
0. Overview
(1) Task
스마트폰에 장착된 자이로센서와 가속도 센서의 1D 센서 데이터(자이로, 가속도)를 사용하여 사람의 행동 유형을 분류 예측
- 1D 센서 데이터를 Feature 로 기술할 수 있습니다.
- 좋은 Feature를 만들수록 분류 성능이 향상됨을 알 수 있습니다.

스마트폰은 다양한 센서로 이뤄져있으며, 대표적으로는 가속도 센서와 자이로 센서가 있습니다. 가속도 센서(Accelerometer)는 X,Y,Z 축에 대한 가속도를 측정하는 센서이며, 스마트폰의 움직임을 알 수 있습니다. 다음으로는 자이로 센서(Gyroscope)는 물체의 회전속도를 측정하는 센서이며, 스마트폰의 기울임을 알 수 있습니다. 이외에도 다양한 센서가 존재하지만 해당 실습문제에서는 이 두가지 센서를 활용하게 됩니다.
(2) Dataset
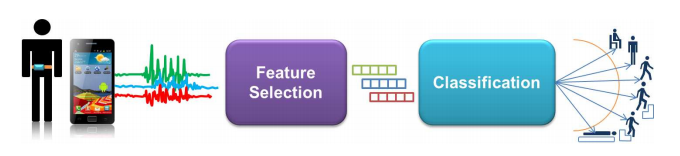
해당 실습문제에서는 2012년 발표된 논문인 'Human Activity Recognition on Smartphones using a Multiclass Hardware-Friendly Support Vector Machine'에서 공개한 데이터셋을 이용해 사람의 활동을 분류할 예정입니다. 해당 데이터셋에서 사람의 활동은 총 6가지로 나타내고 있습니다. 6가지 활동으로는 '1 WALKING, 2 WALKING_UPSTAIRS, 3 WALKING_DOWNSTAIRS,4 SITTING, 5 STANDING, 6 LAYING' 이 있습니다. 다시 설명하면 해당 데이터셋은 6가지의 사람의 행동을 스마트폰의 가속도 센서와 자이로 센서로 측정된 데이터로 분류하는 것을 목적으로 만들어졌습니다.
HAR 데이터셋 제작에는 총 30명의 피실험자가 참여하였으며, 데이터셋 제작에 사용된 휴대폰은 갤럭시 S2 입니다. 61번의 실험이 진행됐고, 피실험자는 앞서 언급한 6가지 동작을 스마트폰을 몸에 착용한 채로 수행하게 됩니다. 그리고 해당 데이터셋은 피실험자가 수행한 동작과 동작을 수행한 시작시간과 종료시간 등을 기록하였습니다. 센서 데이터는 50Hz를 주기로 수집됐습니다.
이번 실습문제에서는 61번의 실험에서 스마트폰으로 측정된 자이로 센서와 가속도 센서의 Raw 데이터를 가공해 Feature를 추출하고, 해당 Feature를 기반으로 총 6가지 행동을 분류문제로 해결할 예정입니다. 실습문제에서는 Raw 데이터가 사용되기 때문에 실제 Raw데이터를 잘 가공해 Feature를 추출해야하는 것이 핵심입니다. 해당 논문과 데이터셋이 촬영된 비디오 링크를 아래 추가하였으니 참고하시길 바랍니다.
1) 데이터 셋 소스
- UCI HAR 데이터 셋, DB Web
- Human Activity Recognition on Smartphones Using a Multiclass Hardware-Friendly Support Vector Machine, IWAAL 2012, DB Paper
2) 데이터 설명 (RawData)
- RawData captured at a frequency of 50Hz.
- RawData/acc_expXX_userYY.txt
- The raw triaxial acceleration signal for the experiment number XX and associated with the user number YY. Every row is one acceleration sample (three-axis) captured at a frequency of 50Hz.
