
1. 앙상블 학습
(1) 목적
여러 분류기를 하나로 연결하여 개별 분류기보다 더 좋은 일반화 성능을 달성하는 것
(2) 방법
여러 분류 알고리즘 사용: 다수결 투표(Voting)
하나의 분류 알고리즘을 여러 번 이용: 배깅(Bagging), 부스팅(Boosting)
(3) 종류
다수결 투표 (Majority Voting)
- 동일한 학습 데이터 사용
배깅(Bagging)
- 알고리즘 수행마다 서로 다른 학습 데이터 샘플링하여 사용
- 병렬적 처리
부스팅(Boosting)
- 샘플 뽑을 때 이전 모델에서 잘못 분류된 데이터를 재학습에 사용 또는 가중치 사용
- 순차적 처리
2. 배깅 (Bagging)
(1) 배깅
알고리즘마다 별도의 학습 데이터를 추출(샘플링)하여 모델 구축에 사용
부트스트랩(Bootstrap) 사용
- 학습 데이터 샘플링 시 복원 추출(중복)을 허용
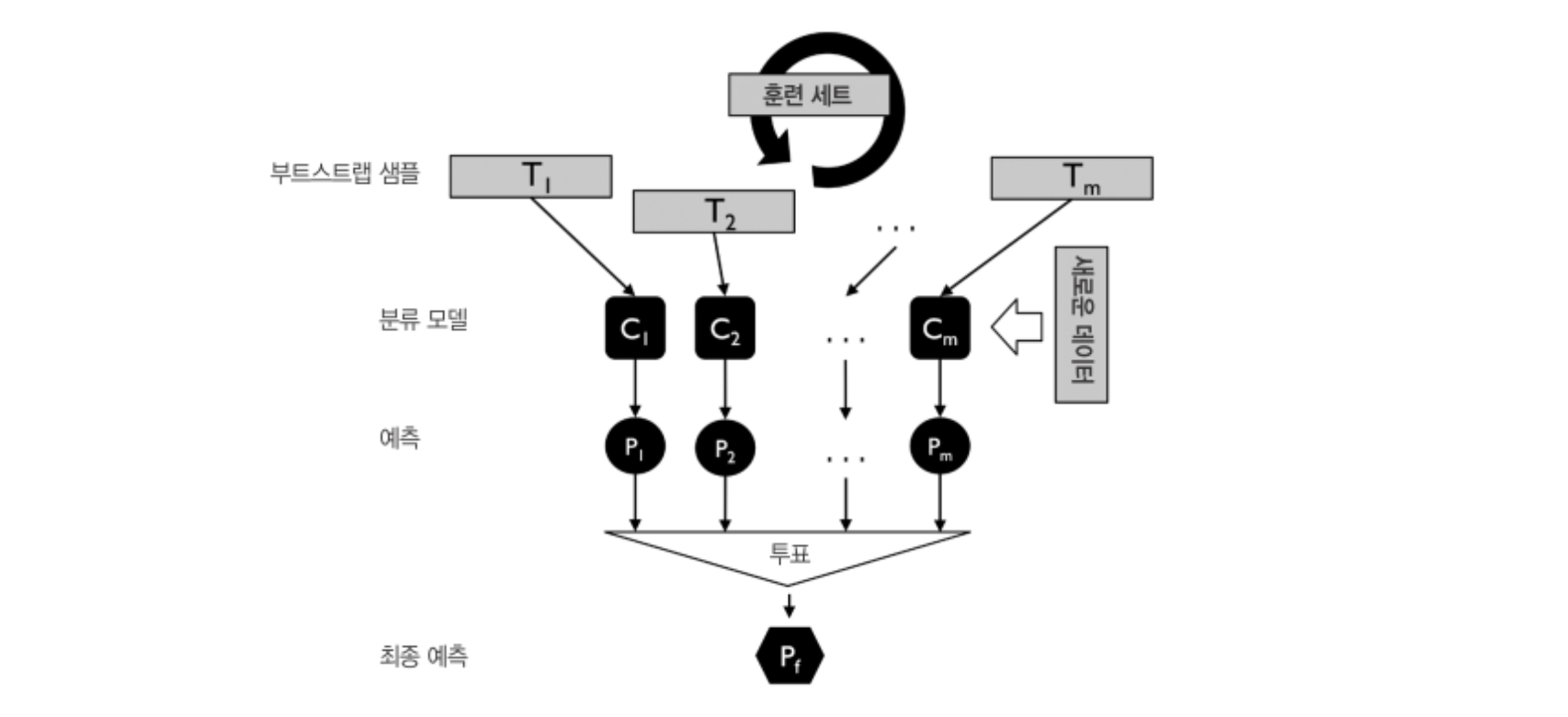
(2) 랜덤 포레스트(Random Forest)
- 배깅의 일종 : 학습 데이터 샘플링
- 단일 분류 알고리즘(Decision Tree) 사용
- Forest 구축 : 무작위로 예측변수 선택하여 모델 구축
- 결합 방식 : 투표(분류), 평균화(예측)
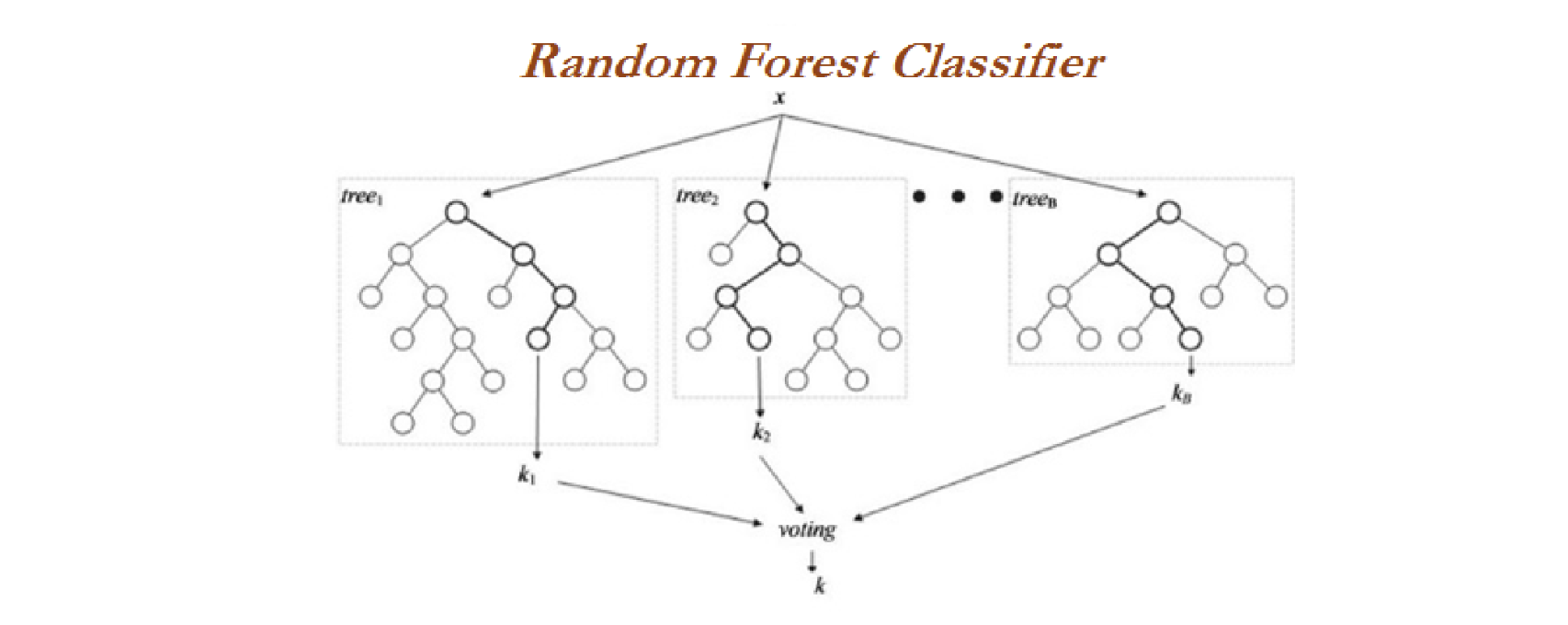
(3) 랜덤 포레스트 (Random Forest) 분석 절차
1) 새로운 학습 데이터를 만듦
- 크기가 n이고 d개의 특성 변수를 가지는 학습 데이터
