import torchvision
from PIL import Image
class Custom_dataset(torch.utils.data.Dataset):
def __init__(self, paths, split=None, transform=None):
self.paths = paths
self.split = split
self.transform = transform
self.image = []
self.label = []
if self.split.upper() == 'TRAIN' or self.split.upper() == 'VALID':
cls = sorted(os.listdir(self.paths))
for c in cls:
if c == 'bash_script_to_process_dataset':
continue
cls_path = os.path.join(self.paths, c)
imgs = sorted(os.listdir(cls_path))
for img in imgs:
self.image.append(os.path.join(cls_path, img))
self.label.append(int(c))
else:
cls = sorted(os.listdir(self.paths))
for c in cls:
cls_path = os.path.join(self.paths, c)
imgs = sorted(os.listdir(cls_path))
for img in imgs:
self.image.append(os.path.join(cls_path, img))
# import pdb; pdb.set_trace()
def __len__(self):
return len(self.image) # 데이터 셋의 샘플 개수 반환하기
def __getitem__(self, index):
img = self.image[index] # index번째의 image path 받아오기
img = Image.open(img) # PIL 라이브러리를 사용하여 image 파일 읽기 및 RGB로 변환하기
img = self.transform(img) # image에 transform 적용하기
if self.split.upper() == 'TEST':
return img # test 데이터 셋의 경우 이미지만 반환하기
else: # TRAIN, VALID
return img, self.label[index] # train, valid 데이터 셋의 경우 이미지와 라벨(index번째) 반환하기
(2) Transform
from torchvision.models import VGG16_Weights ## 사전학습된 VGG16를 이용하기 위해 import
transform_ = VGG16_Weights.DEFAULT.transforms() ## VGG16에서 사용한 transform을 이용
transform_.resize_size=[224] ## resize 크기는 224가 되도록 설정
print(transform_) ## transform 확인하기
from torchvision.models import VGG16_Weights
import torch.nn as nn
## Classifier 부분은 제외하고 가져오기
base_model = torchvision.models.vgg16(weights=VGG16_Weights.IMAGENET1K_V1).features
## 마지막에 global_avg_pool2d 추가하기
base_model.global_avg_pool2d = nn.AdaptiveAvgPool2d((1,1))
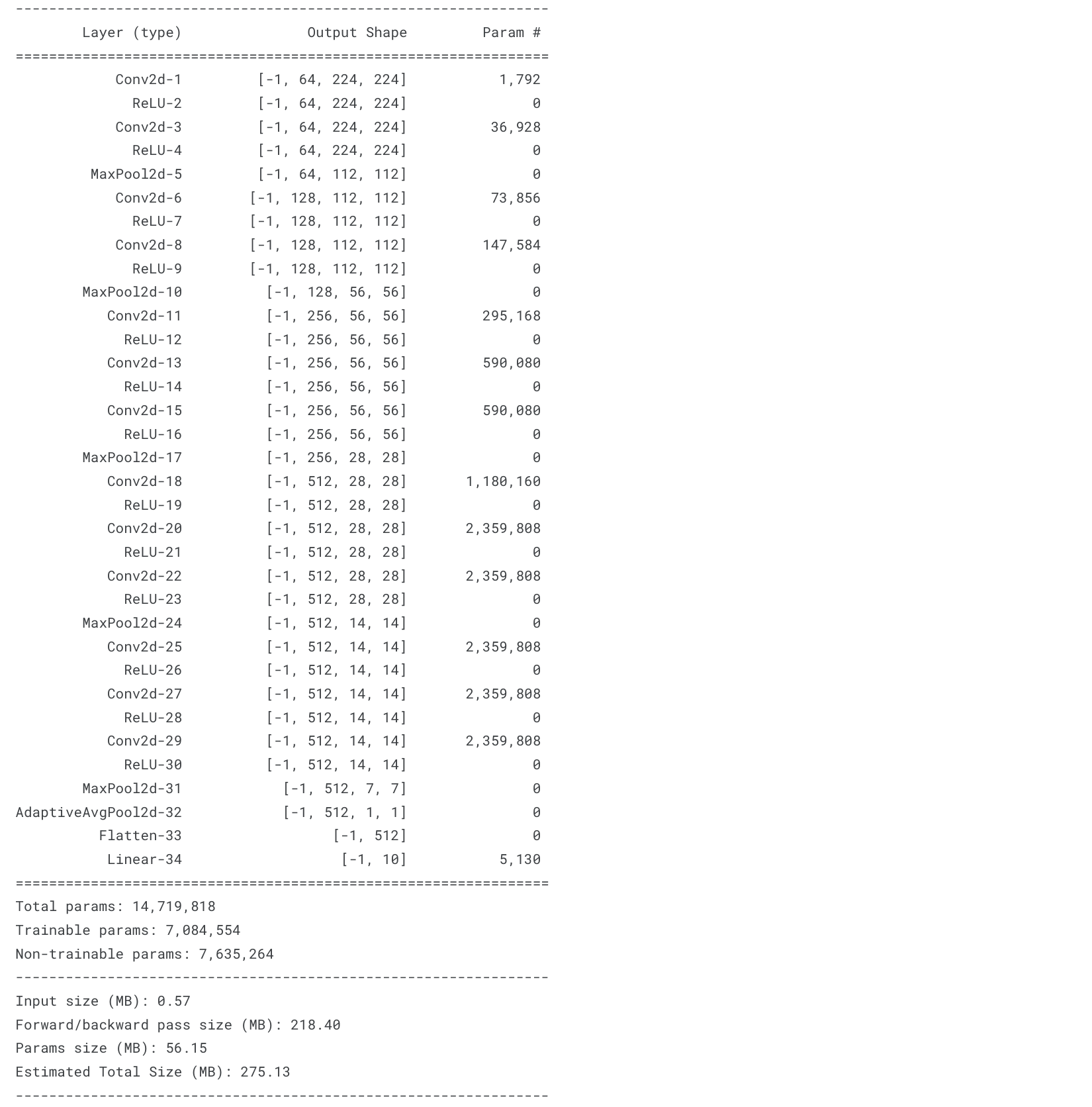
print(base_model)
summary_model(base_model, (3,224,224))
(2) 합성곱층의 특징 추출기 부분 가중치를 모두 고정
## 모델의 뒷단만 학습하도록 하기 위해서 앞부분은 freeze 해주기
for para in base_model[:-8].parameters():
para.requires_grad = False
summary_model(base_model,(3,224,224)) ## 모델 요약 정보 확인
(3) 사전 학습된 신경망에서 새로운 분류기 추가
## Classifier 만들기
classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512,10), ## 512, 7, 7
# nn.Softmax() ## CrossEntropy에 Softmax가 포함되므로 사용하지 않음
)
base_model.classifier = classifier ## 모델에 classifier라는 이름으로 추가
print(base_model)
summary_model(base_model, (3,224,224))## 모델 요약 정보 확인
3. Train
# 모델 학습하기
import time
from tqdm import tqdm
# 파라미터 설정
total_epoch = 10
best_loss = 100 ## loss를 기준으로 best_checkpoint를 저장하기 위해 100으로 설정하였음.