- RawData/gyro_expXX_userYY.txt
- The raw triaxial angular speed signal for the experiment number XX and associated with the user number YY. Every row is one ang the user number YY. Every row is one angular velocity sample (three axes) captured at a frequency of 50Hz.
- RawData/labels.txt
- It includes all the activity labels available for the dataset (1 per row).
- Column 1: experiment number ID
- Column 2: user number ID
- Column 3: activity number ID
- Column 4: Label start point (in number of signal log samples (recorded at 50Hz))
- Column 5: Label end point (in number of signal log samples)
1. Raw Data 불러오기
Data Tree
+--RawData
| +--acc_exp01_user01.txt
| +--...(61개)
| +--gyro_exp01_user01.txt
| +--...(61개)
| +--label_train.txt
| +--label_test.txt
Raw_data_paths = sorted(glob("/kaggle/input/2024-ml-w12p1/RawData/*"))
Raw_acc_paths=Raw_data_paths[0:61]
Raw_gyro_paths=Raw_data_paths[61:122]
print (("RawData folder contains in total {:d} file ").format(len(Raw_data_paths)))
print (("The first {:d} are Acceleration files:").format(len(Raw_acc_paths)))
print (("The second {:d} are Gyroscope files:").format(len(Raw_gyro_paths)))
print ("The last file is a labels file")
print ("test labels file path is:",Raw_data_paths[122])
print ("train labels file path is:",Raw_data_paths[123])
print('raw_dic contains %d DataFrame' % len(raw_dic))
display(raw_dic['exp01_user01'].head(3))
2. Label 불러오기
Label 정보
train
experiment_number_ID : 실험 ID
user_number_ID : 유저 ID
activity_number_ID : 활동 ID
Label_start_point : Raw 데이터에서 행동이 시작하는 지점(시간)
Label_end_point : RAW 데이터에서 행동이 끝나는 지점(시간)
test
experiment_number_ID : 실험 ID
user_number_ID : 유저 ID
Label_start_point : Raw 데이터에서 행동이 시작하는 지점(시간)
Label_end_point : RAW 데이터에서 행동이 끝나는 지점(시간)
train_raw_labels_columns=['experiment_number_ID','user_number_ID','activity_number_ID','Label_start_point','Label_end_point']
test_raw_labels_columns=['experiment_number_ID','user_number_ID','Label_start_point','Label_end_point']
test_labels_path=Raw_data_paths[122]
train_labels_path=Raw_data_paths[123]
train_Labels_Data_Frame=import_labels_file(train_labels_path,train_raw_labels_columns)
test_Labels_Data_Frame=import_labels_file(test_labels_path,test_raw_labels_columns)print ("The first 3 rows of train_Labels_Data_Frame:" )
display(train_Labels_Data_Frame.head(3))
print(train_Labels_Data_Frame.shape)
display(test_Labels_Data_Frame.head(3))
print(test_Labels_Data_Frame.shape)
3. 데이터 전처리
Median Filter
from scipy.signal import medfilt
def median(signal):
array=np.array(signal)
med_filtered=sp.signal.medfilt(array, kernel_size=3)
return med_filteredButterworth Filter를 통한 성분분해
from scipy.fftpack import fft
from scipy.fftpack import fftfreq
from scipy.fftpack import ifft
import math
sampling_freq = 50
nyq=sampling_freq/float(2)
freq1 = 0.3
freq2 = 20
# Function name: components_selection_one_signal
# Inputs: t_signal:1D numpy array (time domain signal);
# Outputs: (total_component,t_DC_component , t_body_component, t_noise)
# type(1D array,1D array, 1D array)
# cases to discuss: if the t_signal is an acceleration signal then the t_DC_component is the gravity component [Grav_acc]
# if the t_signal is a gyro signal then the t_DC_component is not useful
# t_noise component is not useful
# if the t_signal is an acceleration signal then the t_body_component is the body's acceleration component [Body_acc]
# if the t_signal is a gyro signal then the t_body_component is the body's angular velocity component [Body_gyro]
def components_selection_one_signal(t_signal,freq1,freq2):
