
1. 데이터 분석 과정
머신러닝을 이용한 데이터 분석 과정
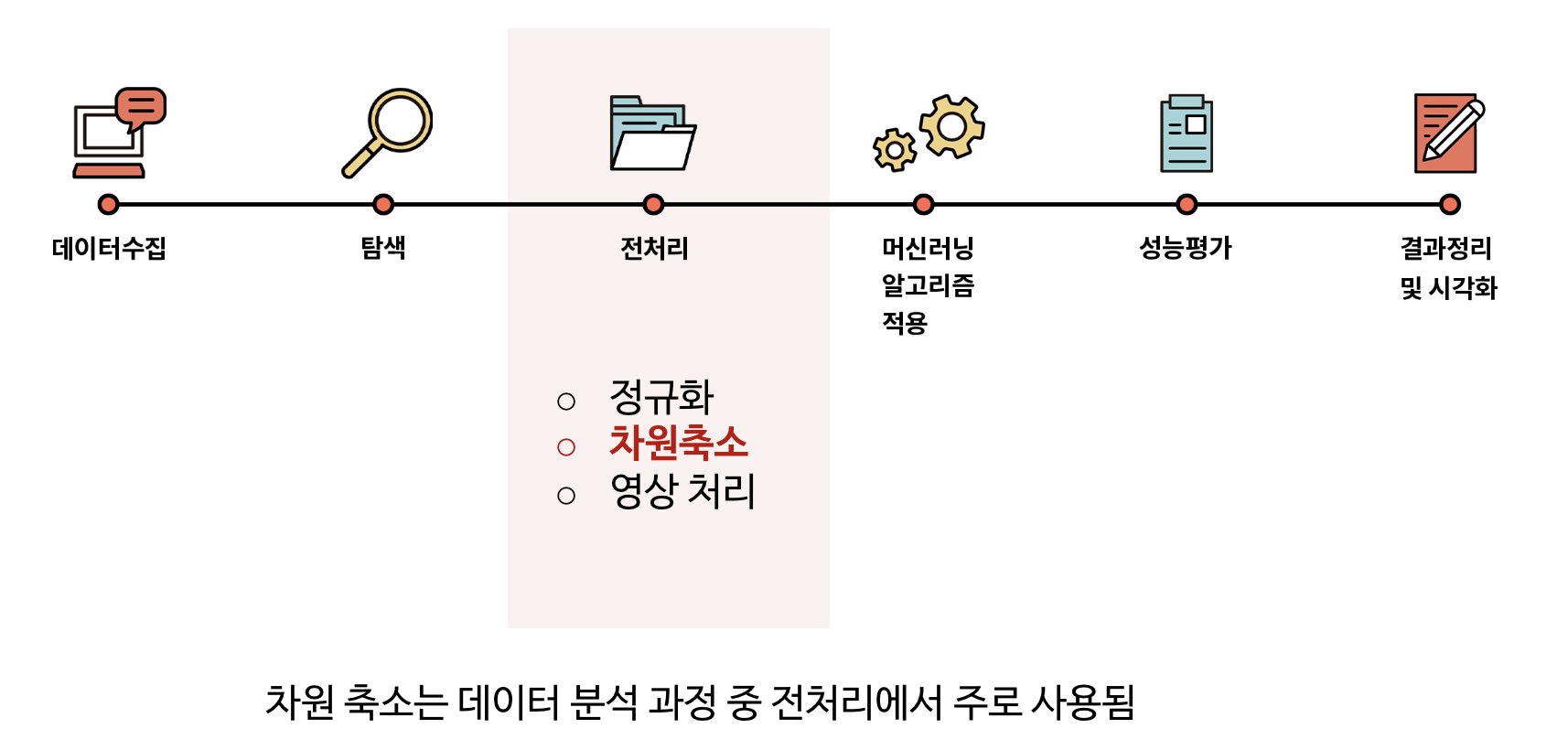
2. 차원 축소의 필요성
고차원 데이터(High dimensional data)의 예시
문서 요약
- 예) 한 문서의 크기 → 한 언어의 단어 수로 표현
- Billions of Documents * bag of words
추천 시스템
- 예) 사용자 * 총 영화 수 matrix 로 표현
- 480,189 users * 17,770 movie
유전자 군집화
- 예) 유전자 수 * 유전자의 컨디션
- 10,000 genes * 1,000 conditions
3. 차원의 축소 개요
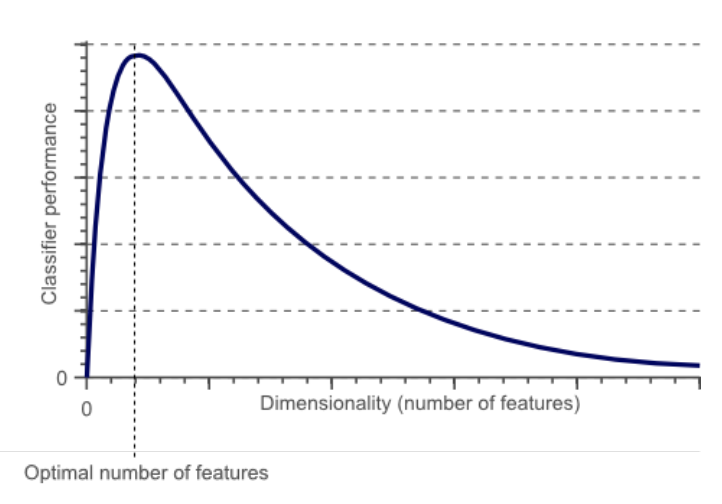
(1) 차원의 저주 (Curse of dimensionality)
차원이 증가할수록 동일 정보량을 표형하기 위해 필요한 데이터의 수는 지속적으로 증가한다는 의미
데이터 학습을 위해 차원이 증가하면서 학습 데이터의 수가 차원보다 적어져 모델의 성능이 저하되는 현상
데이터 차원이 증가할수록 개별 차원 내 학습할 데이터의 수가 적어지는 현상 발생
무조건 변수의 수가 증가한다고 해서 차원의 저주 문제가 있는 것은 아니며, 데이터의 수보다 변수의 수가 많아지면 발생 (데이터 200개, 변수 7000개)