lr_rate = 0.0001
optimizer = torch.optim.Adam(base_model.parameters(), lr=lr_rate)## Adma을 최적화 함수로 이용함. 파라미터는 documentation을 참조!
loss = torch.nn.CrossEntropyLoss().cuda()## 분류문제이므로 CrossEntropyLoss를 이용함
## 모델 시각화를 위해 정확도를 저장할 리스트 생성
train_accuracys=[]
eval_accuracys=[]
for epoch in tqdm(range(total_epoch)):
start = time.time()
print(f'Epoch {epoch}/{total_epoch}')
# train
train_loss = 0
correct = 0
for x, target in train_loader:## 한번에 배치사이즈만큼 데이터를 불러와 모델을 학습함
optimizer.zero_grad()## 이전 loss를 누적하지 않기 위해 0으로 설정해주는 과정
y_pred = base_model(x.cuda())## 모델의 출력값
cost = loss(y_pred, target.cuda())## loss 함수를 이용하여 오차를 계산함
cost.backward() # gradient 구하기
optimizer.step()# 모델 학습
train_loss += cost.item()
pred = y_pred.data.max(1, keepdim=True)[1] ## 각 클래스의 확률 값 중 가장 큰 값을 가지는 클래스의 인덱스를 pred 변수로 받음
correct += pred.cpu().eq(target.data.view_as(pred)).sum() # pred와 target을 비교하여 맞은 개수를 구하는 과정.
# view_as함수는 들어가는 인수의 모양으로 맞춰주고, .eq()를 통해 pred와 target의 값이 동일한지 판단하여 True 개수 구하기
train_loss /= len(train_loader)
train_accuracy = correct / len(train_loader.dataset)
train_accuracys.append(train_accuracy) ## 그래프로 표현하기 위해 리스트에 담음
#Evaluate
eval_loss = 0
correct = 0
with torch.no_grad(): ## 학습하지 않기 위해
base_model.eval()# 평가 모드로 변경
for x, target in valid_loader:
y_pred = base_model(x.cuda())## 모델의 출력값
cost = loss(y_pred, target.cuda())## loss 함수를 이용하여 valid 데이터의 오차를 계산함
eval_loss += cost
pred = y_pred.data.max(1, keepdim=True)[1]## 각 클래스의 확률 값 중 가장 큰 값을 가지는 클래스의 인덱스를 pred 변수로 받음
correct += pred.cpu().eq(target.data.view_as(pred)).cpu().sum()# pred와 target을 비교하여 맞은 개수를 구하는 과정
eval_loss /= len(valid_loader)
eval_accuracy = correct / len(valid_loader.dataset)
eval_accuracys.append(eval_accuracy)## 그래프로 표현하기 위해 리스트에 담음
## valid 데이터의 loss를 기준으로 이전 loss 보다 작을 경우 체크포인트 저장
if eval_loss < best_loss:
torch.save({
'epoch': epoch,
'model': base_model,
'model_state_dict': base_model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': cost.item,
}, './bestCheckPoint.pth')
print(f'Epoch {epoch:05d}: val_loss improved from {best_loss:.5f} to {eval_loss:.5f}, saving model to bestCheckPiont_resnet50.pth')
best_loss = eval_loss
else:
print(f'Epoch {epoch:05d}: val_loss did not improve')
base_model.train()
print(f'{int(time.time() - start)}s - loss: {train_loss:.3f} - acc: {train_accuracy:.3f} - val_loss: {eval_loss:.3f} - val_acc: {eval_accuracy:.3f}')
4. Test
## 저장되어있는 best 체크포인트 load하기
best_model = torch.load('./bestCheckPoint.pth')['model'] # 전체 모델을 통째로 불러옴, 클래스 선언 필수
best_model.load_state_dict(torch.load('./bestCheckPoint.pth')['model_state_dict']) # state_dict를 불러 온 후, 모델에 저장
#prediction
total = 0
pred_ = []
with torch.no_grad(): ## 학습하지 않기 위해
best_model.eval()
for data in tqdm(test_loader):
outputs = best_model(data.cuda())
_, predicted = torch.max(outputs.data, 1)
pred_.append(predicted.cpu().item()) ## 제출을 위해 예측값을 pred_로 받아줌