t_signal=np.array(t_signal)
t_signal_length=len(t_signal)
f_signal=fft(t_signal)
freqs=np.array(sp.fftpack.fftfreq(t_signal_length, d=1/float(sampling_freq)))# frequency values between [-25hz:+25hz]
# DC_component: f_signal values having freq between [-0.3 hz to 0 hz] and from [0 hz to 0.3hz]
# (-0.3 and 0.3 are included)
# noise components: f_signal values having freq between [-25 hz to 20 hz[ and from ] 20 hz to 25 hz]
# (-25 and 25 hz inculded 20hz and -20hz not included)
# selecting body_component: f_signal values having freq between [-20 hz to -0.3 hz] and from [0.3 hz to 20 hz]
# (-0.3 and 0.3 not included , -20hz and 20 hz included)
f_DC_signal=[] # DC_component in freq domain
f_body_signal=[] # body component in freq domain numpy.append(a, a[0])
f_noise_signal=[] # noise in freq domain
for i in range(len(freqs)):# iterate over all available frequencies
# selecting the frequency value
freq=freqs[i]
# selecting the f_signal value associated to freq
value= f_signal[i]
# Selecting DC_component values
if abs(freq)>0.3:# testing if freq is outside DC_component frequency ranges
f_DC_signal.append(float(0)) # add 0 to the list if it was the case (the value should not be added)
else: # if freq is inside DC_component frequency ranges
f_DC_signal.append(value) # add f_signal value to f_DC_signal list
# Selecting noise component values
if (abs(freq)<=20):# testing if freq is outside noise frequency ranges
f_noise_signal.append(float(0)) # # add 0 to f_noise_signal list if it was the case
else:# if freq is inside noise frequency ranges
f_noise_signal.append(value) # add f_signal value to f_noise_signal
# Selecting body_component values
if (abs(freq)<=0.3 or abs(freq)>20):# testing if freq is outside Body_component frequency ranges
f_body_signal.append(float(0))# add 0 to f_body_signal list
else:# if freq is inside Body_component frequency ranges
f_body_signal.append(value) # add f_signal value to f_body_signal list
################### Inverse the transformation of signals in freq domain ########################
# applying the inverse fft(ifft) to signals in freq domain and put them in float format
t_DC_component= ifft(np.array(f_DC_signal)).real
t_body_component= ifft(np.array(f_body_signal)).real
t_noise=ifft(np.array(f_noise_signal)).real
total_component=t_signal-t_noise # extracting the total component(filtered from noise)
# by substracting noise from t_signal (the original signal).
# return outputs mentioned earlier
return (total_component,t_DC_component,t_body_component,t_noise)
Feature Modeling
(1) 유클리드 Norm을 통한 가속도, 자이로 센서 크기(Magnitude) 계산
import math
def mag_3_signals(x,y,z): # Euclidian magnitude
return [math.sqrt((x[i]**2+y[i]**2+z[i]**2)) for i in range(len(x))](2) 미분을 통한 변화량(Jerk) 계산
dt=0.02 # dt=1/50=0.02s time duration between two rows
# Input: 1D array with lenght=N (N:unknown)
# Output: 1D array with lenght=N-1
def jerk_one_signal(signal):