일반적으로 intrinsic dimension은 original dimension 보다 상대적으로 작음
(예시)
- MNIST 16x16 (256 dimensions) 데이터
- IPCA와 ISOMAP을 통한 2차원 데이터로 차원 축소

차원이 높을수록 발생하는 문제
- 데이터에 포함될 노이즈의 비율도 높아짐 → 성능 저하 야기
- 모델 학습과 추론의 계산 복잡도가 놆아짐
- 동일한 성능을 얻기 위해 더 많은 데이터의 수가 필요함
차원의 저주 해결법
- 도메인 지식을 이용 → 중요한 특성만 사용
- 목적함수에 Regularization term 추가
- 차원 축소 기술을 전처리로 사용
(2) 차원 축소 배경
이론적으로, 차원의 증가는 모델의 성능을 향상시킴
- 가정 : 모든 변수가 서로 독립일 경우
실제로, 차원의 증가는 모델 성능 저하를 가져옴
- 모든 변수는 서로 상관 관계가 있고, 노이즈가 존재함
(3) 차원 축소의 목적
모델의 성능을 최대로 해주는 변수의 일부셋을 찾는 것
(4) 차원 축소의 효과
- 변수간 상관 관계(correlations) 처리
- 단순한 후처리(post-processing)
- 적절한 정보를 유지하면서 중복되거나 불필요한 변수를 제거
- 시각화 가능
(5) 지도학습 기반 차원 축소
학습 결과가 피드백 되어 Featrue Selection을 반복

(6) 비지도학습 기반 차원 축소
지도학습처럼 피드백을 통한 Feature Selection 반복 없음
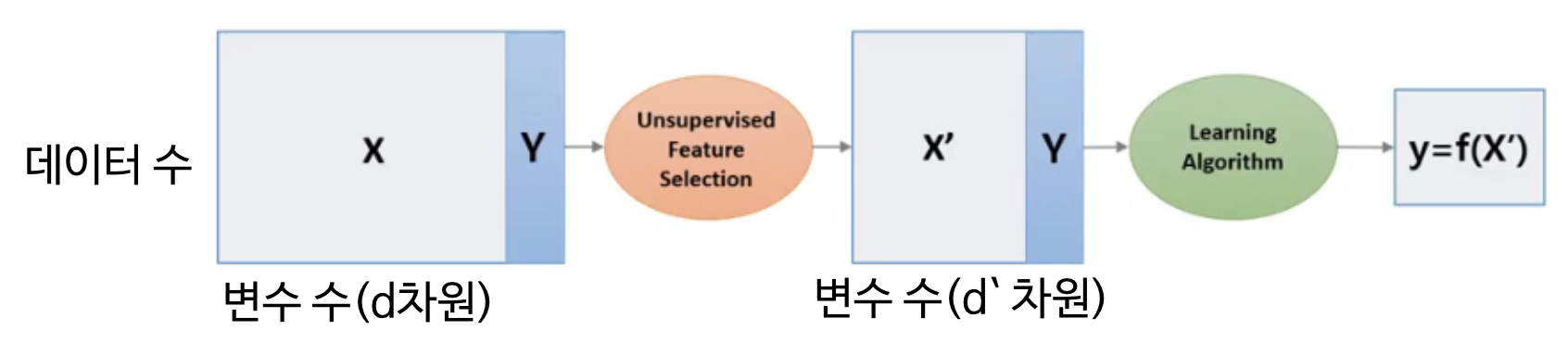
(7) 차원 축소 방법
변수/피쳐 선택 (Feature selection) : 유의미한 변수만 선택
- 장점: 선택한 변수 해석 용이
- 단점: 변수간 상관관계 고려의 어려움

변수/피쳐 추출 (Feature extraction) : 예측 변수의 변환을 통해 새로운 변수 추출
- 변수/피쳐 생성(Feature construction)
- 장점: 변수간 상관관계 고려, 변수의 개수를 많이 줄일 수 있음
- 단점: 추출된 변수의 해석이 어려움

'Computer Science > Machine Learning' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) : PCA (3) (0) | 2024.06.09 |
|---|---|
| 차원 축소(Dimension Reduction) : PCA (2) (0) | 2024.06.09 |
| 앙상블(Ensemble) [센서데이터를 이용한 행동분류] (2) (0) | 2024.06.09 |
| 앙상블(Ensemble) (1) (2) | 2024.06.09 |
| SVM 다계층 분류 (4) (0) | 2024.06.09 |



