
1. 주성분 분석(PCA)
(1) 주성분 분석의 목적
차원을 줄이는 비지도 학습 방법 중 한가지
사영 후 원 데이터의 분산(variance)을 최대한 보존할 수 있는 기저를 찾아 차원을 줄이는 방법
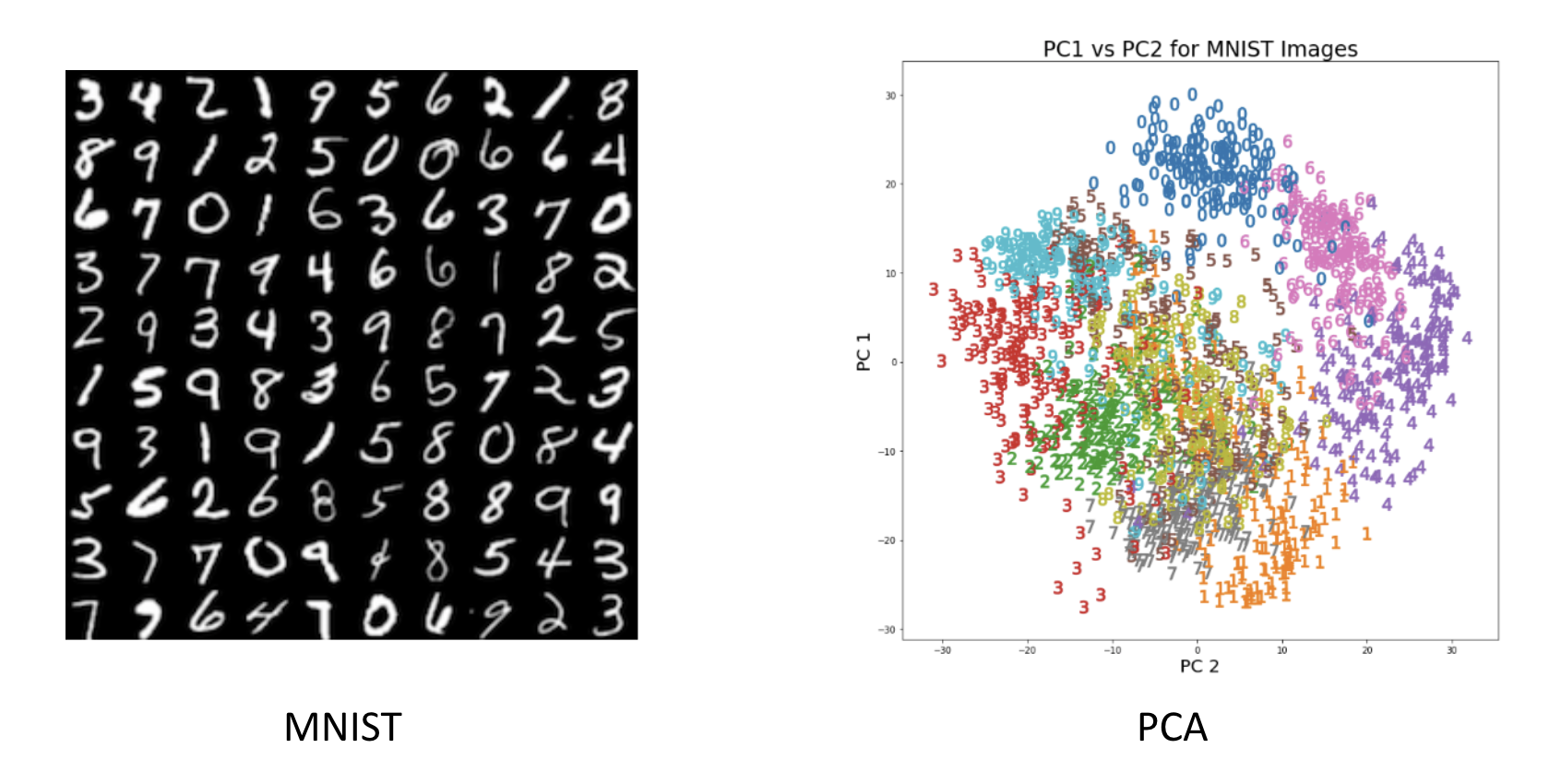
(2) MNIST의 예시
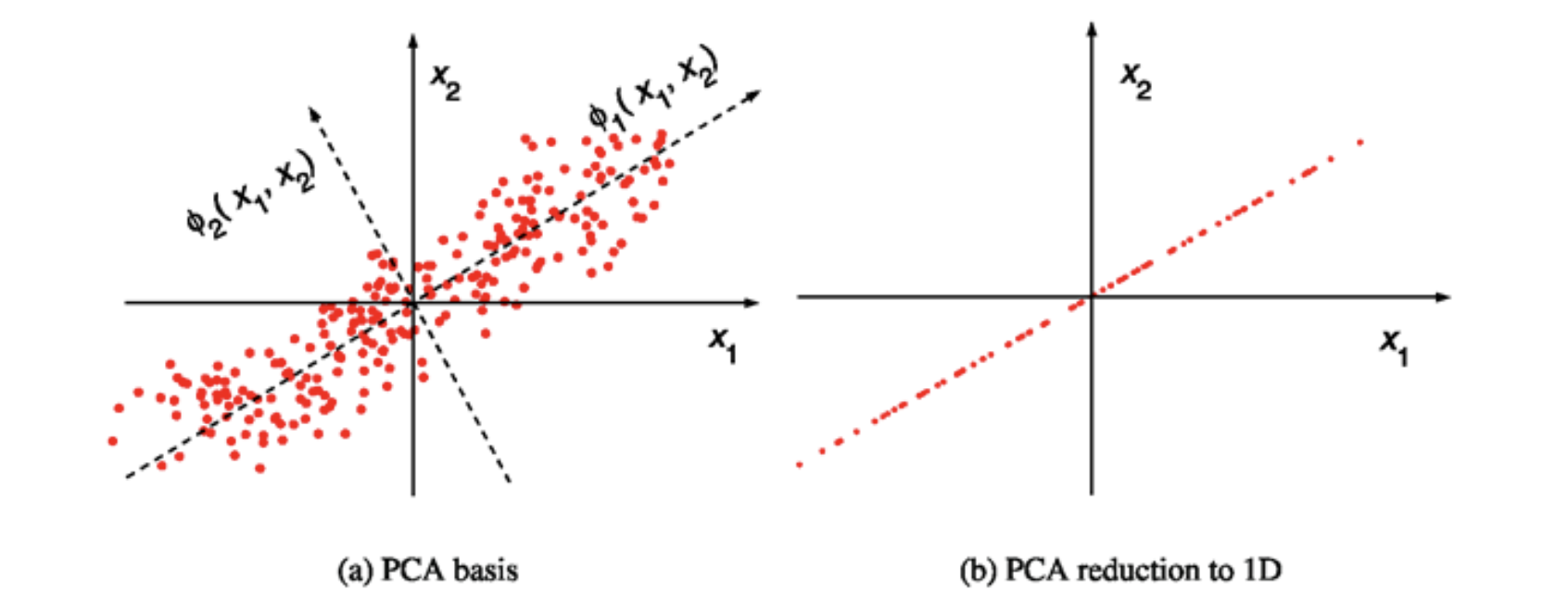
(3) 주성분 분석
데이터를 사영(projection)시킬 경우 송실괴는 정보의 양이 적은 쪽의 기저(축)를 선택
