 도메인에 충분한 데이터가 있으므로 미세 조정 범위를 적절히 넓혀도 과적합에 대한 우려 없이 학습을 진행할 수 있음
- 두 도메인이 비슷하므로 고수준 특징도 서로 비슷하므로 신경망 전체를 미세 조정 범위로 삼을 필요는 없음
- 사전 학습된 신경망의 60~80% 정도를 고정하고 나머지 부분을 목표 데이터셋으로 재 학습 하는 것이 적절하다고 보여짐
(3) 시나리오 3: 목표 데이터셋의 크기가 작고, 두 도메인이 크게 다른 경우
- 원-목표 도메인이 크게 다르므로 사전 학습된 신경망을 도메인에 특화된 고수준 특징까지 고정하는 것은 적절하지 않음
- 앞쪽 층의 일부 저수준 특징을 고정하거나, 특징 재활용 없이 전체 신경망을 미세 조정 범위로 삼는 것이 좋음
- 목표 데이터셋의 크기가 작은 만큼 전체 신경망의 재학습이 어려울 수 있음
- 따라서 이런 경우 중용을 취하도록 함
- 사전 학습된 신경망의 뒷부분 1/3이나 절반 정도의 특징을 고정하는 수준으로 시작하는 것이 적절함
- 도메인이 크게 다르더라도 일반적인 특징 맵(저수준 특징)은 재사용할 수 있음
(4) 시나리오 4: 목표 데이터셋의 크기가 크고, 두 도메인이 크게 다른 경우
- 목표 데이터셋의 크기가 크므로 전이학습 없이 전체 신경망을 처음부터 학습할 수 있다는 유혹에 빠지기 쉬움
- 그러나 실제로는 목표 데이터셋의 크기가 크더라도 사전 학습된 가중치를 재학습하는 것이 더 이로운 경우가 많음
- 학습 시간이 빠른 것은 물론이고, 목표 데이터셋의 크기가 크므로 과적합에 대한 우려 없이 재학습을 진행할 수 있음
(5) 네 가지 시나리오 정리
네 가지 시나리오를 정리해보면 다음과 같음

네 가지 시나리오에 적합한 미세 조정 수준을 제시하는 가이드라인

6. 오픈 소스 데이터셋
(1) MNIST

- MNIST 는 손글씨 이미지 데이터셋
- 0부터 9까지의 숫자가 쓰인 손글씨 이미지로 구성되어 있음
- 이 데이터셋의 목적은 손글씨 숫자 이미지를 분류하는 것
- 연구자들이 분류 알고리즘의 성능을 가늠하는 벤치마크 테스크로 오랫동안 사용해옴
- 이미지 데이터셋의 “hello world”와도 같은 존재
- 그러나 최근 기본적인 합성곱 신경망으로도 99% 성능을 달성하여 최고 성능을 다투는 테스트로서의 역할을 상실함
- 6만 장의 학습 데이터와 1만 장의 테스트 데이터로 구성
- 이미지는 모두 회색조(단일채널)고, 이미지 크기는 가로세로 모두 28픽셀
(2) Fashion-MNIST

- Fashion-MNIST 데이터셋은 현재의 기술 수준에서 지나치게 단순해진 MNIST 데이터셋을 대체하려는 목적으로 만들어짐
- 데이터의 형식은 MNIST와 같지만 손글씨 이미지가 아니라 티셔츠, 바지, 풀오버, 드레스, 코트, 샌들, 셔츠, 운동화, 가방, 단화 등 10가지 패션의류 클래스로 나뉨
(3) CiFAR

- CIFAR-10 컴퓨터 비전이나 머신러닝 문헌에서 널리 사용되는 벤치마크 데이터셋임
- CIFAR 데이터셋의 이미지는 MNIST 데이터셋의 이미지 보다 더 복잡함
- 우선 MNIST 데이터셋의 이미지가 모두 회색조 이미지고 대상 이미지 중심에 위치했던 것이 비해, CIFAR 데이터셋의 이미지는 컬러 이미지고 이미지에 대상이 나타나는 방식도 제각각임
- 10개 클래스로 나뉜 32x32픽셀 크기의 이미지로 구성되며, 각 클래스마다 6000개의 이미지를 포함하고, 학습 데이터 5만장, 테스트 데이터 1만장으로 구성됨
- CIFAR-100은 CIFAR-10 데이터셋을 확장한 데이터셋임
- 클래스가 100개로 늘어났으며 각 클래스마다 600장의 이미지가 있음
- 100개의 클래스는 다시 20개의 슈퍼클래스에 속하는데, 이미지에는 대분류 레이블과 소분류 레이블이 부여되어 있음
(4) ImageNet