- Bootstrap을 고려한 n개의 새로운 학습 데이터 구성
2) 새로운 학습 데이터를 이용하여 의사결정나무를 완성
- d개의 특성 변수 중 임의로 k개의 특성 변수를 뽑아 의사결정나무 구성
- K는 일반적으로 $\sqrt{d}$를 선택함
3) 절차 1-2를 M번 반복
- M(트리의 수)이 커질수록 성능이 좋아짐
- 리소스를 고려하여 가능한 큰 M을 선택
3. 통계적 머신러닝의 특징
적절한 알고리즘 선택 시 고려해야 할 것

4. 부스팅(Boosting)
아다부스트(AdaBoost)
순차적으로 weak learner(임의 분류(Random guessing) 보다 약간 좋은 모델)를 적용하여 모델을 구성하는 방법
- Weak learner의 조합을 통해 strong learner 만들기
Weak learner 추가시
- 전체 학습데이터 사용
- 잘못 분류된 데이터에 가중치 적용 (앞선 모형이 잘 풀지 못하는 hard cases를 더 잘 풀어보기 위함)

5. Ensemble: Gradient Boosting Machine(GBM)
- 회귀, 분류 문제를 위해 모두 사용 가능
- Gradient Boosting = Gradient Descent + Boosting

(1) 손실함수
- 회귀 : Squared Loss, Absolute Loss, Huber Loss, Quantile Loss, etc.
- 분류 : Bernoulli Loss, Adaboost Loss, etc.