아래 예시의 경우 왼쪽 기저(축)가 오른쪽 기저보다 원데이터의 분산을 최대로 유지하므로 왼쪽의 기저 축을 주성분을 선택하는 것이 좋음
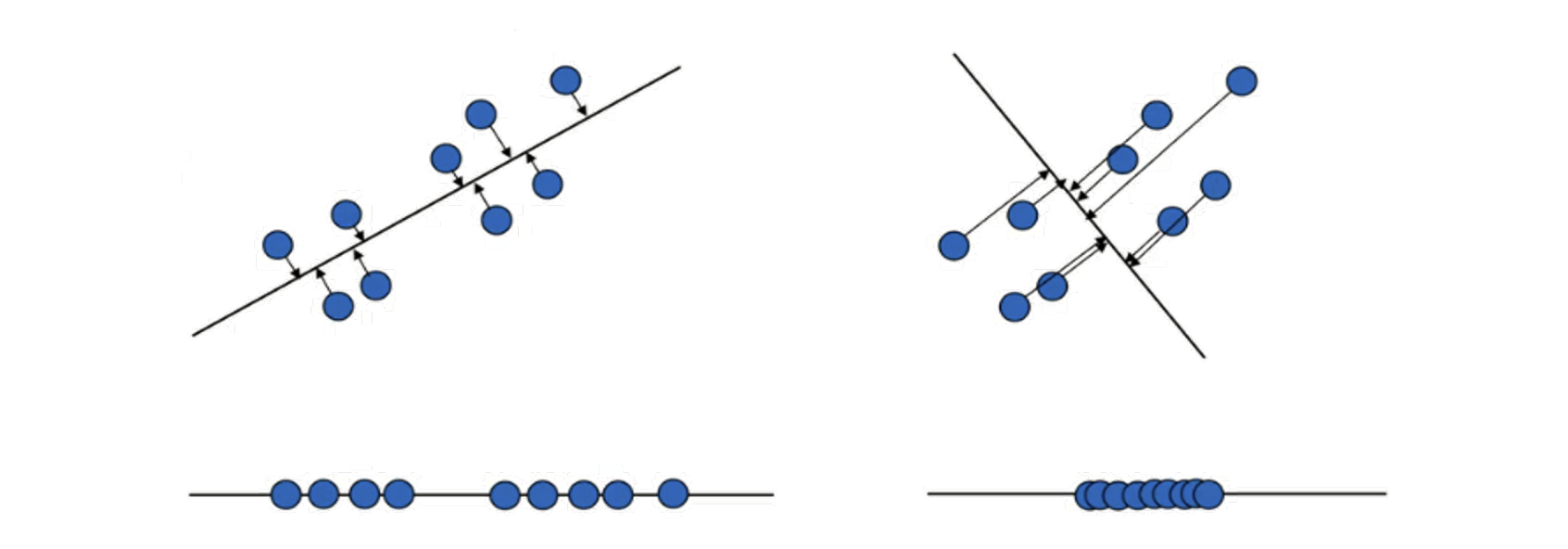
2. 주성분 분석(PCA): 수리적 배경
(1) 주성분 분석: 선형 결합
데이터(X) 사영 변환 후(Z)에도 분산이 보존하는 기저(a)을 찾는 것

(2) 공분산(Covariance) : 변수의 상관 정도
X : 입력 데이터 (n개의 데이터, d개의 변수)