- 이미지넷은 컴퓨터 비전 연구자들 사이에서 자신의 분류 알고리즘 성능을 측정하기 위해 널리 사용되는 최신 벤치마크 데이터셋임
- 이미지넷은 본래 물체를 시각적으로 인식하는 소프트웨어를 연구하기 위한 목적으로 만들어진 대규모 이미지 데이터베이스임
- 데이터셋을 구성하는 이미지는 웹에서 수집되어 아마존의 클라우드 소싱 도구인 터크를 이용해 수동으로 레이블이 부여되었음
- 1000개의 클래스로 구성되며, 하나의 클래스에는 1000개 이상의 이미지가 속하도록 구성되어 있음
- 이미지넷을 활용한 대규모 물체 인식 경진대회(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)가 존재하며, 이 경진대회에서는 각 참가팀이 만든 소프트웨어로 이미지에서 물체를 인식하고 분류하는 정확도를 겨룸 § 현재 ILSVRC 대회는 종료되었음
(5) MS COCO

- MS COCO는 물체 인식, 인스턴스 세그먼테이션, 이미지 캡셔닝, 인체 주요 부위 위치 파악 등의 연구를 위해 만든 오픈 소스 데이터베이스임 (2014년 제안)
- 약 32만 8000장의 이미지를 포함하며, 그중 20만장 이상이 레이블이 부여되어 있음
- 이들 이미지에는 4세 어린이가 쉽게 인식할 수 있는 수준의 80개 물체 카테고리에 포함되어 있음
(6) 구글 오픈 이미지