return np.array([(signal[i+1]-signal[i])/dt for i in range(len(signal)-1)])time_sig_dic={}
raw_dic_keys=sorted(raw_dic.keys())
for key in tqdm.tqdm(raw_dic_keys):
raw_df=raw_dic[key]
time_sig_df=pd.DataFrame()
for column in raw_df.columns:
t_signal=np.array(raw_df[column])
med_filtred=median(t_signal)
if 'acc' in column:
_,grav_acc,body_acc,_=components_selection_one_signal(med_filtred,freq1,freq2)
body_acc_jerk=jerk_one_signal(body_acc)
time_sig_df['t_body_'+column]=body_acc[:-1]
time_sig_df['t_grav_'+column]= grav_acc[:-1]
time_sig_df['t_body_acc_jerk_'+column[-1]]=body_acc_jerk
elif 'gyro' in column:
_,_,body_gyro,_=components_selection_one_signal(med_filtred,freq1,freq2)
body_gyro_jerk=jerk_one_signal(body_gyro)
time_sig_df['t_body_gyro_'+column[-1]]=body_gyro[:-1]
time_sig_df['t_body_gyro_jerk_'+column[-1]]=body_gyro_jerk
new_columns_ordered=['t_body_acc_X','t_body_acc_Y','t_body_acc_Z',
't_grav_acc_X','t_grav_acc_Y','t_grav_acc_Z',
't_body_acc_jerk_X','t_body_acc_jerk_Y','t_body_acc_jerk_Z',
't_body_gyro_X','t_body_gyro_Y','t_body_gyro_Z',
't_body_gyro_jerk_X','t_body_gyro_jerk_Y','t_body_gyro_jerk_Z']
ordered_time_sig_df=pd.DataFrame()
for col in new_columns_ordered:
ordered_time_sig_df[col]=time_sig_df[col]
for i in range(0,15,3):
mag_col_name=new_columns_ordered[i][:-1]+'mag'
col0=np.array(ordered_time_sig_df[new_columns_ordered[i]]) # copy X_component
col1=ordered_time_sig_df[new_columns_ordered[i+1]] # copy Y_component
col2=ordered_time_sig_df[new_columns_ordered[i+2]] # copy Z_component
mag_signal=mag_3_signals(col0,col1,col2)
ordered_time_sig_df[mag_col_name]=mag_signal
time_sig_dic[key]=ordered_time_sig_dfdisplay(time_sig_dic['exp01_user01'].shape)
display(time_sig_dic['exp01_user01'].describe())
time_sig_dic['exp01_user01'].head(3)
데이터 샘플링
2.56초를 기준으로 Raw 데이터 샘플링
50%는 오버랩 하여 샘플링을 수행def Windowing_type(time_sig_dic,Labels_Data_Frame):
columns=time_sig_dic['exp01_user01'].columns
window_ID=0
time_dictionary_window={}
BA_array=np.array(Labels_Data_Frame)
for line in tqdm.tqdm(BA_array):
file_key= 'exp' + normalize2(int(line[0])) + '_user' + normalize2(int(line[1]))
if line.shape[0] == 5 :
act_ID=line[2]
start_point=line[3]
end_point = line[4]
else :
act_ID='None'
start_point = line[2]
end_point = line[3]
for cursor in range(start_point,end_point-127,64):
end_point=cursor+128
data=np.array(time_sig_dic[file_key].iloc[cursor:end_point])
window=pd.DataFrame(data=data,columns=columns)
key='t_W'+normalize5(window_ID)+'_'+file_key+'_act'+normalize2(act_ID)
time_dictionary_window[key]=window
window_ID=window_ID+1
return time_dictionary_window train_time_dictionary_window = Windowing_type(time_sig_dic,train_Labels_Data_Frame)
test_time_dictionary_window = Windowing_type(time_sig_dic,test_Labels_Data_Frame)train_window = train_time_dictionary_window[sorted(train_time_dictionary_window.keys())[0]]
train_window.head()print("시간 도메인 Train 데이터 수 : {}".format(len(train_time_dictionary_window)))
print("시간 도메인 Test 데이터 수 : {}".format(len(test_time_dictionary_window)))
print("윈도우 크기(2.56s => 128개) : {}".format(len(train_window)))(3) FFT(Fast Fourier Transform)을 통한 시간 도메인 → 주파수 도메인 변환
from scipy import fftpack
from numpy.fft import *
def fast_fourier_transform_one_signal(t_signal):
complex_f_signal= fftpack.fft(t_signal)