(3) 데이터셋의 전체 분산 (Total variance)

(4) 사영 (Projection)

(5) 고유값(eigenvalue)과 고유벡터(eigenvector)
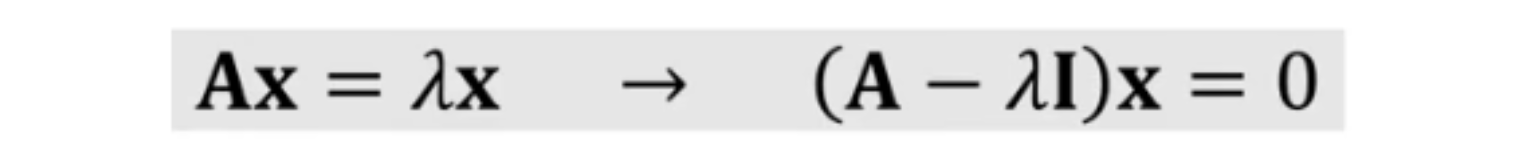
- 행렬A가 Non-singular 하다면, d개의 고유값과 고유벡터가 존재함
- 고유벡터는 서로 직교함(orthogonal)
- $tr(A)=\lambda_1+\lambda_2+\cdot\cdot\cdot +\lambda_d$
(6) 벡터에 행렬을 곱하는 것은 선형 변환의 의미를 가짐
- 고유벡터는 변환에 의해 방향 변화가 발생하지 않음
- 고유벡터의 크기 변화는 $\lambda$만큼

3. 주성분 분석 알고리즘
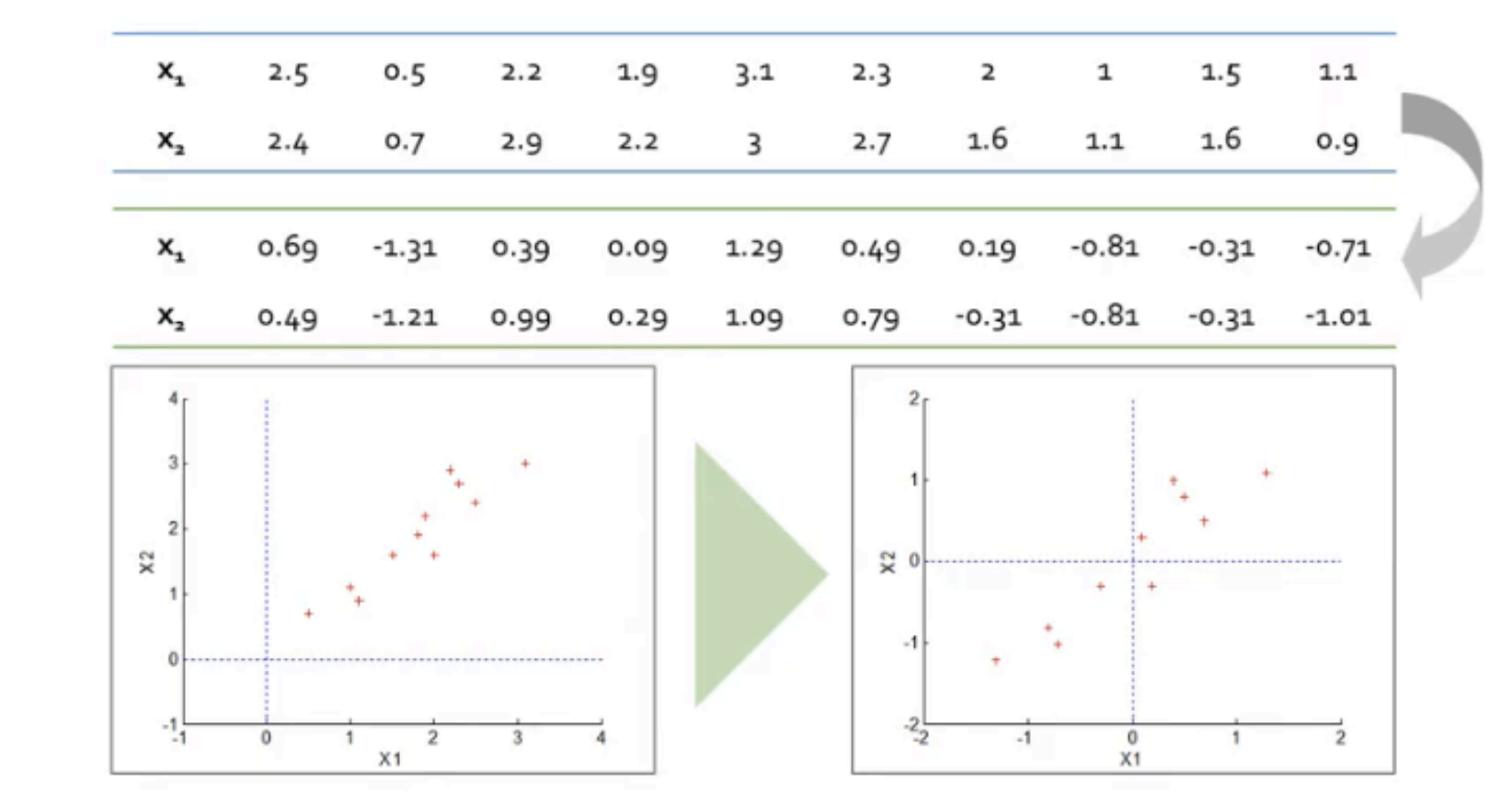
Step 1 : 데이터 센터링 (Data centering)
데이터 평균을 0으로 변경
Step 2 : 최적화 문제 정의
데이터 X를 기저 벡터 W에 사영(projection)하면, 사용 후 분산은 다음과 같음