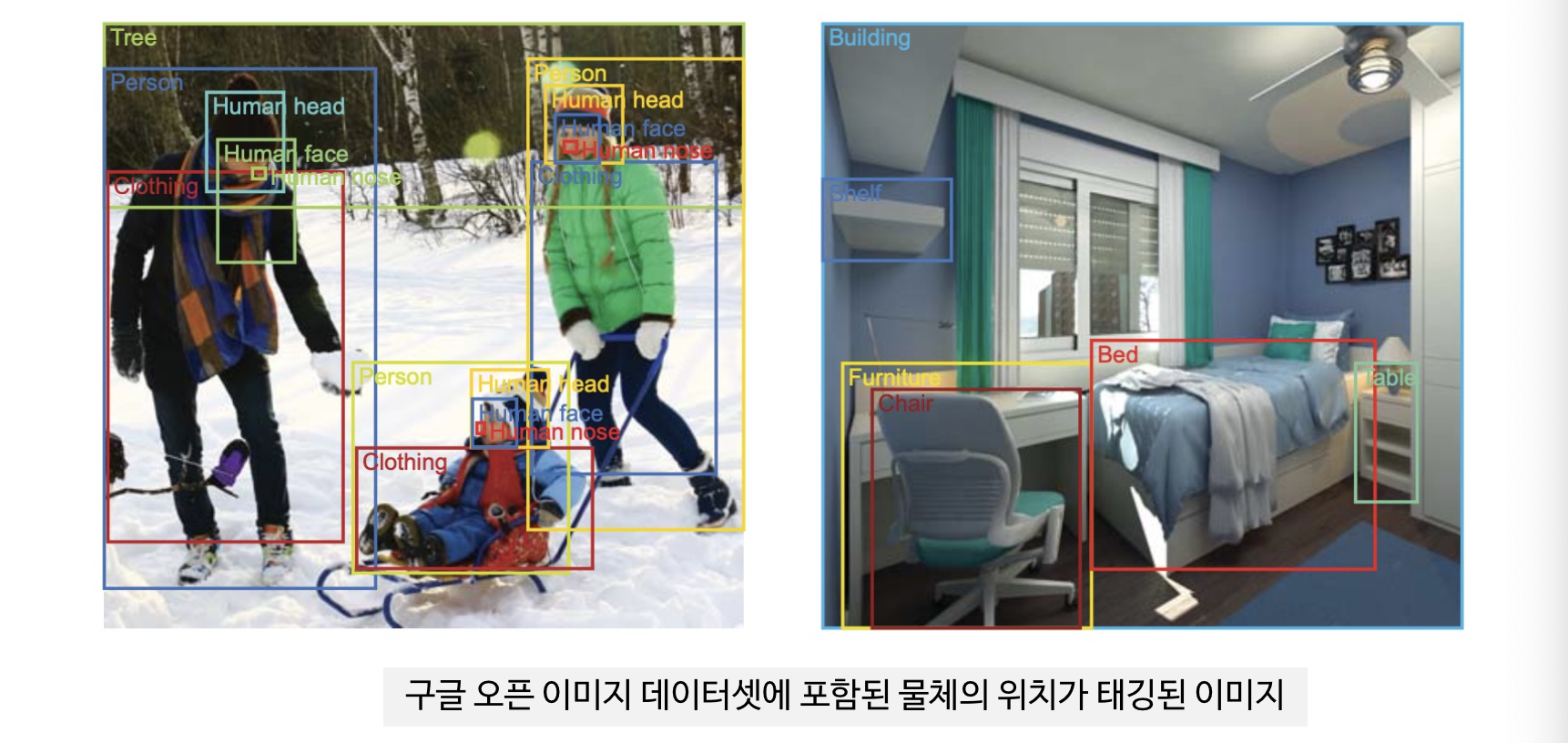
- 구글 오픈 이미지는 구글이 만든 오픈 소스 이미지 데이터베이스임
- 집필 시점 현재 9백만장의 이미지를 포함함
- 구글 오픈 이미지의 특징은 이미지들이 대부분 수천 가지 물체 클래스에 걸쳐 있는 복잡한 장면이라는 점
- 특히 이들 중 2백만장 이상의 이미지는 사람이 직접 물체의 위치를 나타내는 범위를 태깅한 것으로 그 덕분에 구글 오픈 이미지는 물체 위치가 표시된 이미지 데이터베이스 중 가장 규모가 큼
- 이들 이미지에는 약 1500만개의 물체 위치 범위가 태깅되어 있으며, 태깅된 물체 종류도 600클래스에 이름 § 구글 오픈 이미지에도 오픈 이미지 챌린지라는 경진대회가 있음
(7) 캐글 (Kaggle)
- 지금까지 소개한 데이터셋 외에 캐글에서도 좋은 데이터셋을 구할 수 있음
- 캐글은 전 세계사람이 모여 머신러닝이나 딥러닝을 이용한 경진대회를 주최하거나 참가하는 웹사이트임
- 지금까지 소개한 데이터셋 외에도 매일같이 새로운 오픈소스 데이터셋이 공개되고 있어서 이들 데이터를 경험하며 각 데이터셋이 가진 클래스나 유스케이스를 이해하는 능력을 키울 수 있음
7. 프로젝트 1 : 사전 학습된 신경망을 특징 추출기로 사용하기
(1) 개와 고양기 분류기 만들기
