1. Label Map label_map = {
'cat' : 0,
'dog' : 1
}
2. Dataset & Data Loader (1) Custom Dataset class CustomDataset(torch.utils.data.Dataset):
def __init__(self, root_path, split, transform, label_map):
self.split = split.upper()
self.root_path = root_path
self.transform = transform
self.label_map = label_map
self.image = []
self.label = []
######## [1] test 데이터 디렉토리 경로 초기화 ##########
if self.split == 'TEST':
cls = os.listdir(self.root_path)
for c in cls:
cls_path = os.path.join(self.root_path, c)
imgs = sorted(os.listdir(cls_path))
for img in imgs:
self.image.append(os.path.join(cls_path, img))
######## [2] train, valid 데이터 디렉토리 경로, 라벨 초기화 ##########
else:
cls = os.listdir(self.root_path)
for c in cls:
cls_path = os.path.join(self.root_path, c)
imgs = sorted(os.listdir(cls_path))
for img in imgs:
self.image.append(os.path.join(cls_path, img))
self.label.append(c)
######## [3] 전체 데이터 샘플 개수 반환 ########
def __len__(self):
return len(self.image)
def __getitem__(self, idx):
######## [4] 주어진 인덱스에 해당하는 이미지 로드 (PIL 라이브러리 사용) ########
image = Image.open(self.image[idx])
######## [5] 이미지에 transform 적용 ########
image = self.transform(image)
#### [6] test에 사용할 데이터 반환 ########
if self.split == 'TEST':
return image
#### [7] train, valid 에 사용할 데이터 반환 ########
else:
label = self.label_map[self.label[idx]]
return image, label(2) Transform from torchvision.models import VGG16_Weights
transform = VGG16_Weights.DEFAULT.transforms()
transform.resize_size=[224]
print(transform)
(3) Data Loader import torch.nn as nn
import torchvision
batch_size = 30
train_dataset = CustomDataset(root_path=train_path, split='train', transform=transform, label_map=label_map)
valid_dataset = CustomDataset(root_path=valid_path, split='valid', transform=transform, label_map=label_map)
test_dataset = CustomDataset(root_path=test_path, split='test', transform=transform,label_map=label_map)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
3. Model (1) Load Pretrained VGG16 from torchvision.models import VGG16_Weights
model = torchvision.models.vgg16(weights=VGG16_Weights.IMAGENET1K_V1).features(2) 합성곱층의 특징 추출기 부분 가중치를 모두 고정 for param in model.parameters():