- S는 X의 covariance matrix

PCA의 목적은 사영 이후 분산 V를 최대화하는 것
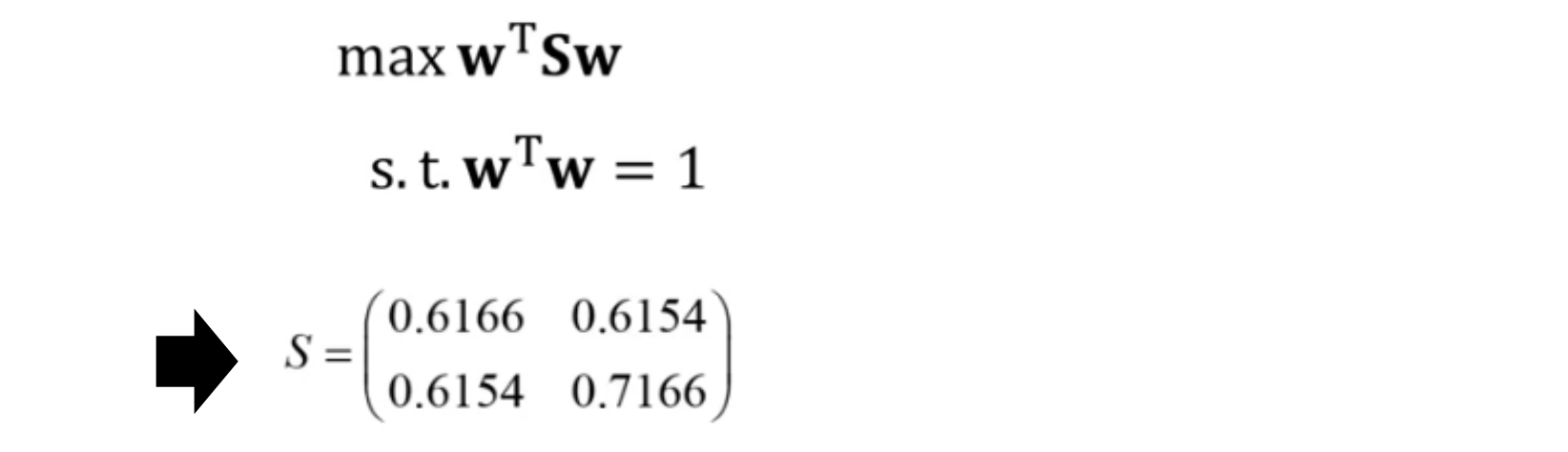
Step 3 : 최적화 문제 솔루션
라그랑지 멀티플레이어(Lagrangian multiplier) 적용
- S는 X의 covariance matrix
- W는 S의 eigen vector
- $\lambda$는 S의 eigen value

Step 4 : 주축 정렬
- S는 X의 covariance matrix