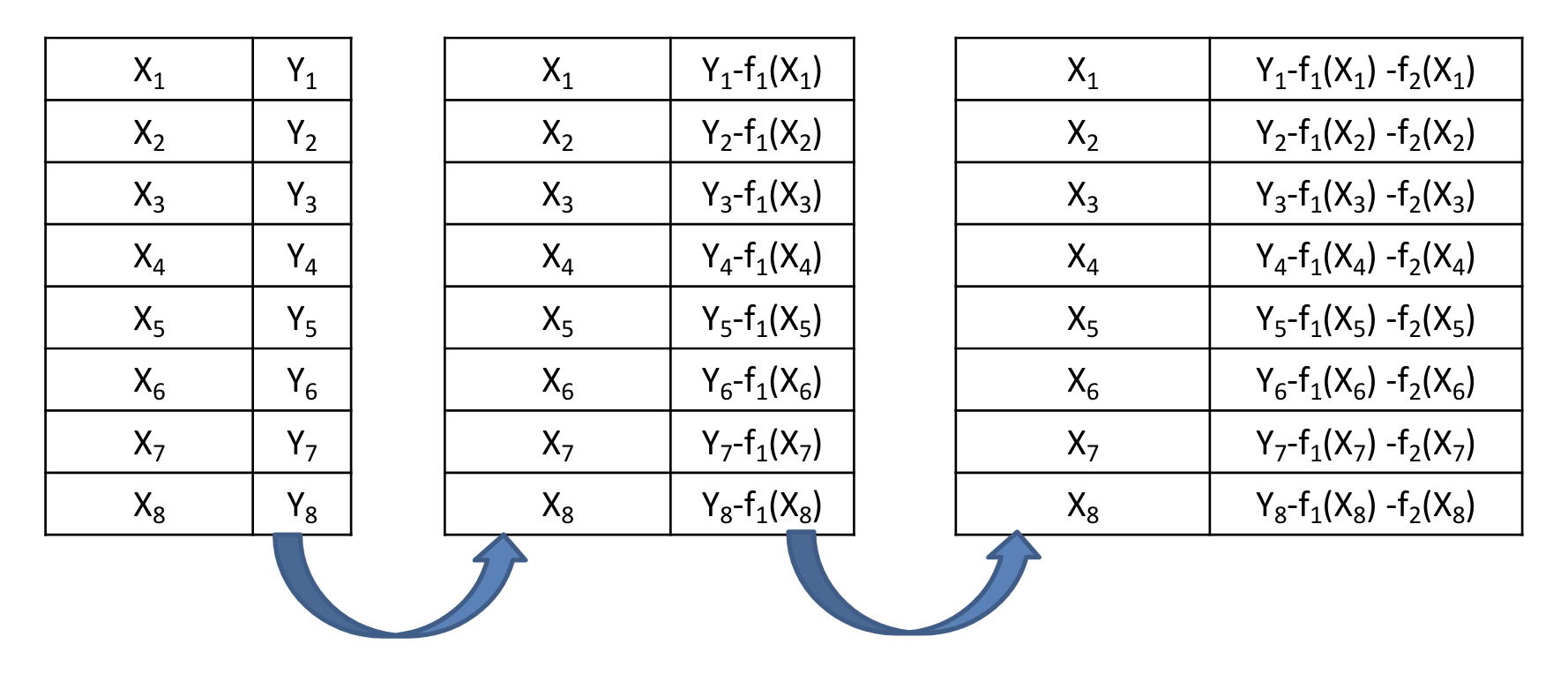
(2) Weak learner 추가를 통해 잔차(residual)를 예측
- 순차적으로 모델을 적용함
- 앞선 모델이 예측하지 못한 차이를 추가 모델에서 보상하는 구조

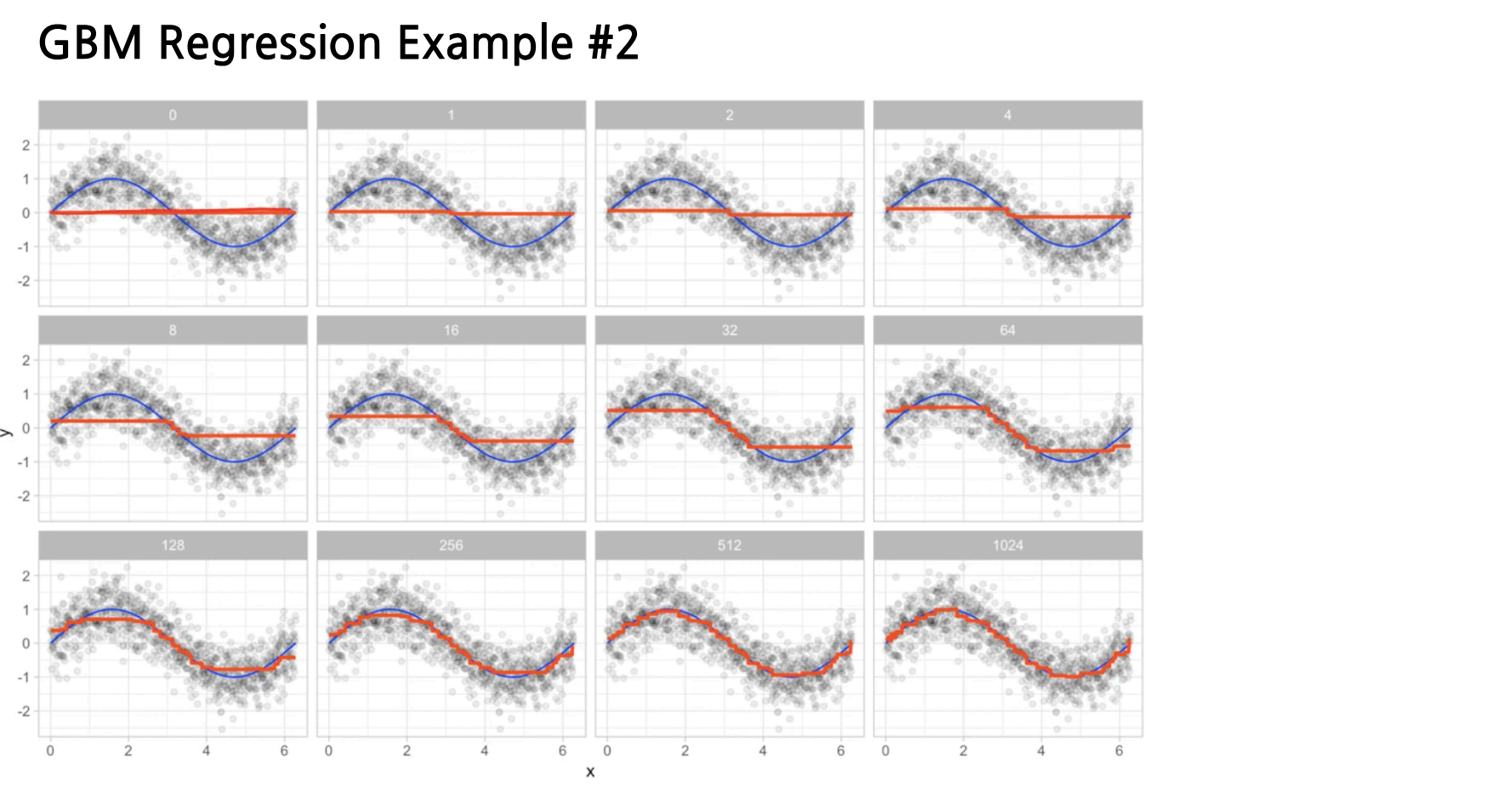
(3) 단점
과적합에 빠지기 쉬움
- 잔차를 모델링하다 보니, 노이즈까지 모델에 반영하는 문제가 생김
과적합 방지를 위한 해결책(Regularization)