본 절에서는 목표 데이터셋의 규모가 작고, 원 도메인과 목표 도메인의 유사성이 높은 <시나리오1> 타입의 전이학습 구현방법을 익힘
이번 프로젝트에서 중요한 점은 사용자 정의 데이터의 전처리 및 신경망 학습에 사용하기 위한 준비 과정을 익히는 것
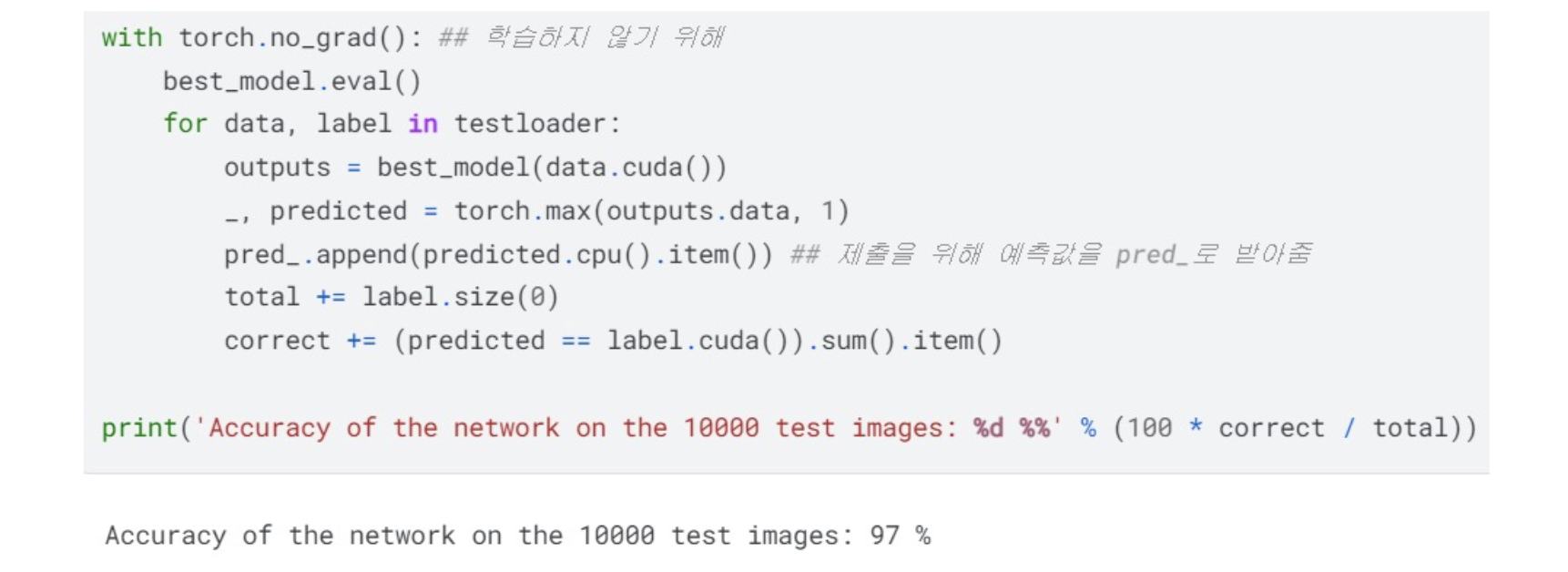
VGG16 을 사용하고 약 96%의 정확도를 얻을 수 있음
사전 학습된 신경망을 특징 추출기로 사용하는 절차
- 필요한 라이브러리를 임포트
- 데이터를 학습에 사용할 수 있도록 전처
- 대규모 데이터셋에서 사전 학습된 VGG16 모델의 가중치 로드
- 합성곱층의 특징 추출기 부분 가중치를 모두 고정
- 사전 학습된 신경망에서 분류기 부분을 제거 및 새로운 분류기 추가
- 신경망을 컴파일하고 새로운 소규모 데이터셋으로 모델 재학습
- 모델의 성능을 평가
추가할 전결합층 수 및 유닛 수에 특별한 제한은 없음. 이번 프로젝트는 복잡하지 않은 문제이므로 64개 유닛을 가진 전결합층 1개를 추가
나중에 성능 추이를 보아 과소적합이 일어난다면 유닛 수를 증가시키고, 과적합이 일어난다면 유닛 수를 줄이면 됨
소프트맥스층의 유닛 수는 분류 대상 클래스 수와 같아야 함
(2) 데이터를 학습에 사용할 수 있도록 전처리
- 데이터 불러오기
- 이번 예제에서는 편의상 데이터 강화는 생략함