- W는 S의 eigen vector
- $\lambda$는 S의 eigen value
- Eigenvalue 에 해당되는 eigenvectors를 순서대로 정렬
- $W_1$은 Eigen vector이고 $\lamdba_1$은 대응되는 eigen value
- (아래 식의 유도에 의하면) $W_1$ 에 사영된 데이터의 분산은 $\lambda_1$

- (첫번째 주성분으로 설명가능한 데이터의 비율) $= \frac{\lambda_2}{\lambda_1 + \lambda_2} = \frac{0.0491}{1.2840 + 0.0491} = 0.96$
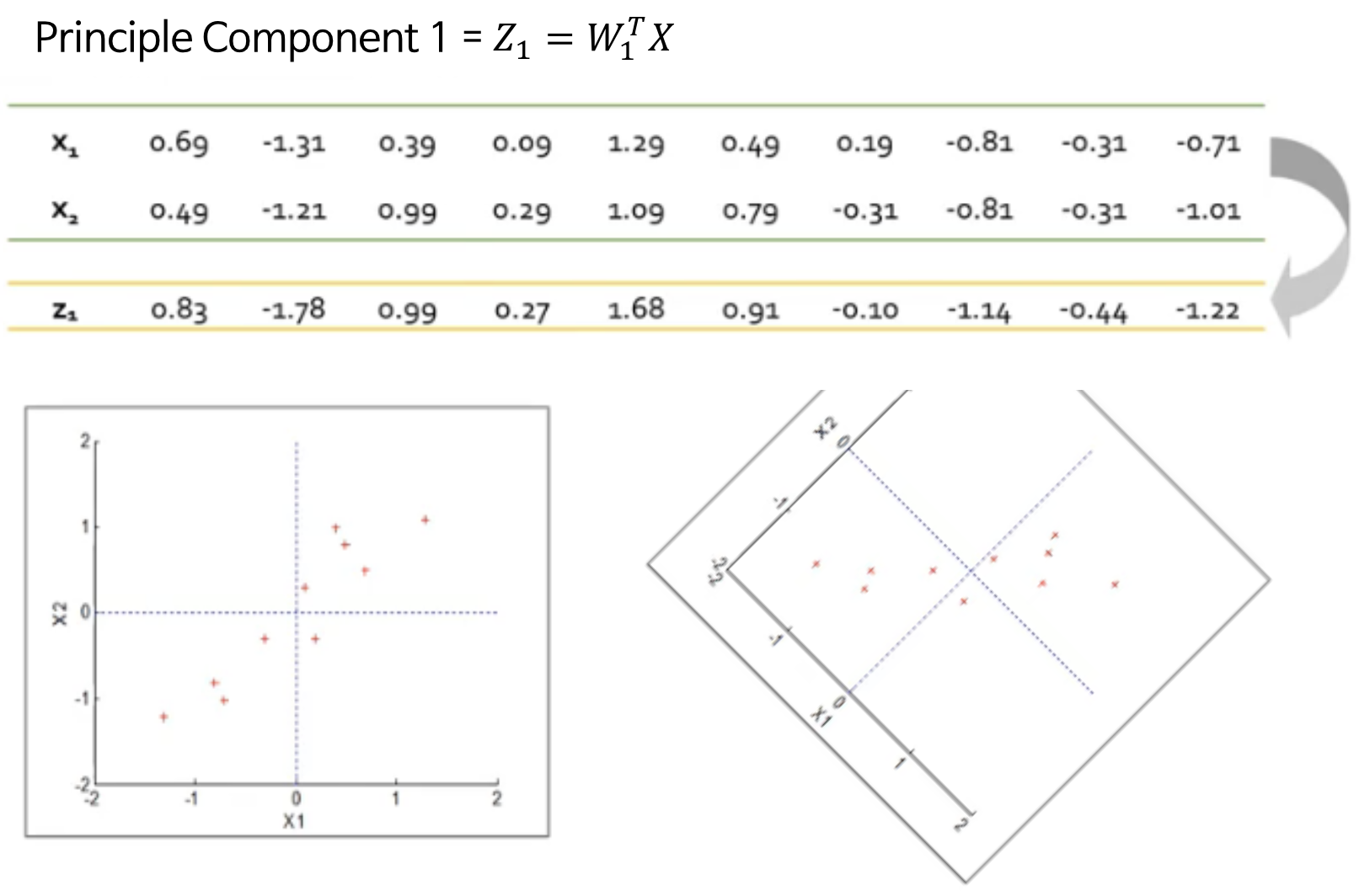
Step 5 : PCA로 변환된 데이터
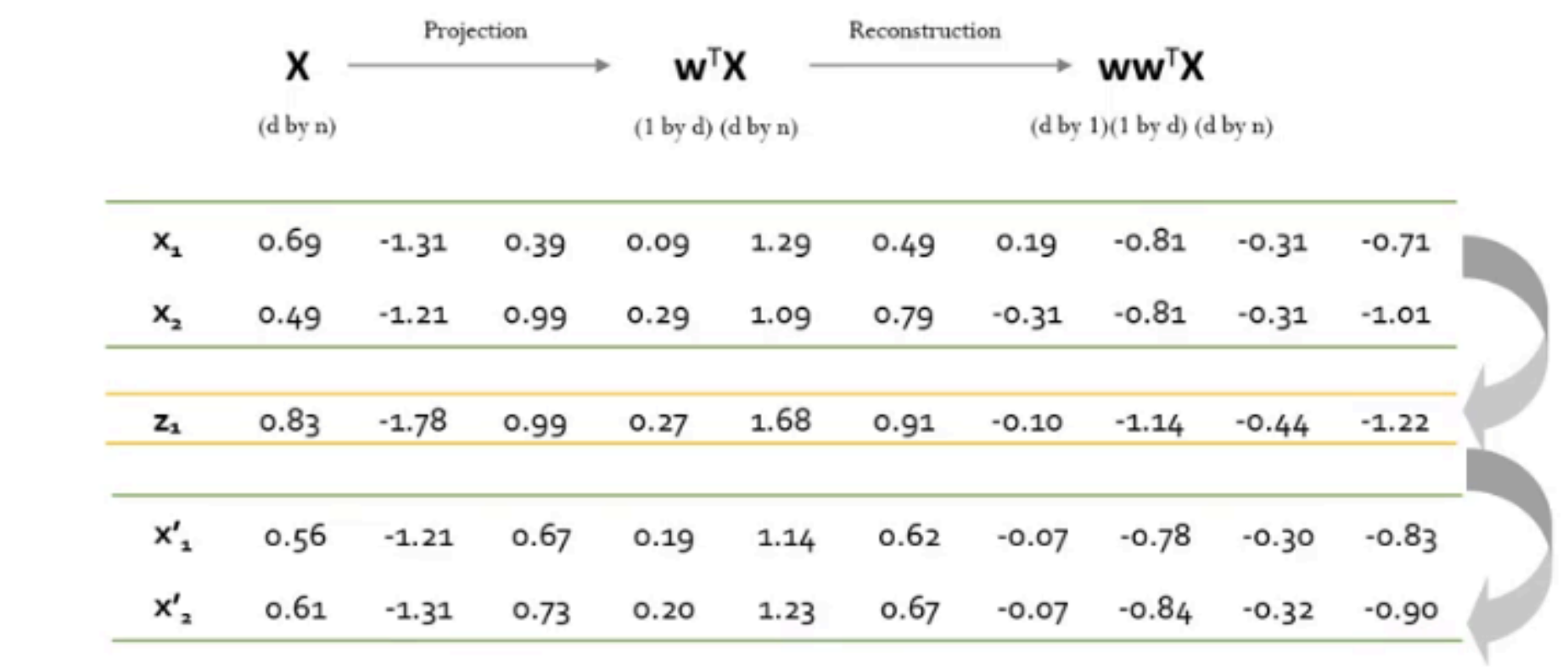
Step 6 : 원데이터로 복원
2D 데이터 → 1D PCA → 2D 데이터 복원(reconstruction)
4. 주성분 분석 이슈
(1) 주성분 개수 선정법 → 몇개의 주성분을 사용해야 할까?