amplitude_f_signal=np.abs(complex_f_signal)
return amplitude_f_signal
def fast_fourier_transform(t_window):
f_window=pd.DataFrame()
for column in t_window.columns:
if 'grav' not in column:
t_signal=np.array(t_window[column])
f_signal= np.apply_along_axis(fast_fourier_transform_one_signal,0,t_signal)
f_window["f_"+column[2:]]=f_signal
return f_windowtrain_frequent_dictionary_window = {'f'+key[1:] : train_t_df.pipe(fast_fourier_transform) for key, train_t_df in tqdm.tqdm(train_time_dictionary_window.items())}
test_frequent_dictionary_window = {'f'+key[1:] : test_t_df.pipe(fast_fourier_transform) for key, test_t_df in tqdm.tqdm(test_time_dictionary_window.items())}print("주파수 도메인 Train 데이터 수 : {}".format(len(train_frequent_dictionary_window)))
print("주파수 도메인 Test 데이터 수 : {}".format(len(test_frequent_dictionary_window)))
print("피처의 갯수 : {}".format(len(train_window)))(4) Feature Extract
# -------------------------------------
# [Empty Module #1] Feature Engineering
# -------------------------------------
# -------------------------------------
# Feature Engineering
# -------------------------------------
# 목적: 제공된 36개의 시퀀스 도메인 데이터를 기반으로 유의미한 피처를 추출한다.
# 입력인자: 시간(time) 도메인 Feature 20개 , 주파수(frequency) 도메인 Feature 16개
# 출력인자: 분류모델 학습을 위한 Feature
# -------------------------------------
# ------------------------------------------------------------
# 논문에서 제안하는 Feature Engineering 방법을 따라 feature 추출
# ------------------------------------------------------------
#
# mean(): Mean value
# std(): Standard deviation
# mad(): Median absolute deviation
# max(): Largest value in array
# min(): Smallest value in array
# sma(): Signal magnitude area
# energy(): Energy measure. Sum of the squares divided by the number of values.
# iqr(): Interquartile range
# entropy(): Signal entropy
# arCoeff(): Autorregresion coefficients with Burg order equal to 4
# correlation(): correlation coefficient between two signals
# maxInds(): index of the frequency component with largest magnitude
# meanFreq(): Weighted average of the frequency components to obtain a mean frequency
# skewness(): skewness of the frequency domain signal
# kurtosis(): kurtosis of the frequency domain signal
# bandsEnergy(): Energy of a frequency interval within the 64 bins of the FFT of each window.
# angle(): Angle between to vectors.
import sys
# Time domain Feature Extract function
from Feature_engineering import mean_axial,std_axial,mad_axial,max_axial,min_axial, t_sma_axial, t_energy_axial,IQR_axial,entropy_axial, t_arburg_axial, t_corr_axial
from Feature_engineering import mean_mag,std_mag,mad_mag,max_mag,min_mag,t_sma_mag,t_energy_mag,IQR_mag,entropy_mag,t_arburg_mag
# Frequency domain Feature Extract function
from Feature_engineering import f_sma_axial,f_energy_axial,f_max_Inds_axial,f_mean_Freq_axial,f_skewness_and_kurtosis_axial,f_all_bands_energy_axial
from Feature_engineering import f_sma_mag,f_energy_mag,f_max_Inds_mag,f_mean_Freq_mag,f_skewness_mag,f_kurtosis_mag
# Additional Feature Extract function
from Feature_engineering import angle_features
def feature_extractor(time_dictionary,freq_dictionary, condition='train') :
if condition is 'train' :
total_data = []
total_label = []
elif condition is 'test' :
total_data = []