(3) 대규모 데이터셋에서 사전 학습된 VGG16 모델의 가중치 로드
분류기 부분을 제거할 것이므로 include_top=False 로 지정

(4) 합성곱층의 특징 추출기 부분 가중치를 모두 고정

(5) 사전 학습된 신경망에서 새로운 분류기 추가

(6) 새로운 소규모 데이터셋으로 모델 재학습
(7) 모델의 성능을 평가
8. 프로젝트 2 : 미세조정
- 목표 데이터셋의 규모도 작고, 원 도메인과 목표 도메인이 매우 다른 경우 (시나리오3)
- 10가지 수화를 구별할 수 있는 분류기 구축

(1) 사전 학습된 신경망을 특징 추출기로 사용하는 절차
- 필요한 라이브러리를 임포트
- 데이터를 학습에 사용할 수 있도록 전처리
- 대규모 데이터셋에서 사전 학습된 VGG16 모델의 가중치 로드
- 합성곱층의 특징 추출기 일부 가중치를 고정
- 새로운 분류기 추가
- 신경망을 컴파일하고 새로운 소규모 데이터셋으로 모델 재학습
- 모델의 성능을 평가
(2) 데이터를 학습에 사용할 수 있도록 전처리
- 데이터 불러오기
- 이번 예제에서는 편의상 데이터 강화는 생략함
(3) 대규모 데이터셋에서 사전 학습된 VGG16 모델의 가중치 로드
분류기 없이 베이스모델을 가져올 예정이므로, VGG16의 features만 대입

(4) 합성곱층의 특징 추출기 중 일부 가중치를 고정

(5) 새로운 분류기 추가하여 모델 완성

(6) 소규모 데이터셋으로 모델 재학습
(7) 모델의 성능을 평가

9. 마치며
- 전이학습은 분류 또는 물체 인식 프로젝트를 시작하는 출발점으로 유용하다. 특히 학습 데이터를 충분히 확보하지 못했다면 더욱 유용하다.
- 전이학습은 원 데이터셋에서 학습된 지식을 목표 데이터셋으로 옮기는 방법으로 학습에 소요되는 계산 자원이나 학습 시간을 절약하는 효과가 있다.
- 신경망은 층수가 깊어질수록 더욱 복잡한 특징을 학습한다. 뒤쪽에 위치한 층일수록 특정 이미지에 가까운 특징이 학습된다.
- 신경망의 앞쪽 층은 직선, 모서리 등의 저수준 특징을 학습한다. 첫 번째 층의 출력이 두 번째 층의 입력이 되며 점차 고수준 특징을 학습한다. 다음 층은 이전 층의 출력을 입력받아 대상의 일부로 조합하고 그 뒤로 이어지는 층이 대상을 탐지한다.
- 전이학습 방식은 사전 학습된 신경망을 분류기로 사용하는 방식, 특징 추출기로 사용하는 방식, 미세 조정 이렇게 크게 세 가지다.
- 사전 학습된 신경망을 분류기로 사용하는 방식은 사전 학습된 신경망을 가중치 고정이나 재학습 없이 그대로 사용하는 방식이다.
- 사전 학습된 신경망을 특징 추출기로 사용하는 방식은 사전 학습된 신경망의 특징 추출기 부분의 가중치를 고정하고 그 외 부분을 재학습해서 사용하는 방식이다.
- 미세 조정은 특징 추출기 부분 중 일부 층의 가중치를 고정하고, 가중치를 고정하지 않은 층과 새로 추가한 분류기 부분을 함께 재학습하는 방식이다.
- 학습된 특징을 다른 신경망으로 옮기는 과정의 성공 가능성은 목표 데이터셋의 규모, 원 도메인과 목표 도메인의 유사성에 따라 결정된다.
- 일반적으로 미세 조정 중의 재학습에는 신경망 부분별로 학습률을 달리 설정한다. 기존 신경망의 가중치를 고정하지 않은 부분은 학습률을 작게 설정하고, 새로 추가한 분류기 부분은 학습률을 크게 설정한다.
'Study > Deep Learning' 카테고리의 다른 글
| 전이학습(Transfer Learning) [수화 이미지 분류] (4) (1) | 2024.06.09 |
|---|---|
| 전이학습(Transfer Learning) [개, 고양이 분류] (3) (0) | 2024.06.09 |
| 전이학습(Transfer Learning) (1) (0) | 2024.06.09 |
| 고급 합성곱 신경망 ② (0) | 2024.04.17 |
| 고급 합성곱 신경망 ① (0) | 2024.04.17 |