선택 방법 #1
고유값 감소율이 유의미하게 낮아지는 Elbow Point에 해당하는 주성분을 선택
선택 방법 #2
일정 수준 이상의 분산 비를 보존하는 최소의 주성분을 선택 (보통 70% 이상)

몇개의 주성분을 사용해야 할까?
조건: 전체 분산의 80%를 포함해야 함
솔루션
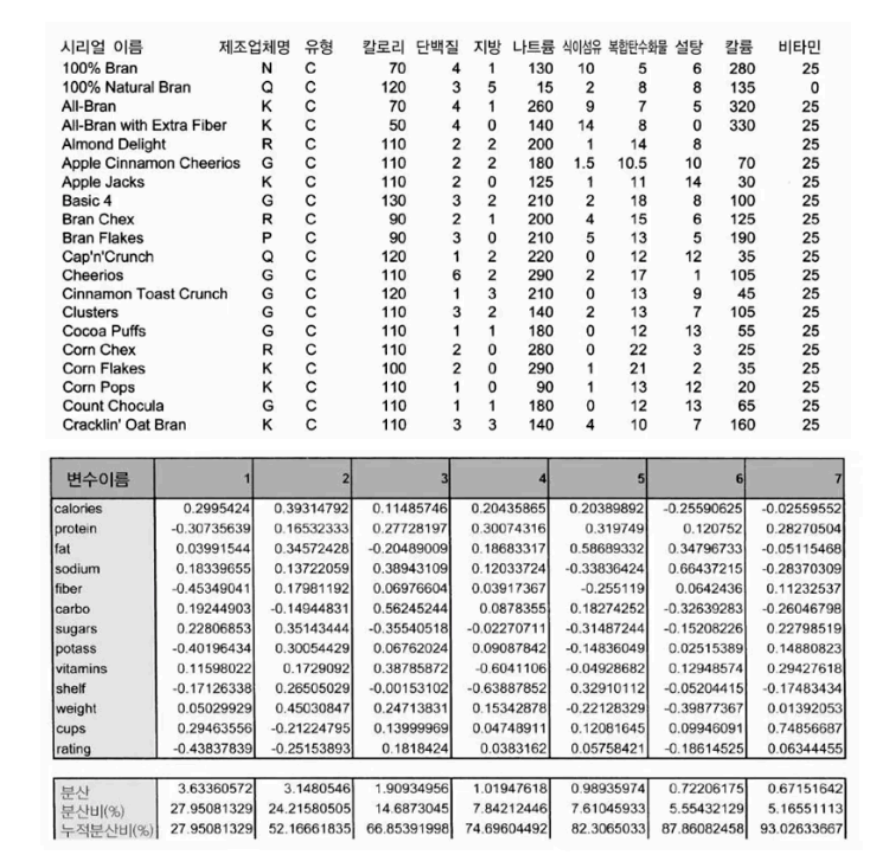
PCA결과의 누적분산비를 살펴보면 PC1~PC5까지 선택해야 전체 데이터 분산의 82%에 도달할 수 있음
5. 주성분 분석 한계
한계점 1
데이터 분포가 가우시안(non-gaussian)이 아니거나 다중 가우시안(multimodla-gaussian) 자료들에 대해서는 적용하기 어려움

한계점 2
분류 문제를 위해 디자인되지 않음, 즉 분류 성능 향상을 보장하지 못함

'Computer Science > Machine Learning' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) : 기타 (4) (0) | 2024.06.09 |
|---|---|
| 차원 축소(Dimension Reduction) : PCA (3) (0) | 2024.06.09 |
| 차원 축소(Dimension Reduction) (1) (0) | 2024.06.09 |
| 앙상블(Ensemble) [센서데이터를 이용한 행동분류] (2) (0) | 2024.06.09 |
| 앙상블(Ensemble) (1) (2) | 2024.06.09 |