for i in tqdm.tqdm(range(len(time_dictionary))) :
time_key = sorted(time_dictionary.keys())[i]
freq_key = sorted(freq_dictionary.keys())[i]
time_window = time_dictionary[time_key]
freq_window = freq_dictionary[freq_key]
if condition is 'train' :
window_user_id= int(time_key[-8:-6]) # extract the user id from window's key
window_activity_id=int(time_key[-2:]) # extract the activity id from the windows key
elif condition is 'test' :
window_user_id= int(time_key[-10:-8]) # extract the user id from window's key
window_activity_id= 0
else :
print("Error")
sys.exit()
break;
##################################################################################
# Time domain - Feature extractor - Part 1. axial(X,Y,Z) Features
#[0,1,2] : 't_body_acc_X', 't_body_acc_Y', 't_body_acc_Z'
#[3,4,5] : 't_grav_acc_X','t_grav_acc_Y', 't_grav_acc_Z'
#[6,7,8] : 't_body_acc_jerk_X','t_body_acc_jerk_Y', 't_body_acc_jerk_Z'
#[9,10,11] : 't_body_gyro_X','t_body_gyro_Y', 't_body_gyro_Z'
#[12,13,14] : 't_body_gyro_jerk_X', 't_body_gyro_jerk_Y', 't_body_gyro_jerk_Z'
axial_columns = time_window.columns[0:15]
axial_df = time_window[axial_columns] # X,Y,Z
time_axial_features = []
for col in range(0,15,3) :
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# 아래 time_3axial_vector 나타난 Feature를 계산하여야 한다.
# 각각을 계산하기위한 함수는 'Feature_engineering.py'에 내제되어 있다.
# ------------------------------------------------------------
# 40 value per each 3-axial signals
time_3axial_vector= mean_vector + std_vector + mad_vector + max_vector + min_vector + [sma_value] + energy_vector + IQR_vector + entropy_vector + AR_vector + corr_vector
# append these features to the global list of features
time_axial_features= time_axial_features+ time_3axial_vector
##################################################################################
# Time domain - Feature extractor - Part 2. Magnitude Features
#[15]'t_body_acc_mag'
#[16]'t_grav_acc_mag'
#[17]'t_body_acc_jerk_mag'
#[18]'t_body_gyro_mag'
#[19]'t_body_gyro_jerk_mag'
mag_columns = time_window.columns[15:]
mag_columns = time_window[mag_columns]
time_mag_features = []
for col in mag_columns :
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# 아래 col_mag_values 나타난 Feature를 계산하여야 한다.
# 각각을 계산하기위한 함수는 'Feature_engineering.py'에 내제되어 있다.
# ------------------------------------------------------------
# 13 value per each t_mag_column
col_mag_values = [mean_value, std_value, mad_value, max_value, min_value, sma_value,
energy_value,IQR_value, entropy_value]+ AR_vector
# col_mag_values will be added to the global list
time_mag_features= time_mag_features+ col_mag_values
##################################################################################
# Frequency domain - Feature extractor - Part 1. axial(X,Y,Z) Features
#[0,1,2] : 'f_body_acc_X', 'f_body_acc_Y', 'f_body_acc_Z'
#[3,4,5] : 'f_body_acc_jerk_X','f_body_acc_jerk_Y', 'f_body_acc_jerk_Z'
#[6,7,8] : 'f_body_gyro_X','f_body_gyro_Y', 'f_body_gyro_Z'
#[9,10,11] : 'f_body_gyro_jerk_X','f_body_gyro_jerk_Y', 'f_body_gyro_jerk_Z'
axial_columns=freq_window.columns[0:12]
axial_df=freq_window[axial_columns]
freq_axial_features=[]
for col in range(0,12,3) :
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# 아래 freq_3axial_features 나타난 Feature를 계산하여야 한다.