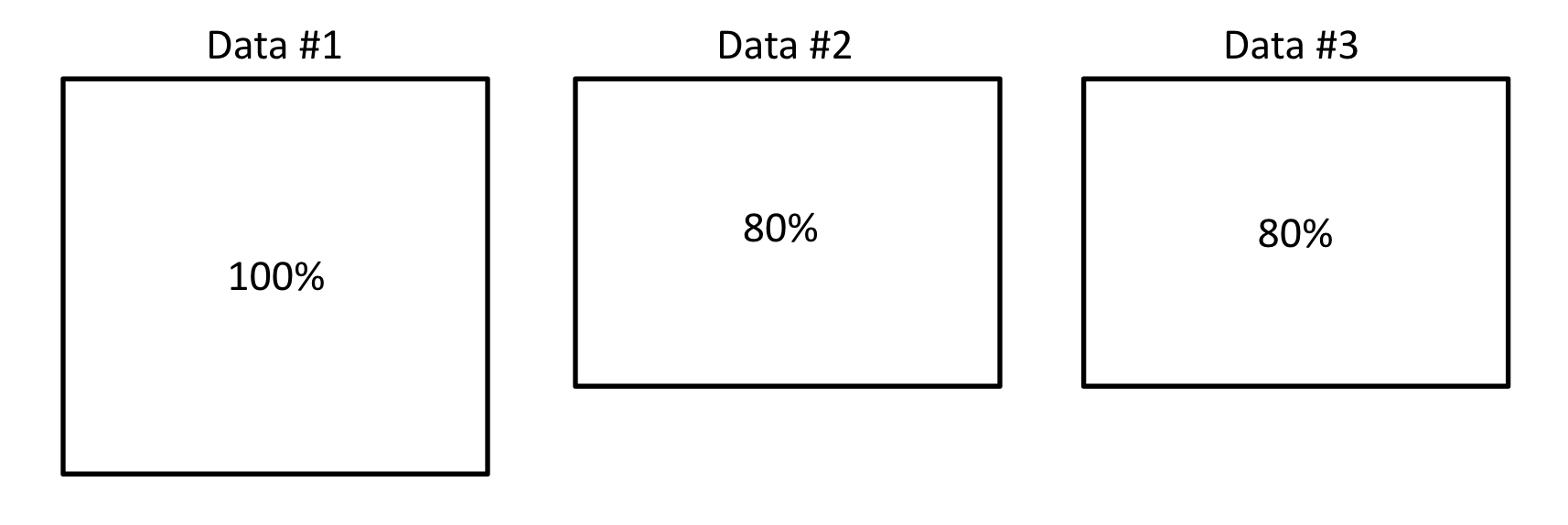
1) Subsampling
- 전체 데이터의 80%만 사용
- Replacement 여부 허용
2) Shrinkage
- 잔차 모델의 영향력을 조금씩 줄이는 방법
- 추가 weak learner의 영향력이 점점 줄음
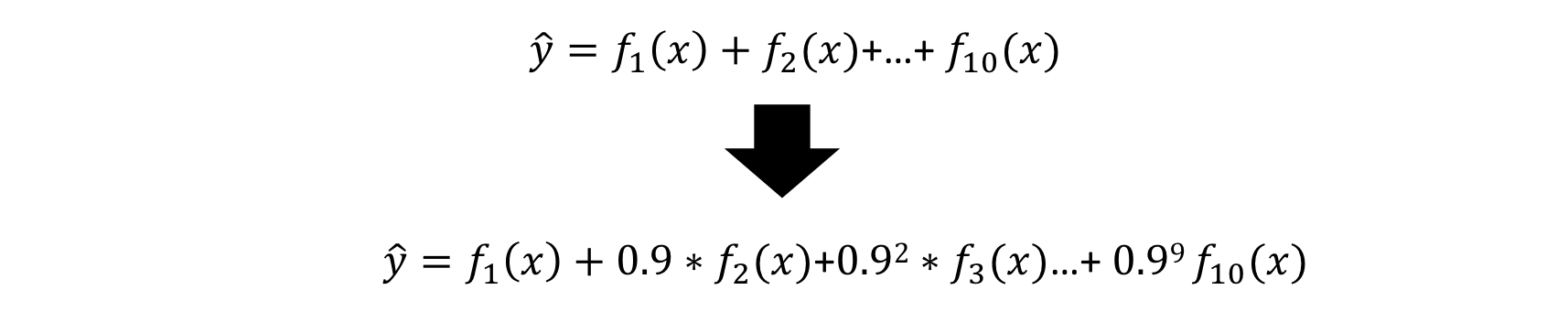
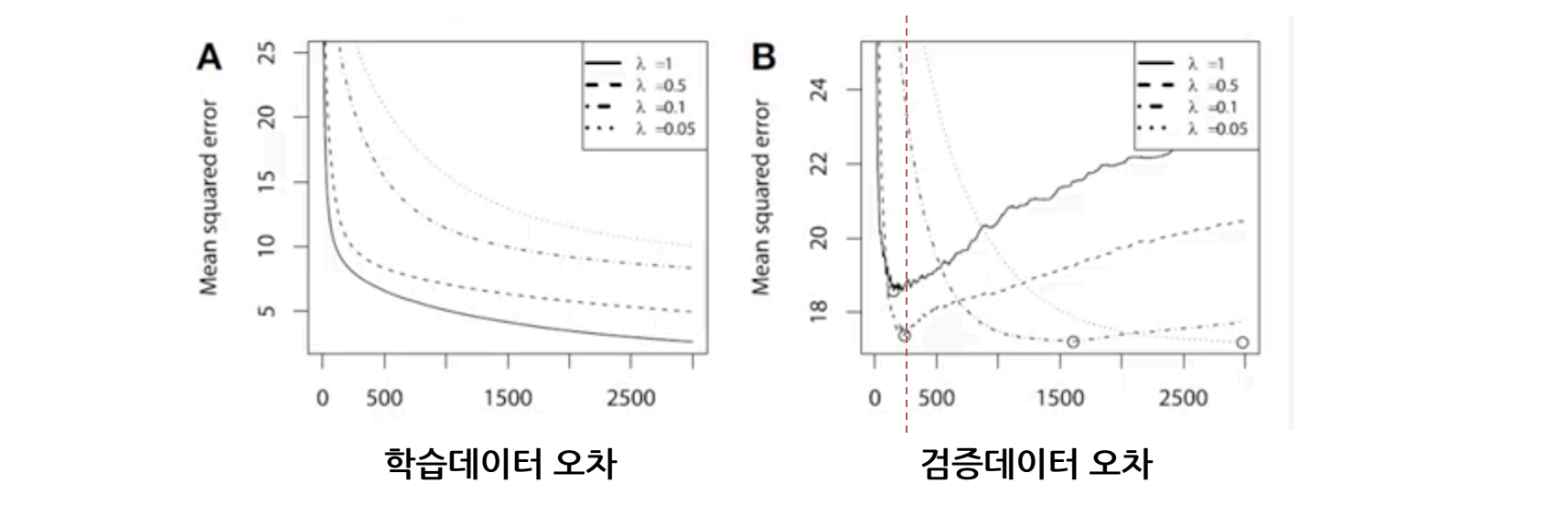
3) Early Stopping