param.requires_grad = False(3) 사전 학습된 신경망에서 새로운 분류기 추가 classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512*7*7,64),
nn.BatchNorm1d(64),
nn.Dropout(0.5),
nn.Linear(64,2), # FC Layer : 개, 고양이 분류
)
model.classifier = classifier
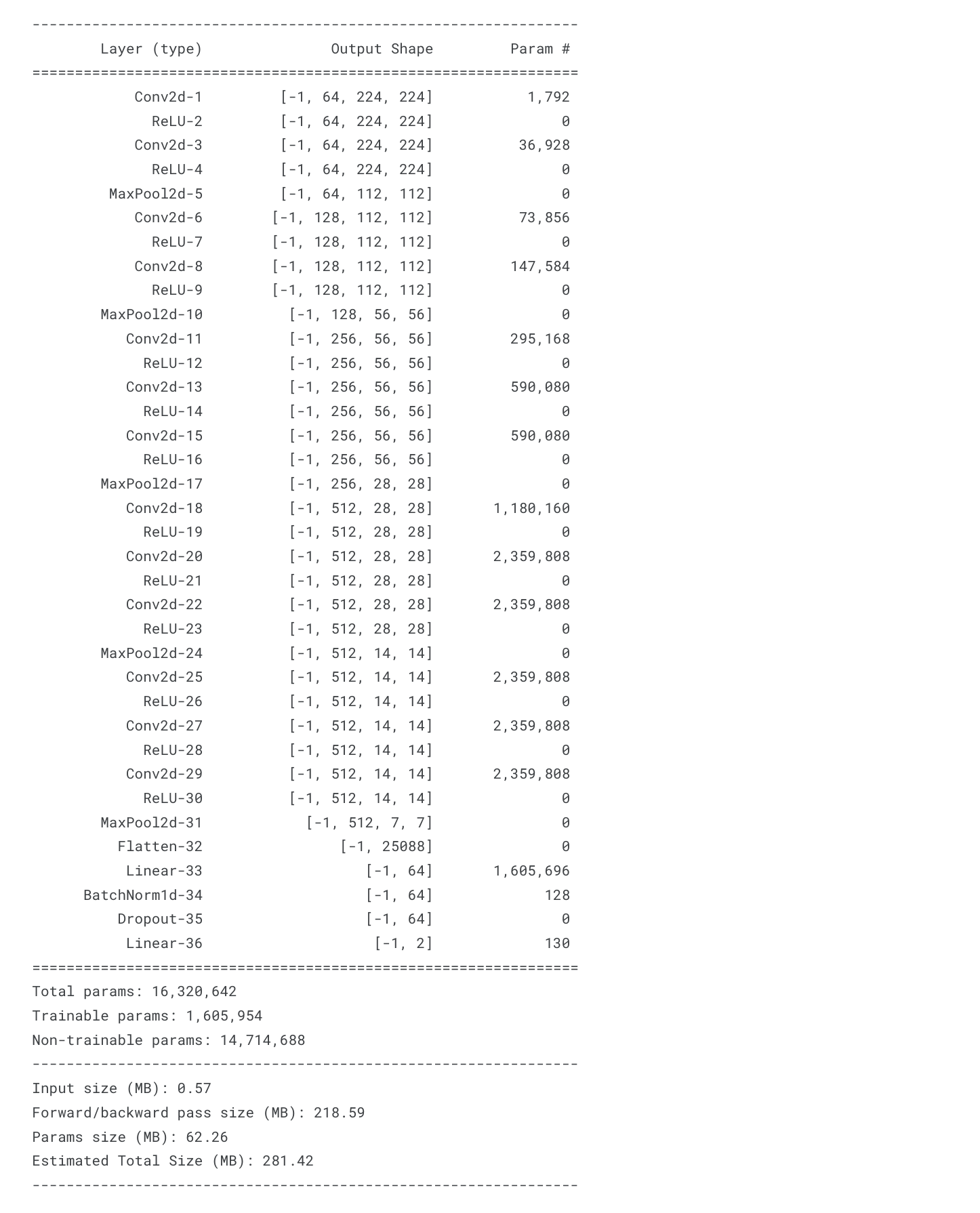
summary_model(model, (3, 224, 224))
4. Train model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
loss = nn.CrossEntropyLoss().cuda()from tqdm import tqdm
total_epoch = 20
best_loss = 100
for epoch in range(total_epoch):
print(f'epoch {epoch}/{total_epoch}')
train_loss = 0
train_acc = 0
for data, label in tqdm(train_loader):
data = data.cuda()
label = label.cuda()
H = model(data)
cost = loss(H, label)
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_loss += cost.item()
pred = H.argmax(dim = 1)
train_acc += (pred == label).sum().item()
train_loss /= len(train_loader)
train_acc /= len(train_loader.dataset)
val_loss = 0
val_acc = 0
with torch.no_grad():
model.eval()
for data, label in tqdm(valid_loader):
data = data.cuda()
label = label.cuda()
H = model(data)
cost = loss(H, label)
val_loss += cost.item()
pred = H.argmax(dim = 1)
val_acc += (pred == label).sum().item()
val_loss /= len(valid_loader)
val_acc /= len(valid_loader.dataset)
if val_loss < best_loss:
torch.save({
'epoch': epoch,
'model': model,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': cost.item,
}, './bestCheckPoint.pth')
print(f'Epoch {epoch:05d}: val_loss improved from {best_loss:.5f} to {val_loss:.5f}, saving model to bestCheckPiont.pth')
best_loss = val_loss
else:
print(f'Epoch {epoch:05d}: val_loss did not improve')
model.train()
print(f'train_loss : {train_loss}, train_acc : {train_acc}, val_loss : {val_loss}, val_acc : {val_acc}')
5. Test best_model = torch.load('./bestCheckPoint.pth')['model']
best_model.load_state_dict(torch.load('./bestCheckPoint.pth')['model_state_dict'])preds = []
with torch.no_grad():
best_model.eval()
for data in tqdm(test_loader):
data = data.cuda()
H = best_model(data)
pred = H.argmax(dim = 1)
preds.extend(pred.tolist())