# 각각을 계산하기위한 함수는 'Feature_engineering.py'에 내제되어 있다.
# ------------------------------------------------------------
freq_3axial_features = mean_vector +std_vector + mad_vector + max_vector + min_vector + [sma_value] + energy_vector + IQR_vector + entropy_vector + max_inds_vector + mean_Freq_vector + skewness_and_kurtosis_vector + bands_energy_vector
freq_axial_features = freq_axial_features+ freq_3axial_features
##################################################################################
# Frequency domain - Feature extractor - Part 2. Magnitude Features
#[12]'f_body_acc_mag'
#[13]'f_body_acc_jerk_mag'
#[14]'f_body_gyro_mag'
#[15]'f_body_gyro_jerk_mag'
mag_columns=freq_window.columns[12:]
mag_columns=freq_window[mag_columns]
freq_mag_features = []
for col in mag_columns:
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# 아래 col_mag_values에 나타난 Feature를 계산하여야 한다.
# 각각을 계산하기위한 함수는 'Feature_engineering.py'에 내제되어 있다.
# ------------------------------------------------------------
# 13 value per each t_mag_column
col_mag_values = [mean_value, std_value, mad_value, max_value,
min_value, sma_value, energy_value,IQR_value,
entropy_value, max_Inds_value, mean_Freq_value,
skewness_value, kurtosis_value ]
freq_mag_features= freq_mag_features+ col_mag_values
##################################################################################
# Time domain - Feature extractor - Part 3. Additional Features
additional_features = angle_features(time_window)
##################################################################################
total_features = time_axial_features + time_mag_features + freq_axial_features + freq_mag_features + additional_features
total_data.append(total_features)
if condition is 'train' :
total_label.append(window_activity_id)
total_data = np.array(total_data)
if condition is 'train' :
total_label = np.array(total_label)
if condition is 'train' :
return total_data, total_label
elif condition is 'test' :
return total_datatrain_data, train_label = feature_extractor(train_time_dictionary_window,train_frequent_dictionary_window,condition='train')
test_data = feature_extractor(test_time_dictionary_window,test_frequent_dictionary_window,condition='test')
4. 데이터 정규화
# -------------------------------------
# [Empty Module #2] Data Normalization
# -------------------------------------
# -------------------------------------
# Data Normalization
# -------------------------------------
# 목적: 앞서 구축한 train,test 셋에 대한 Feature를 정규화한다.
# 입력인자: train 셋에서 추출된 Feature, test 셋에서 추출된 Feature
# 출력인자: 정규화된 Feature Vector
# -------------------------------------
from sklearn.preprocessing import MinMaxScaler
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# sklearn에서 제공하는 MinMaxScaler를 사용해 데이터 정규화를 진행한다.
# (MinMaxScaler가 아닌 다른 정규화를 사용할 수 있다.)
# ------------------------------------------------------------
std = MinMaxScaler()
train_data = std.fit_transform(train_data)
test_data = std.transform(test_data)
5. 분류 모델 학습 및 평가
# -------------------------------------
# [Empty Module #3] RandomForest를 이용한 분류
# -------------------------------------
# -------------------------------------
# RandomForest를 이용한 분류
# -------------------------------------
# 목적: 앞서 완성한 train/test Feature를 RandomForest를 이용해 분류한다.
# 추가 안내 : 리더보드의 베이스라인은 random_state를 42로 하였다.
# 입력인자: Feature vector(train/test)
# 출력인자: 분류결과
# -------------------------------------
from sklearn.ensemble import RandomForestClassifier
# ------------------------------------------------------------
# 구현 가이드라인
# ------------------------------------------------------------
# sklearn에서 제공하는 RandomForest를 사용해 분류를 진행한다.
# (RandomForest를가 아닌 다른 분류모델을 사용할 수 있다.)
# ------------------------------------------------------------
clf = RandomForestClassifier()
clf.fit(train_data, train_label)
preds = clf.predict(test_data)
'Computer Science > Machine Learning' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) : PCA (2) (0) | 2024.06.09 |
|---|---|
| 차원 축소(Dimension Reduction) (1) (0) | 2024.06.09 |
| 앙상블(Ensemble) (1) (2) | 2024.06.09 |
| SVM 다계층 분류 (4) (0) | 2024.06.09 |
| Nonlinear SVM : Kernel SVM (3) (0) | 2024.06.09 |