- 검증 오차 허용을 통한 과적합 방지법
6. LightGBM
(1) 기존 GBM 동작 방식의 문제점
- 모든 데이터/모든 특성 변수에 대해서 알고리즘 수행 → 알고리즘 비효율적
- 입력 데이터를 연산하기 효율적으로 변경
(2) 기존 GBM 동작 방식의 해결방법
Gradient-based One-Side Sampling(GOSS)
- 모든 데이터를 사용하는 비효율성 해결책
- Gradients가 큰 데이터 일 수록 영향을 크게 미치는 데이터 임
- Small gradients는 랜덤 드랍, large gradient 만 포함

Exclusive Feature Bundling (EFB)
- 모든 특성 변수를 사용하는 비효율성 해결책
- 데이터가 Very Sparse할 경우(예: one-hot encoding), EFB 를 적용하여도 성능 하락이 발생하지 않음
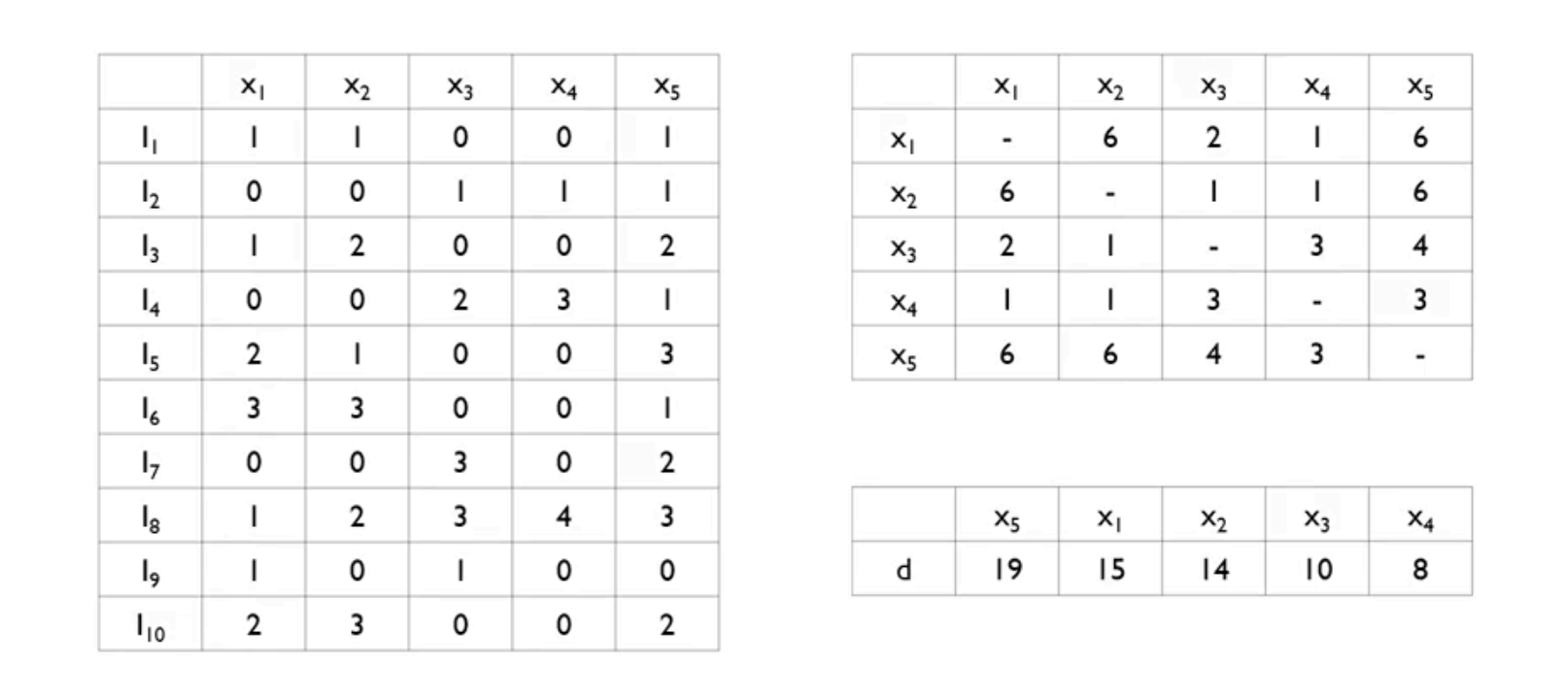
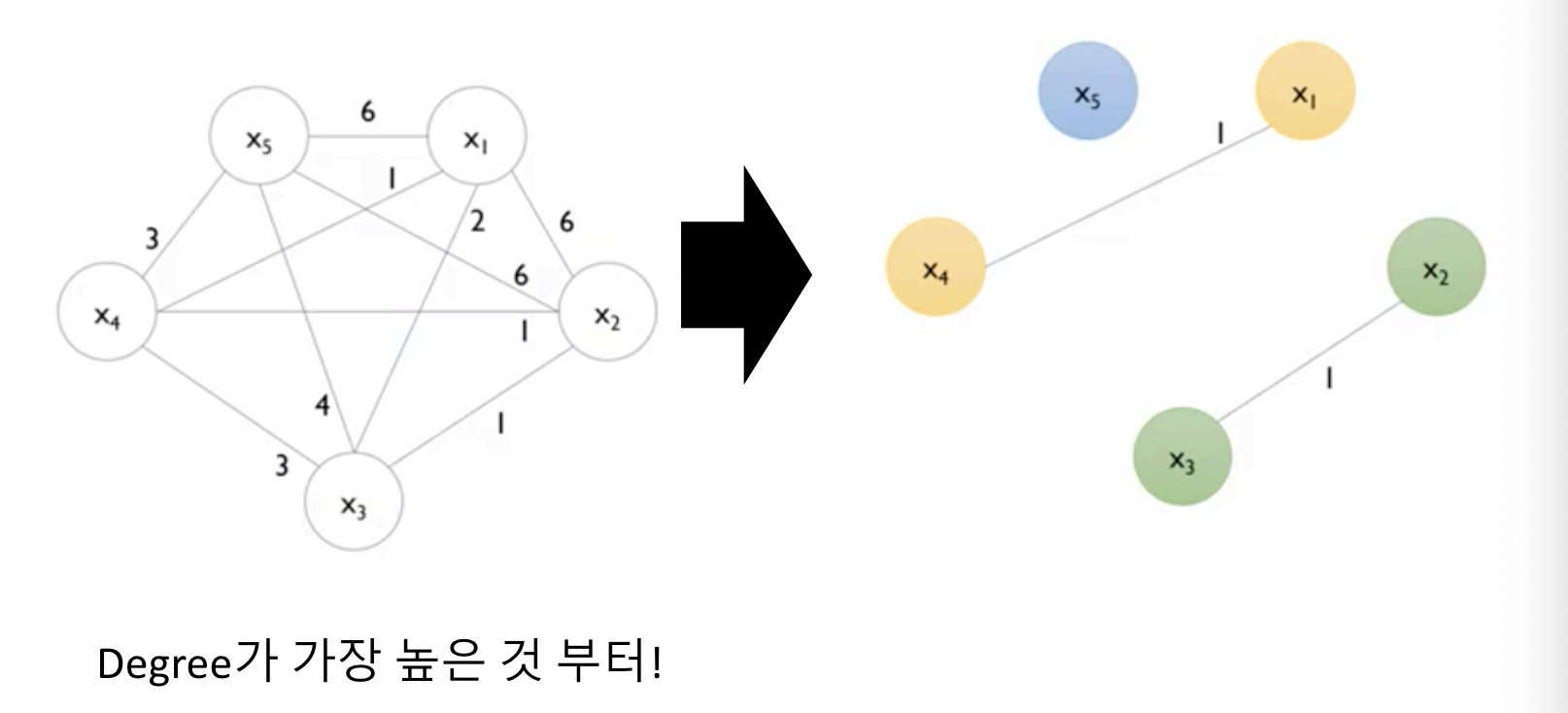
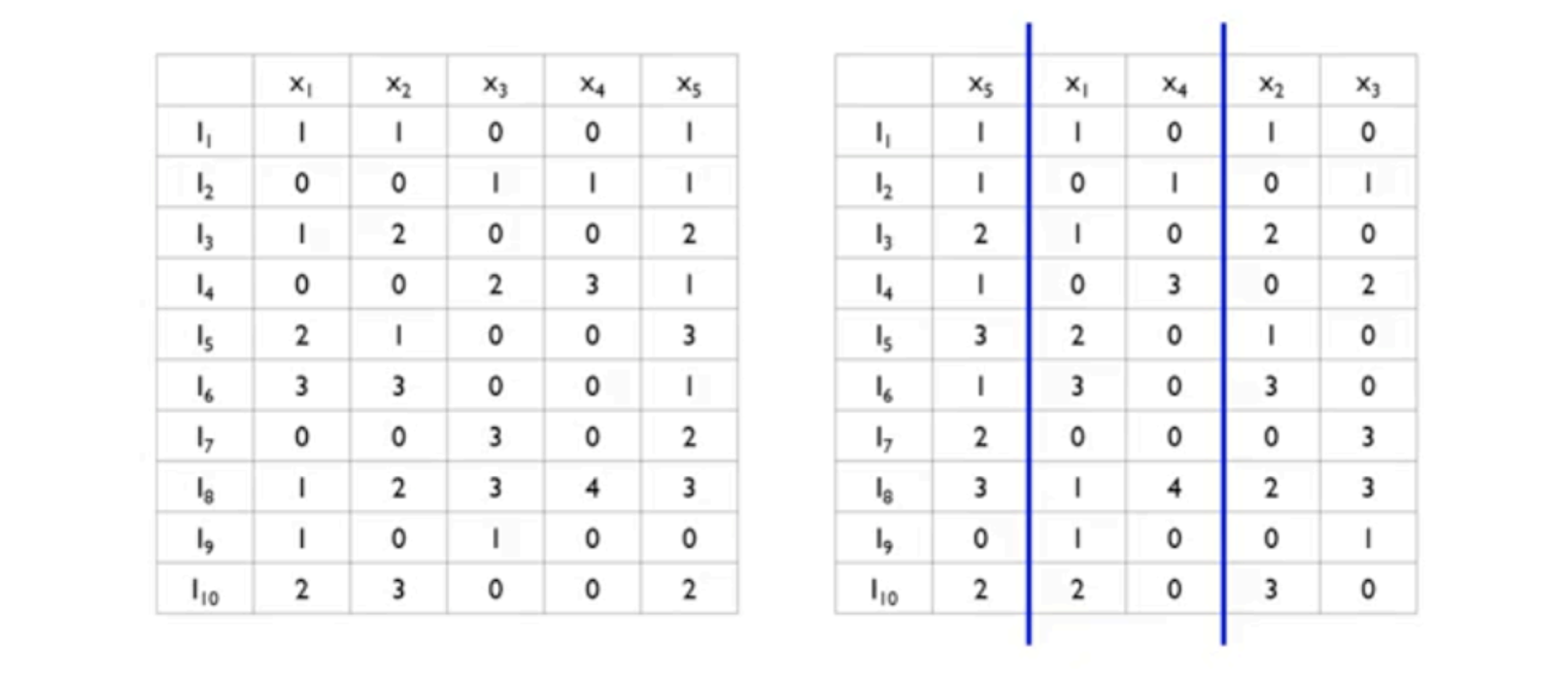
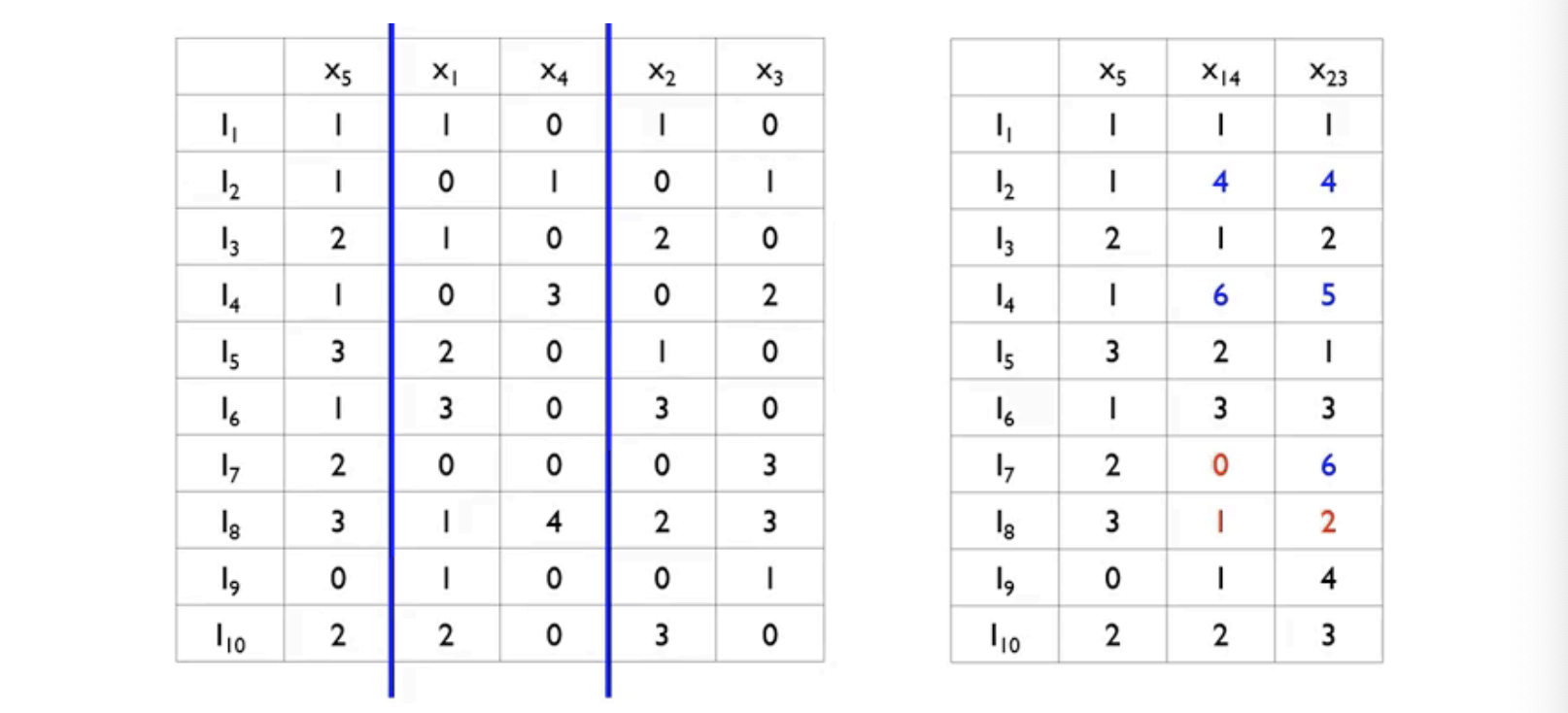
- 1)서로 거의 독립인 특성 변수(almost)를 묶어서 2)하나의 변수로 표현하는 방법
- 1) Greedy Bundling: 어떤 데이터를 하나로 묶을 것인가
- 2) Merge Exclusive Features: 하나로 묶어서 어떻게 표현할 것인가
'Study > Machine Learning' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) (1) (0) | 2024.06.09 |
|---|---|
| 앙상블(Ensemble) [센서데이터를 이용한 행동분류] (2) (0) | 2024.06.09 |
| SVM 다계층 분류 (4) (0) | 2024.06.09 |
| Nonlinear SVM : Kernel SVM (3) (0) | 2024.06.09 |
| Linear SVM : Soft Margin SVM (2) (0) | 2024.06.09 |



